Department of Statistics, Harvard University, Cambridge, Massachusetts, USA.
Department of Biostatistics, University of Michigan, Ann Arbor, Michigan, United States.
Stat Med. 2022 Jun 15;41(13):2317-2337. doi: 10.1002/sim.9357. Epub 2022 Feb 27.
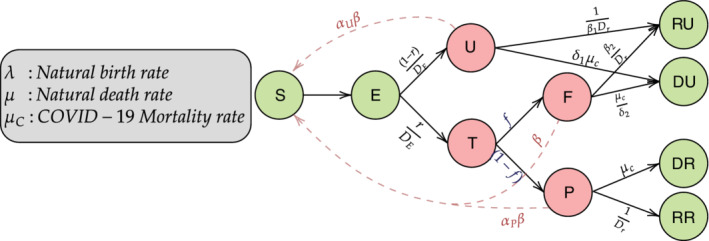
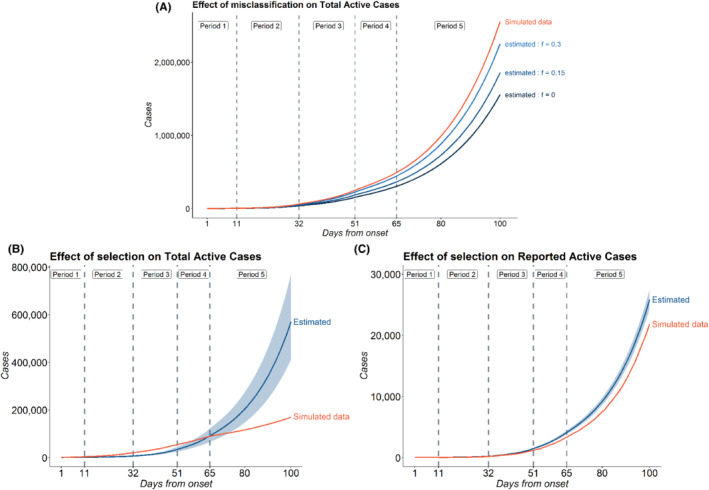
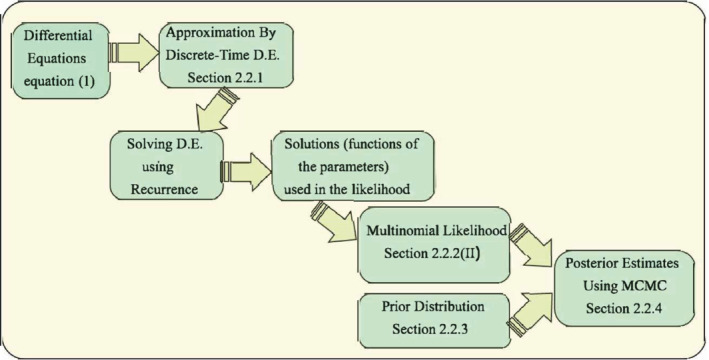
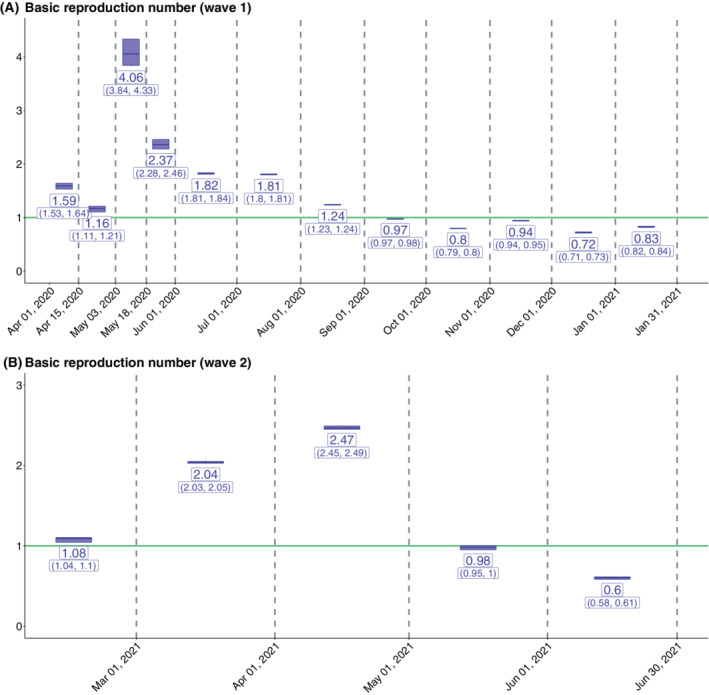
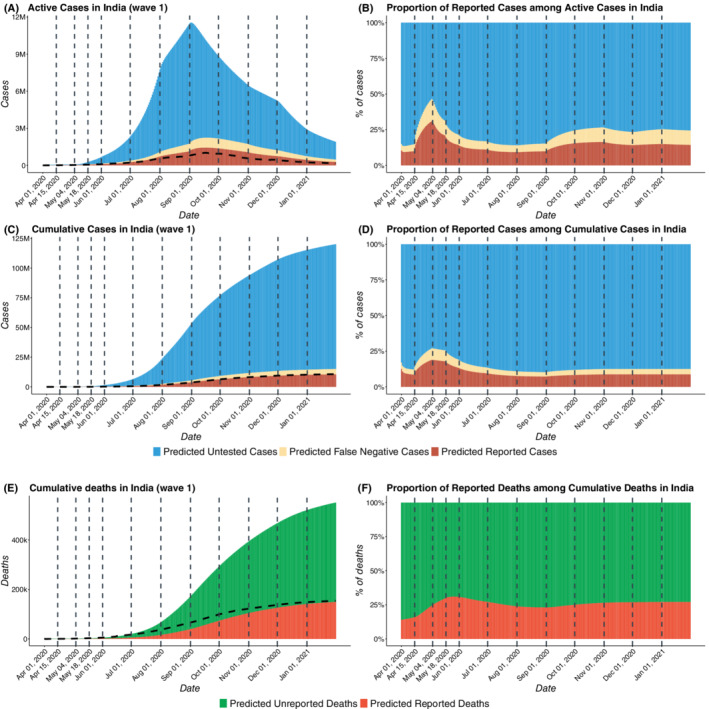
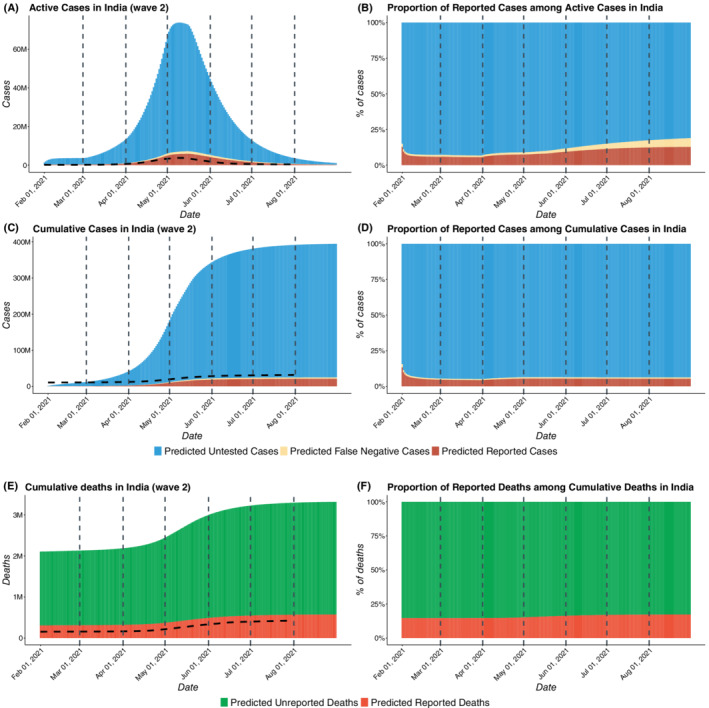
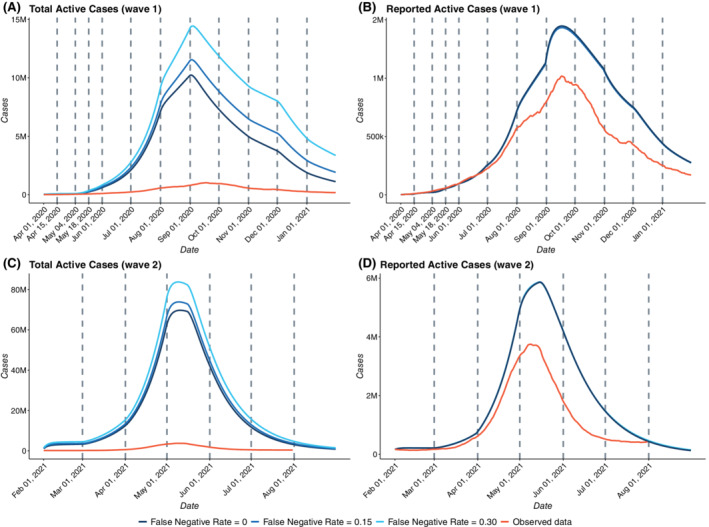
False negative rates of severe acute respiratory coronavirus 2 diagnostic tests, together with selection bias due to prioritized testing can result in inaccurate modeling of COVID-19 transmission dynamics based on reported "case" counts. We propose an extension of the widely used Susceptible-Exposed-Infected-Removed (SEIR) model that accounts for misclassification error and selection bias, and derive an analytic expression for the basic reproduction number as a function of false negative rates of the diagnostic tests and selection probabilities for getting tested. Analyzing data from the first two waves of the pandemic in India, we show that correcting for misclassification and selection leads to more accurate prediction in a test sample. We provide estimates of undetected infections and deaths between April 1, 2020 and August 31, 2021. At the end of the first wave in India, the estimated under-reporting factor for cases was at 11.1 (95% CI: 10.7,11.5) and for deaths at 3.58 (95% CI: 3.5,3.66) as of February 1, 2021, while they change to 19.2 (95% CI: 17.9, 19.9) and 4.55 (95% CI: 4.32, 4.68) as of July 1, 2021. Equivalently, 9.0% (95% CI: 8.7%, 9.3%) and 5.2% (95% CI: 5.0%, 5.6%) of total estimated infections were reported on these two dates, while 27.9% (95% CI: 27.3%, 28.6%) and 22% (95% CI: 21.4%, 23.1%) of estimated total deaths were reported. Extensive simulation studies demonstrate the effect of misclassification and selection on estimation of and prediction of future infections. A R-package SEIRfansy is developed for broader dissemination.
严重急性呼吸冠状病毒 2 诊断检测的假阴性率,加上由于优先检测而导致的选择偏差,可能会导致基于报告的“病例”数量对 COVID-19 传播动态进行不准确的建模。我们提出了一种广泛使用的易感-暴露-感染-清除(SEIR)模型的扩展,该模型考虑了分类错误和选择偏差,并推导出基本繁殖数作为诊断测试的假阴性率和检测选择概率的函数的解析表达式。分析印度大流行前两波的数据,我们表明,纠正分类错误和选择偏差可以在测试样本中进行更准确的预测。我们提供了 2020 年 4 月 1 日至 2021 年 8 月 31 日期间未检测到的感染和死亡的估计数。在印度第一波疫情结束时,截至 2021 年 2 月 1 日,病例的估计漏报因素为 11.1(95%置信区间:10.7,11.5),死亡的漏报因素为 3.58(95%置信区间:3.5,3.66),而到 2021 年 7 月 1 日,这些因素分别变为 19.2(95%置信区间:17.9,19.9)和 4.55(95%置信区间:4.32,4.68)。同样,在这两天报告的总估计感染中,9.0%(95%置信区间:8.7%,9.3%)和 5.2%(95%置信区间:5.0%,5.6%)是报告的,而 27.9%(95%置信区间:27.3%,28.6%)和 22%(95%置信区间:21.4%,23.1%)是报告的总死亡估计数。广泛的模拟研究表明了分类错误和选择对繁殖数估计和未来感染预测的影响。开发了一个用于更广泛传播的 R 包 SEIRfansy。