The John Bingham Laboratory, NIAB, Cambridge, United Kingdom.
IMplant Consultancy Ltd., Chelmsford, United Kingdom.
Plant Genome. 2020 Mar;13(1):e20004. doi: 10.1002/tpg2.20004. Epub 2020 Mar 17.
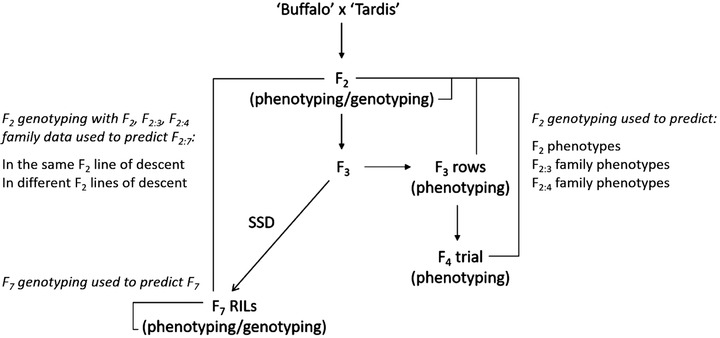
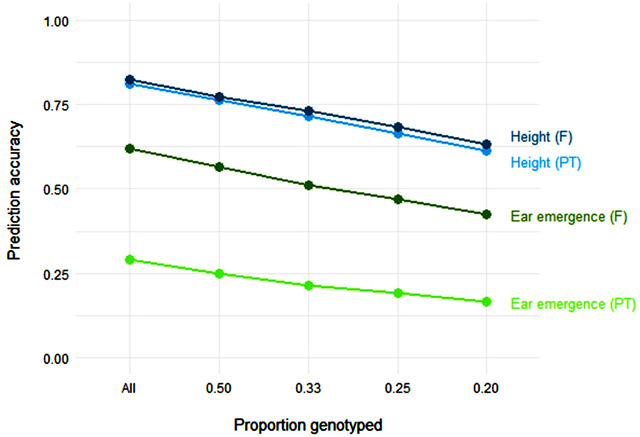
A barrier to the adoption of genomic prediction in small breeding programs is the initial cost of genotyping material. Although decreasing, marker costs are usually higher than field trial costs. In this study we demonstrate the utility of stratifying a narrow-base biparental oat population genotyped with a modest number of markers to employ genomic prediction at early and later generations. We also show that early generation genotyping data can reduce the number of lines for later phenotyping based on selections of siblings to progress. Using sets of small families selected at an early generation could enable the use of genomic prediction for adaptation to multiple target environments at an early stage in the breeding program. In addition, we demonstrate that mixed marker data can be effectively integrated to combine cheap dominant marker data (including legacy data) with more expensive but higher density codominant marker data in order to make within generation and between lineage predictions based on genotypic information. Taken together, our results indicate that small programs can test and initiate genomic predictions using sets of stratified, narrow-base populations and incorporating low density legacy genotyping data. This can then be scaled to include higher density markers and a broadened population base.
采用基因组预测在小型育种计划中的一个障碍是基因型材料的初始成本。尽管有所下降,但标记成本通常高于田间试验成本。在这项研究中,我们展示了将一个用少量标记进行基因分型的狭窄基础双亲燕麦群体分层的实用性,以在早期和后期世代中利用基因组预测。我们还表明,早期世代的基因分型数据可以根据兄弟姐妹的选择来减少后期表型测定的行数,从而推进研究。在育种计划的早期阶段,使用早期世代选择的小家庭集可以实现对多个目标环境的适应性的基因组预测。此外,我们证明了混合标记数据可以有效地整合,以将廉价的显性标记数据(包括遗留数据)与更昂贵但更高密度的共显性标记数据结合起来,以便根据基因型信息进行代内和谱系间预测。总之,我们的研究结果表明,小型计划可以使用分层的、基础狭窄的群体集和包含低密度遗传标记数据来测试和启动基因组预测。然后可以将其扩展到包括更高密度的标记和更广泛的群体基础。