Department of Human Factors Engineering, Ulsan National Institute of Science and Technology, Ulsan 44919, Korea.
Sensors (Basel). 2020 Sep 29;20(19):5576. doi: 10.3390/s20195576.
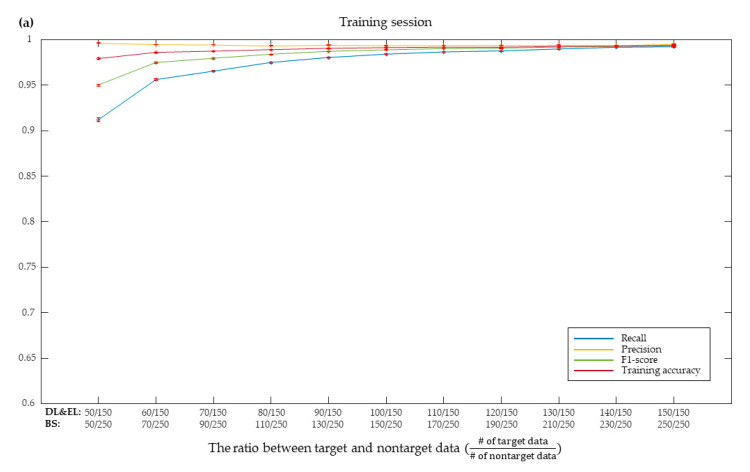
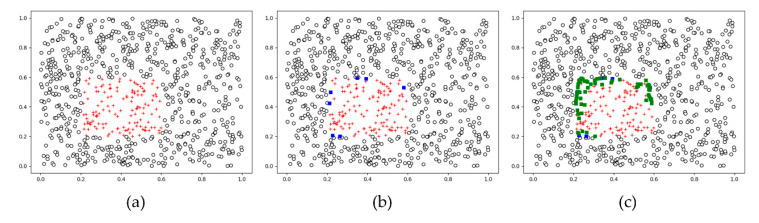
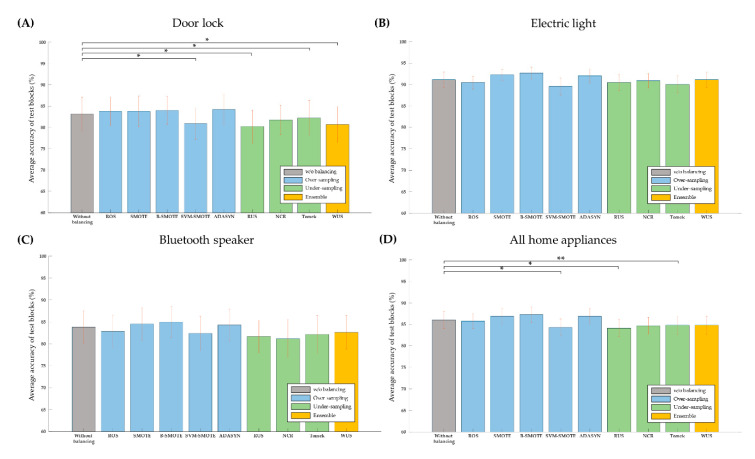
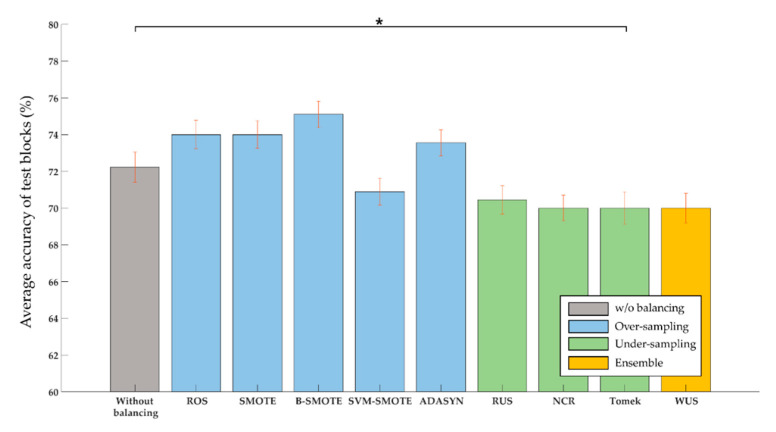
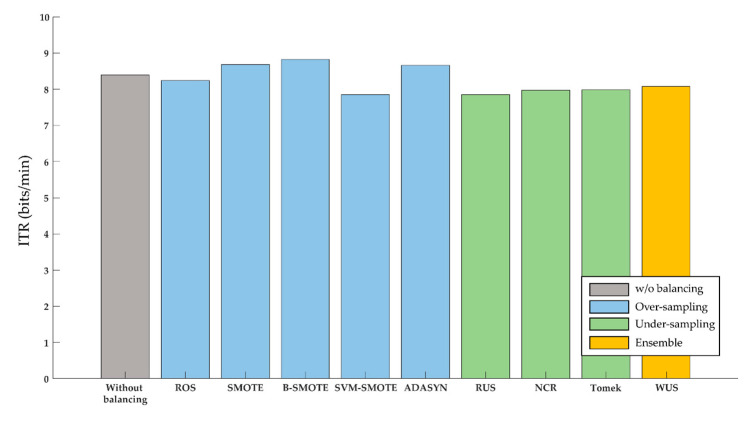
The oddball paradigm used in P300-based brain-computer interfaces (BCIs) intrinsically poses the issue of data imbalance between target stimuli and nontarget stimuli. Data imbalance can cause overfitting problems and, consequently, poor classification performance. The purpose of this study is to improve BCI performance by solving this data imbalance problem with sampling techniques. The sampling techniques were applied to BCI data in 15 subjects controlling a door lock, 15 subjects an electric light, and 14 subjects a Bluetooth speaker. We explored two categories of sampling techniques: oversampling and undersampling. Oversampling techniques, including random oversampling, synthetic minority oversampling technique (SMOTE), borderline-SMOTE, support vector machine (SVM) SMOTE, and adaptive synthetic sampling, were used to increase the number of samples for the class of target stimuli. Undersampling techniques, including random undersampling, neighborhood cleaning rule, Tomek's links, and weighted undersampling bagging, were used to reduce the class size of nontarget stimuli. The over- or undersampled data were classified by an SVM classifier. Overall, some oversampling techniques improved BCI performance while undersampling techniques often degraded performance. Particularly, using borderline-SMOTE yielded the highest accuracy (87.27%) and information transfer rate (8.82 bpm) across all three appliances. Moreover, borderline-SMOTE led to performance improvement, especially for poor performers. A further analysis showed that borderline-SMOTE improved SVM by generating more support vectors within the target class and enlarging margins. However, there was no difference in the accuracy between borderline-SMOTE and the method of applying the weighted regularization parameter of the SVM. Our results suggest that although oversampling improves performance of P300-based BCIs, it is not just the effect of the oversampling techniques, but rather the effect of solving the data imbalance problem.
基于 P300 的脑机接口(BCI)中使用的奇异范例本质上存在目标刺激与非目标刺激之间的数据不平衡问题。数据不平衡会导致过拟合问题,从而导致分类性能不佳。本研究的目的是通过使用采样技术解决这个数据不平衡问题来提高 BCI 的性能。采样技术应用于 15 名控制门锁的受试者、15 名控制电灯的受试者和 14 名控制蓝牙音箱的受试者的 BCI 数据。我们探索了两种采样技术类别:过采样和欠采样。过采样技术包括随机过采样、合成少数类过采样技术(SMOTE)、边界 SMOTE、支持向量机(SVM)SMOTE 和自适应合成采样,用于增加目标刺激类的样本数量。欠采样技术包括随机欠采样、邻域清理规则、Tomek 链接和加权欠采样袋装,用于减少非目标刺激的类大小。过采样或欠采样数据由 SVM 分类器分类。总体而言,一些过采样技术提高了 BCI 的性能,而欠采样技术往往会降低性能。特别是,使用边界 SMOTE 在所有三种设备中产生了最高的准确率(87.27%)和信息传输率(8.82 bpm)。此外,边界 SMOTE 导致性能提高,特别是对于表现不佳的人。进一步的分析表明,边界 SMOTE 通过在目标类中生成更多的支持向量并扩大边界来改善 SVM。然而,在准确率方面,边界 SMOTE 与应用 SVM 加权正则化参数的方法没有区别。我们的结果表明,尽管过采样提高了基于 P300 的 BCI 的性能,但这不仅仅是过采样技术的效果,而是解决数据不平衡问题的效果。