Harris School of Public Policy, University of Chicago, Chicago, Illinois.
Machine Learning Department, Carnegie Mellon University, Pittsburgh, Pennsylvania.
JAMA Netw Open. 2020 Sep 1;3(9):e2012734. doi: 10.1001/jamanetworkopen.2020.12734.
Childhood lead poisoning causes irreversible neurobehavioral deficits, but current practice is secondary prevention.
To validate a machine learning (random forest) prediction model of elevated blood lead levels (EBLLs) by comparison with a parsimonious logistic regression.
DESIGN, SETTING, AND PARTICIPANTS: This prognostic study for temporal validation of multivariable prediction models used data from the Women, Infants, and Children (WIC) program of the Chicago Department of Public Health. Participants included a development cohort of children born from January 1, 2007, to December 31, 2012, and a validation WIC cohort born from January 1 to December 31, 2013. Blood lead levels were measured until December 31, 2018. Data were analyzed from January 1 to October 31, 2019.
Blood lead level test results; lead investigation findings; housing characteristics, permits, and violations; and demographic variables.
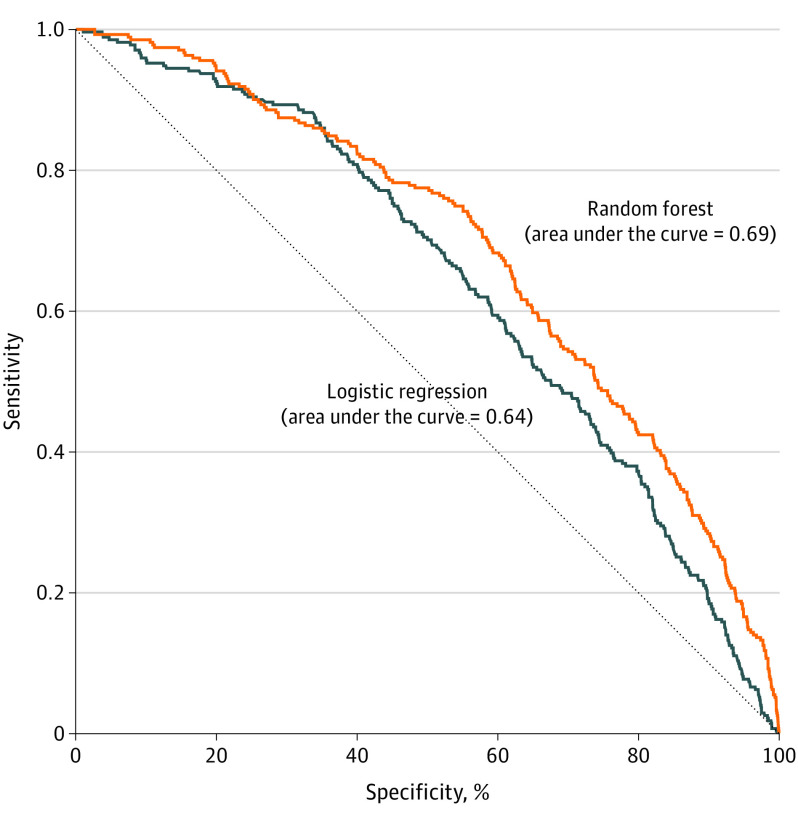
Incident EBLL (≥6 μg/dL). Models were assessed using the area under the receiver operating characteristic curve (AUC) and confusion matrix metrics (positive predictive value, sensitivity, and specificity) at various thresholds.
Among 6812 children in the WIC validation cohort, 3451 (50.7%) were female, 3057 (44.9%) were Hispanic, 2804 (41.2%) were non-Hispanic Black, 458 (6.7%) were non-Hispanic White, and 442 (6.5%) were Asian (mean [SD] age, 5.5 [0.3] years). The median year of housing construction was 1919 (interquartile range, 1903-1948). Random forest AUC was 0.69 compared with 0.64 for logistic regression (difference, 0.05; 95% CI, 0.02-0.08). When predicting the 5% of children at highest risk to have EBLLs, random forest and logistic regression models had positive predictive values of 15.5% and 7.8%, respectively (difference, 7.7%; 95% CI, 3.7%-11.3%), sensitivity of 16.2% and 8.1%, respectively (difference, 8.1%; 95% CI, 3.9%-11.7%), and specificity of 95.5% and 95.1% (difference, 0.4%; 95% CI, 0.0%-0.7%).
The machine learning model outperformed regression in predicting childhood lead poisoning, especially in identifying children at highest risk. Such a model could be used to target the allocation of lead poisoning prevention resources to these children.
儿童铅中毒会导致不可逆转的神经行为缺陷,但目前的做法是二级预防。
通过与简约逻辑回归进行比较,验证一种用于预测血铅水平升高(EBLL)的机器学习(随机森林)预测模型。
设计、地点和参与者:本研究为多变量预测模型的时间验证研究,使用了芝加哥公共卫生部妇女、婴儿和儿童(WIC)计划的数据。参与者包括一个 2007 年 1 月 1 日至 12 月 31 日出生的发育队列儿童和一个 2013 年 1 月 1 日至 12 月 31 日出生的验证 WIC 队列。血铅水平一直测量到 2018 年 12 月 31 日。数据分析时间为 2019 年 1 月 1 日至 10 月 31 日。
血铅检测结果;铅调查结果;住房特征、许可证和违规行为;以及人口统计学变量。
新发 EBLL(≥6μg/dL)。使用受试者工作特征曲线(ROC)下面积(AUC)和混淆矩阵指标(阳性预测值、敏感性和特异性)在不同阈值下评估模型。
在 WIC 验证队列的 6812 名儿童中,3451 名(50.7%)为女性,3057 名(44.9%)为西班牙裔,2804 名(41.2%)为非西班牙裔黑人,458 名(6.7%)为非西班牙裔白人,442 名(6.5%)为亚裔(平均[标准差]年龄为 5.5[0.3]岁)。房屋建筑的中位数年份为 1919 年(四分位间距,1903-1948)。随机森林 AUC 为 0.69,而逻辑回归为 0.64(差异,0.05;95%置信区间,0.02-0.08)。当预测 EBLL 风险最高的 5%儿童时,随机森林和逻辑回归模型的阳性预测值分别为 15.5%和 7.8%(差异,7.7%;95%置信区间,3.7%-11.3%),敏感性分别为 16.2%和 8.1%(差异,8.1%;95%置信区间,3.9%-11.7%),特异性分别为 95.5%和 95.1%(差异,0.4%;95%置信区间,0.0%-0.7%)。
机器学习模型在预测儿童铅中毒方面优于回归,尤其是在识别高风险儿童方面。这样的模型可以用于将铅中毒预防资源分配给这些儿童。