Plant Breeding and Genetics, Cornell University, Ithaca, NY, United States of America.
Boyce Thompson Institute, Ithaca, NY, United States of America.
PLoS One. 2020 Nov 11;15(11):e0240059. doi: 10.1371/journal.pone.0240059. eCollection 2020.
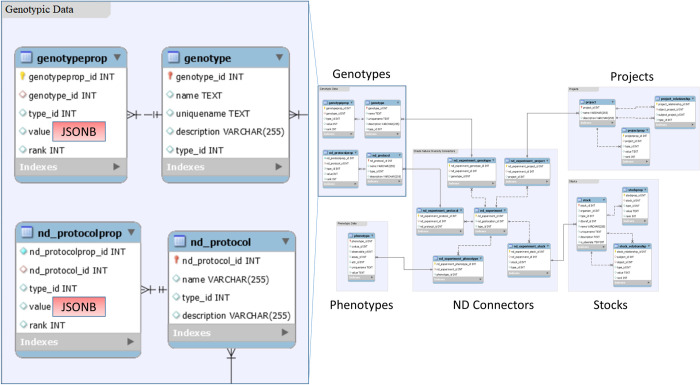
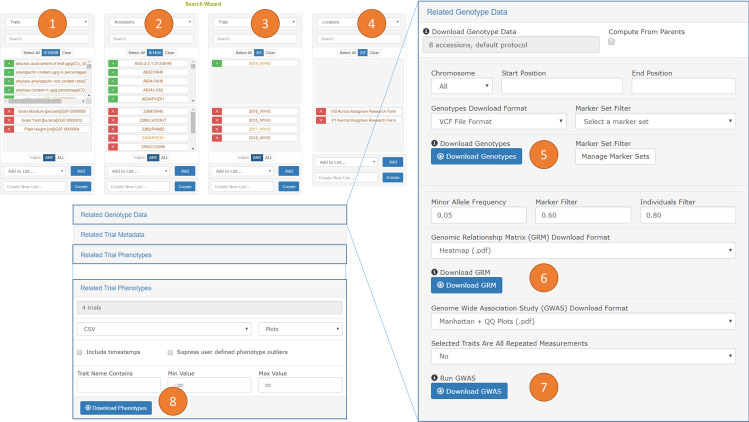
Modern breeding programs routinely use genome-wide information for selecting individuals to advance. The large volumes of genotypic information required present a challenge for data storage and query efficiency. Major use cases require genotyping data to be linked with trait phenotyping data. In contrast to phenotyping data that are often stored in relational database schemas, next-generation genotyping data are traditionally stored in non-relational storage systems due to their extremely large scope. This study presents a novel data model implemented in Breedbase (https://breedbase.org/) for uniting relational phenotyping data and non-relational genotyping data within the open-source PostgreSQL database engine. Breedbase is an open-source, web-database designed to manage all of a breeder's informatics needs: management of field experiments, phenotypic and genotypic data collection and storage, and statistical analyses. The genotyping data is stored in a PostgreSQL data-type known as binary JavaScript Object Notation (JSONb), where the JSON structures closely follow the Variant Call Format (VCF) data model. The Breedbase genotyping data model can handle different ploidy levels, structural variants, and any genotype encoded in VCF. JSONb is both compressed and indexed, resulting in a space and time efficient system. Furthermore, file caching maximizes data retrieval performance. Integration of all breeding data within the Chado database schema retains referential integrity that may be lost when genotyping and phenotyping data are stored in separate systems. Benchmarking demonstrates that the system is fast enough for computation of a genomic relationship matrix (GRM) and genome wide association study (GWAS) for datasets involving 1,325 diploid Zea mays, 314 triploid Musa acuminata, and 924 diploid Manihot esculenta samples genotyped with 955,690, 142,119, and 287,952 genotype-by-sequencing (GBS) markers, respectively.
现代育种计划通常使用全基因组信息来选择个体进行推广。大量的基因型信息需要存储和查询效率的挑战。主要用例需要将基因型数据与表型数据进行链接。与通常存储在关系数据库模式中的表型数据不同,由于下一代基因型数据的范围非常大,因此传统上存储在非关系存储系统中。本研究提出了一种新颖的数据模型,该模型在 Breedbase(https://breedbase.org/)中实现,用于在开源 PostgreSQL 数据库引擎中统一关系型表型数据和非关系型基因型数据。Breedbase 是一个开源的、基于 Web 的数据库,旨在管理所有育种者的信息学需求:田间试验管理、表型和基因型数据收集和存储以及统计分析。基因型数据存储在 PostgreSQL 数据类型中,称为二进制 JavaScript 对象表示法(JSONb),其中 JSON 结构紧密遵循变体调用格式(VCF)数据模型。Breedbase 基因型数据模型可以处理不同的倍性水平、结构变体和任何以 VCF 编码的基因型。JSONb 既压缩又索引,因此系统具有空间和时间效率。此外,文件缓存最大化了数据检索性能。在 Chado 数据库模式中集成所有育种数据保留了参照完整性,当基因型和表型数据存储在单独的系统中时,这种完整性可能会丢失。基准测试表明,该系统足够快,可以计算基因组关系矩阵(GRM)和全基因组关联研究(GWAS),涉及 1325 个二倍体玉米、314 个三倍体香蕉和 924 个二倍体木薯,分别用 955690、142119 和 287952 个基因型测序(GBS)标记进行基因型。