Bhaduri Ritwik, Kundu Ritoban, Purkayastha Soumik, Kleinsasser Michael, Beesley Lauren J, Mukherjee Bhramar
Indian Statistical Institute Kolkata, India.
Indian Statistical Institute, Kolkata, India.
medRxiv. 2020 Sep 25:2020.09.24.20200238. doi: 10.1101/2020.09.24.20200238.
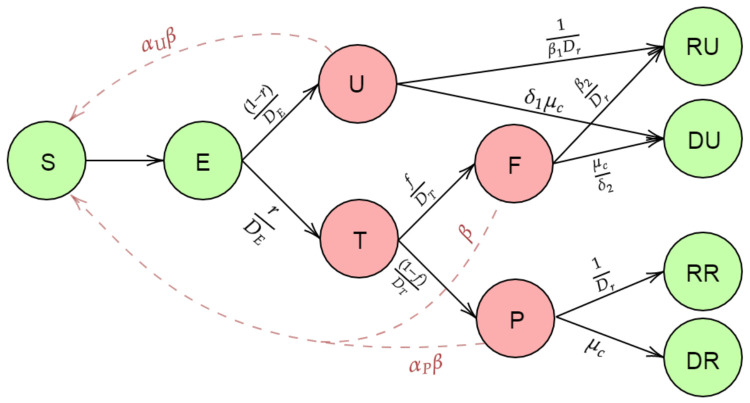
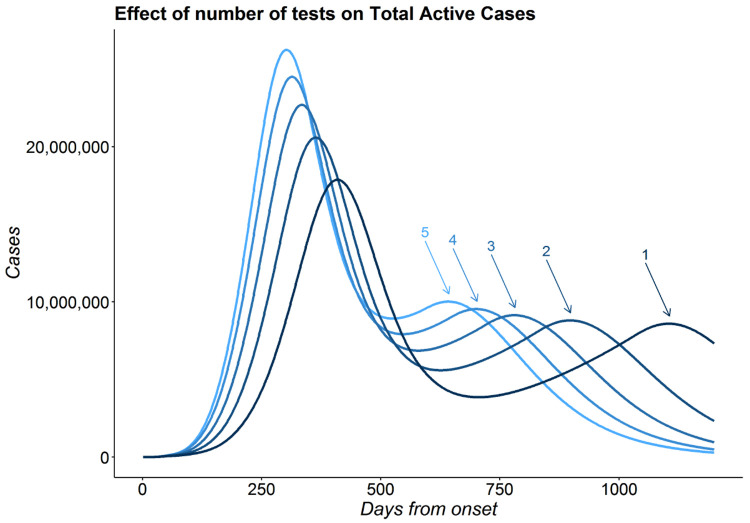
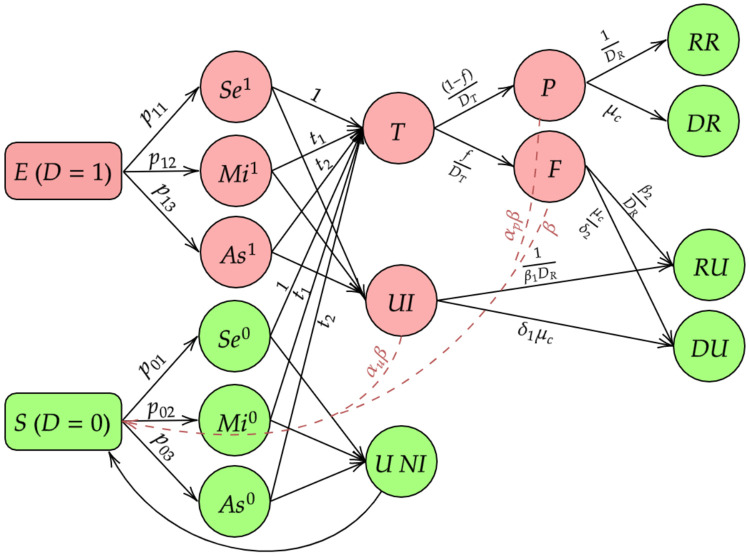
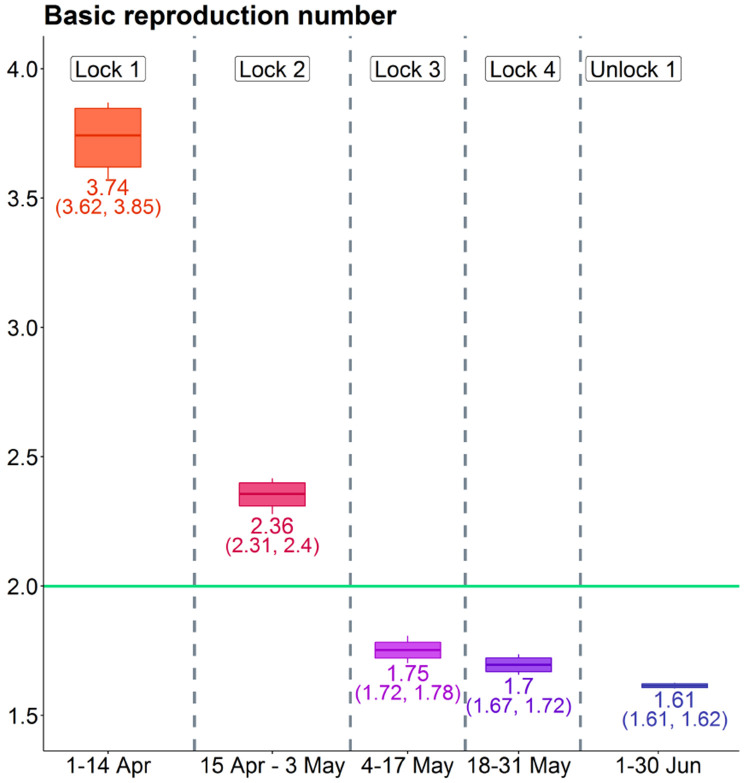
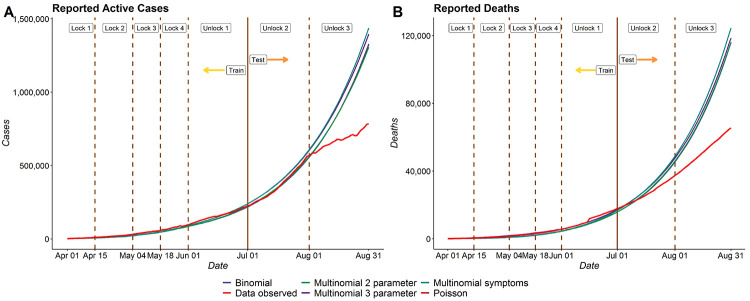
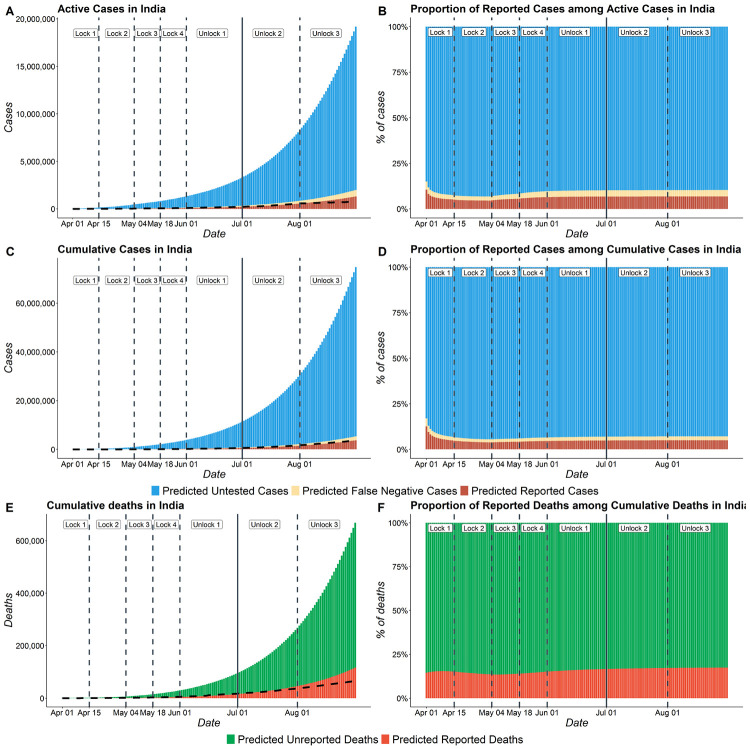
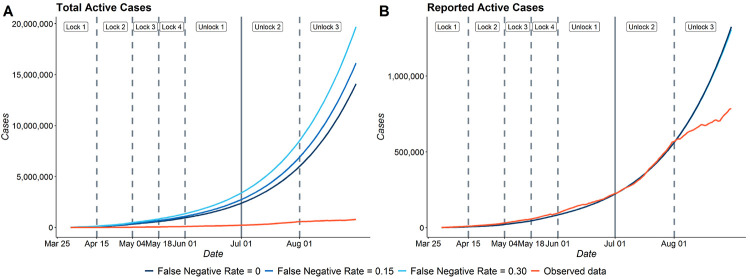
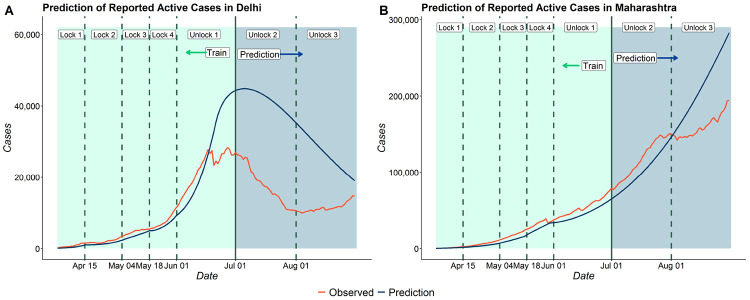
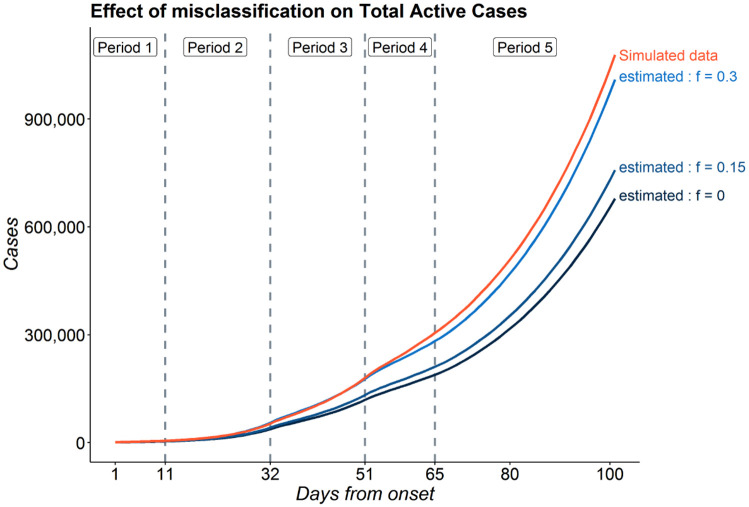
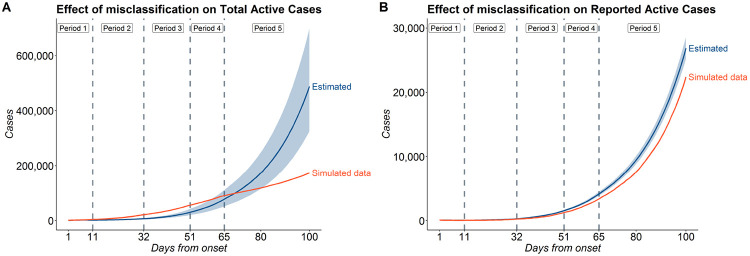
The false negative rate of the diagnostic RT-PCR test for SARS-CoV-2 has been reported to be substantially high. Due to limited availability of testing, only a non-random subset of the population can get tested. Hence, the reported test counts are subject to a large degree of selection bias. We consider an extension of the Susceptible-Exposed-Infected-Removed (SEIR) model under both selection bias and misclassification. We derive closed form expression for the basic reproduction number under such data anomalies using the next generation matrix method. We conduct extensive simulation studies to quantify the effect of misclassification and selection on the resultant estimation and prediction of future case counts. Finally we apply the methods to reported case-death-recovery count data from India, a nation with more than 5 million cases reported over the last seven months. We show that correcting for misclassification and selection can lead to more accurate prediction of case-counts (and death counts) using the observed data as a beta tester. The model also provides an estimate of undetected infections and thus an under-reporting factor. For India, the estimated under-reporting factor for cases is around 21 and for deaths is around 6. We develop an R-package (SEIRfansy) for broader dissemination of the methods.
据报道,用于检测严重急性呼吸综合征冠状病毒2(SARS-CoV-2)的诊断性逆转录聚合酶链反应(RT-PCR)检测的假阴性率相当高。由于检测资源有限,只有一部分非随机抽样的人群能够接受检测。因此,报告的检测数量存在很大程度的选择偏差。我们考虑了在选择偏差和错误分类情况下对易感-暴露-感染-康复(SEIR)模型的扩展。我们使用下一代矩阵方法,推导出了在这种数据异常情况下基本再生数的封闭形式表达式。我们进行了广泛的模拟研究,以量化错误分类和选择对未来病例数估计和预测结果的影响。最后,我们将这些方法应用于印度报告的病例-死亡-康复计数数据,在过去七个月里,印度报告的病例超过500万例。我们表明,通过校正错误分类和选择,可以利用观察到的数据作为测试版,更准确地预测病例数(和死亡数)。该模型还提供了未检测到的感染估计值,从而得到一个漏报因子。对于印度,病例的估计漏报因子约为21,死亡的估计漏报因子约为6。我们开发了一个R包(SEIRfansy),以便更广泛地传播这些方法。