Xie Yanping, Davis Lynn Brittny C, Moir Nicholas, Cameron David A, Figueroa Jonine D, Sims Andrew H
Applied Bioinformatics of Cancer, University of Edinburgh Cancer Research Centre, MRC Institute of Genetics and Molecular Medicine, Edinburgh, UK.
Usher Institute, University of Edinburgh, Edinburgh, UK.
NPJ Breast Cancer. 2020 Aug 25;6:39. doi: 10.1038/s41523-020-00180-x. eCollection 2020.
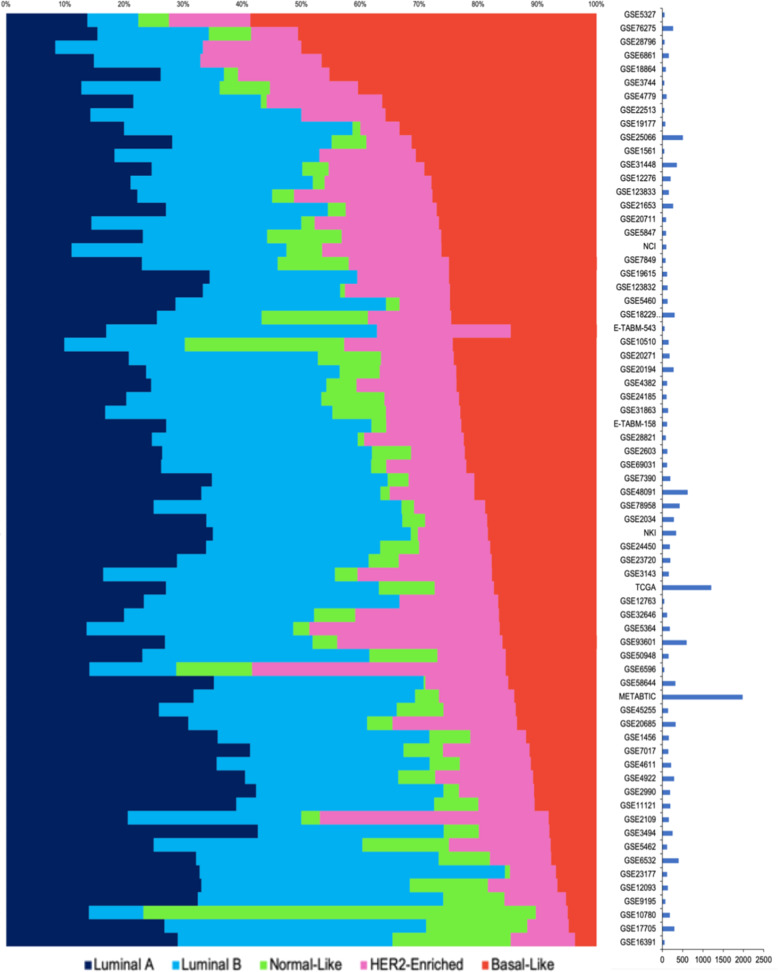
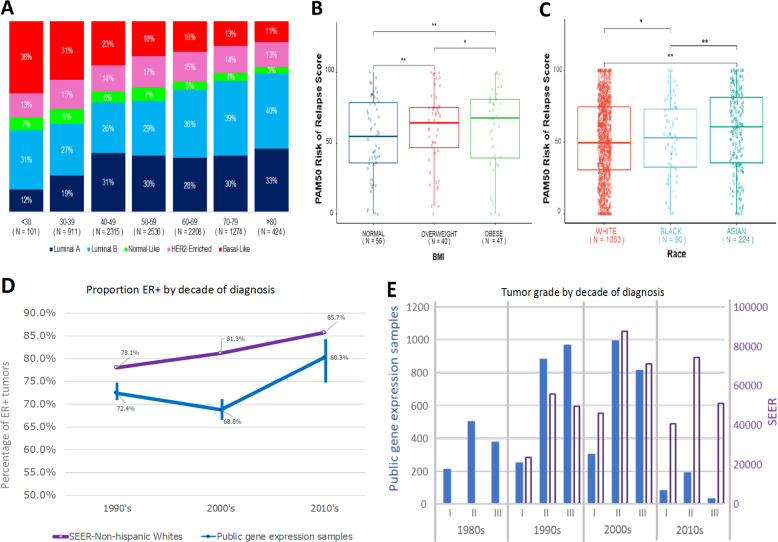
Publicly available tumor gene expression datasets are widely reanalyzed, but it is unclear how representative they are of clinical populations. Estimations of molecular subtype classification and prognostic gene signatures were calculated for 16,130 patients from 70 breast cancer datasets. Collated patient demographics and clinical characteristics were sparse for many studies. Considerable variations were observed in dataset size, patient/tumor characteristics, and molecular composition. Results were compared with Surveillance, Epidemiology, and End Results Program (SEER) figures. The proportion of basal subtype tumors ranged from 4 to 59%. Date of diagnosis ranged from 1977 to 2013, originating from 20 countries across five continents although European ancestry dominated. Publicly available breast cancer gene expression datasets are a great resource, but caution is required as they tend to be enriched for high grade, ER-negative tumors from European-ancestry patients. These results emphasize the need to derive more representative and annotated molecular datasets from diverse populations.
公开可用的肿瘤基因表达数据集被广泛重新分析,但它们对临床人群的代表性如何尚不清楚。对来自70个乳腺癌数据集的16130名患者计算了分子亚型分类和预后基因特征的估计值。许多研究中整理的患者人口统计学和临床特征很稀少。在数据集大小、患者/肿瘤特征和分子组成方面观察到相当大的差异。将结果与监测、流行病学和最终结果计划(SEER)的数据进行了比较。基底亚型肿瘤的比例从4%到59%不等。诊断日期从1977年到2013年,来自五大洲的20个国家,尽管欧洲血统占主导。公开可用的乳腺癌基因表达数据集是一个很好的资源,但需要谨慎,因为它们往往富集了来自欧洲血统患者的高级别、雌激素受体阴性肿瘤。这些结果强调了从不同人群中获得更具代表性和注释的分子数据集的必要性。