Sater Vincent, Viailly Pierre-Julien, Lecroq Thierry, Ruminy Philippe, Bérard Caroline, Prieur-Gaston Élise, Jardin Fabrice
University of Rouen Normandy UNIROUEN, LITIS EA 4108, 76000 Rouen, France.
INSERM U1245, University of Rouen Normandy UNIROUEN, 76000 Rouen, France.
Comput Struct Biotechnol J. 2020 Aug 27;18:2270-2280. doi: 10.1016/j.csbj.2020.08.011. eCollection 2020.
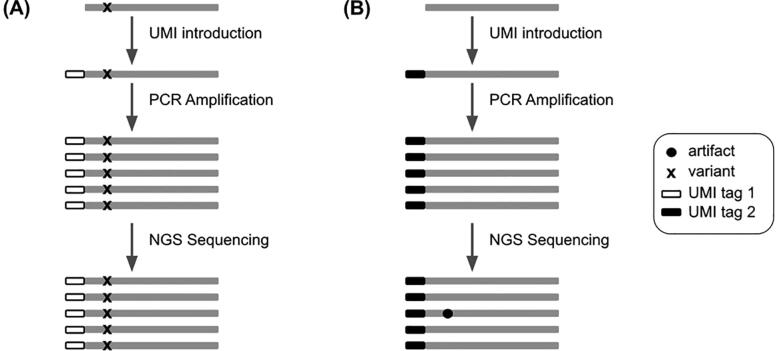
With Next Generation Sequencing becoming more affordable every year, NGS technologies asserted themselves as the fastest and most reliable way to detect Single Nucleotide Variants (SNV) and Copy Number Variations (CNV) in cancer patients. These technologies can be used to sequence DNA at very high depths thus allowing to detect abnormalities in tumor cells with very low frequencies. Multiple variant callers are publicly available and are usually efficient at calling out variants. However, when frequencies begin to drop under 1%, the specificity of these tools suffers greatly as true variants at very low frequencies can be easily confused with sequencing or PCR artifacts. The recent use of Unique Molecular Identifiers (UMI) in NGS experiments has offered a way to accurately separate true variants from artifacts. UMI-based variant callers are slowly replacing raw-read based variant callers as the standard method for an accurate detection of variants at very low frequencies. However, benchmarking done in the tools publication are usually realized on real biological data in which real variants are not known, making it difficult to assess their accuracy.
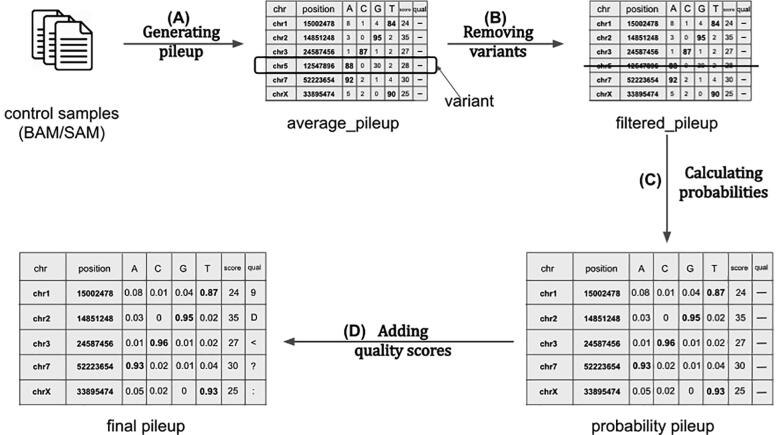
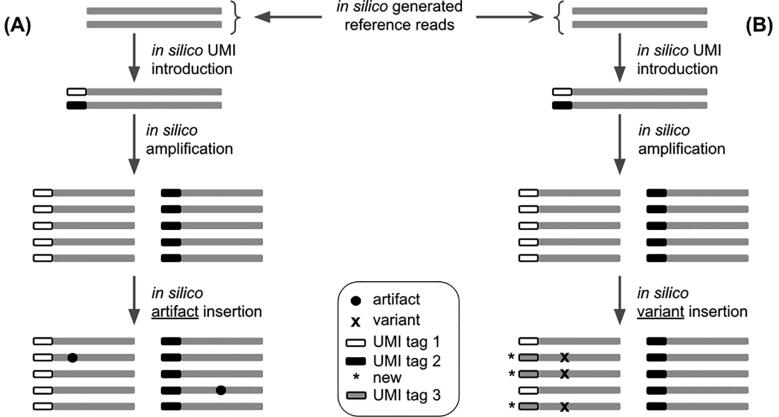
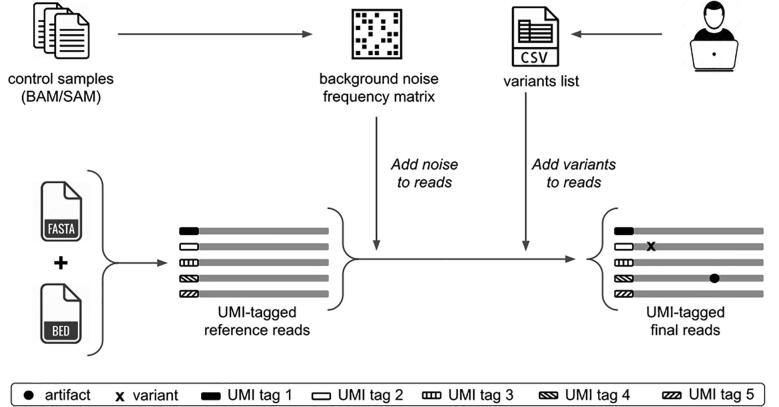
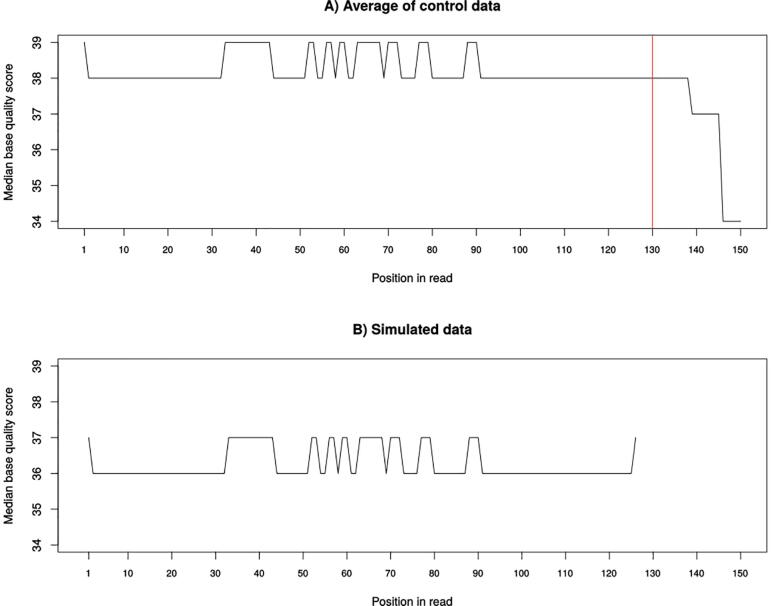
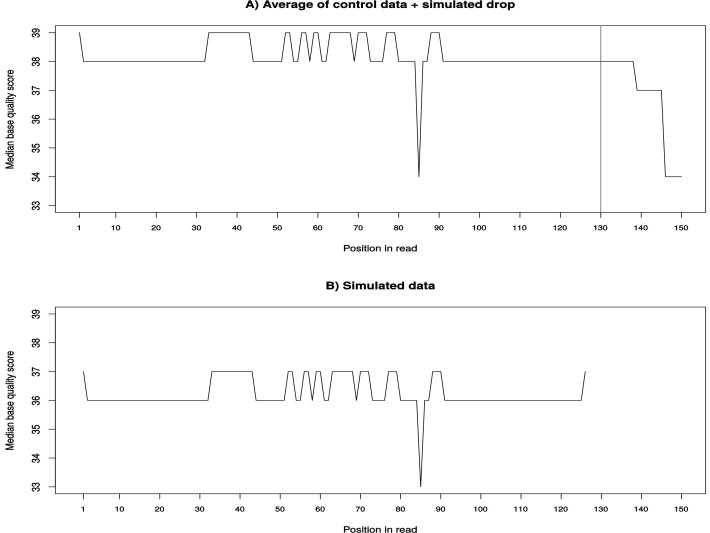
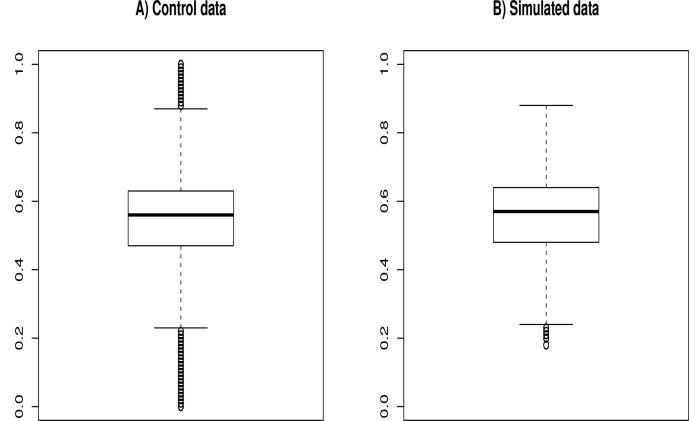
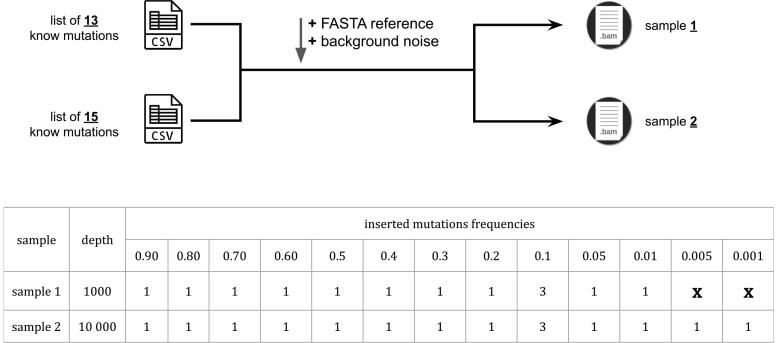
We present UMI-Gen, a UMI-based read simulator for targeted sequencing paired-end data. UMI-Gen generates reference reads covering the targeted regions at a user customizable depth. After that, using a number of control files, it estimates the background error rate at each position and then modifies the generated reads to mimic real biological data. Finally, it will insert real variants in the reads from a list provided by the user.
The entire pipeline is available at https://gitlab.com/vincent-sater/umigen under MIT license.
随着新一代测序技术的成本逐年降低,NGS技术已成为检测癌症患者单核苷酸变异(SNV)和拷贝数变异(CNV)的最快且最可靠的方法。这些技术可用于对DNA进行非常高深度的测序,从而能够检测出频率极低的肿瘤细胞异常。有多种变异检测工具可供公开使用,并且通常在检测变异方面效率很高。然而,当频率降至1%以下时,这些工具的特异性会大幅下降,因为极低频率的真实变异很容易与测序或PCR假象混淆。最近在NGS实验中使用独特分子标识符(UMI)提供了一种将真实变异与假象准确区分开来的方法。基于UMI的变异检测工具正逐渐取代基于原始读数的变异检测工具,成为在极低频率下准确检测变异的标准方法。然而,工具出版物中进行的基准测试通常是在真实生物数据上实现的,其中真实变异并不已知,这使得难以评估它们的准确性。
我们展示了UMI-Gen,一种用于靶向测序双端数据的基于UMI的读数模拟器。UMI-Gen以用户可定制的深度生成覆盖靶向区域的参考读数。之后,使用一些控制文件,它估计每个位置的背景错误率,然后修改生成的读数以模拟真实生物数据。最后,它会从用户提供的列表中在读数中插入真实变异。