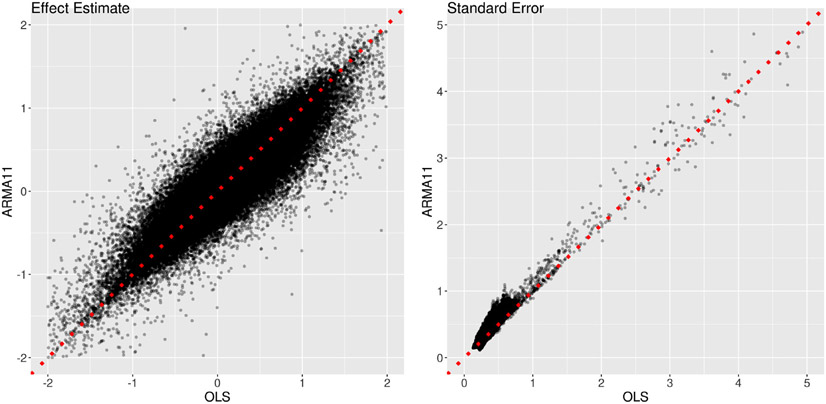
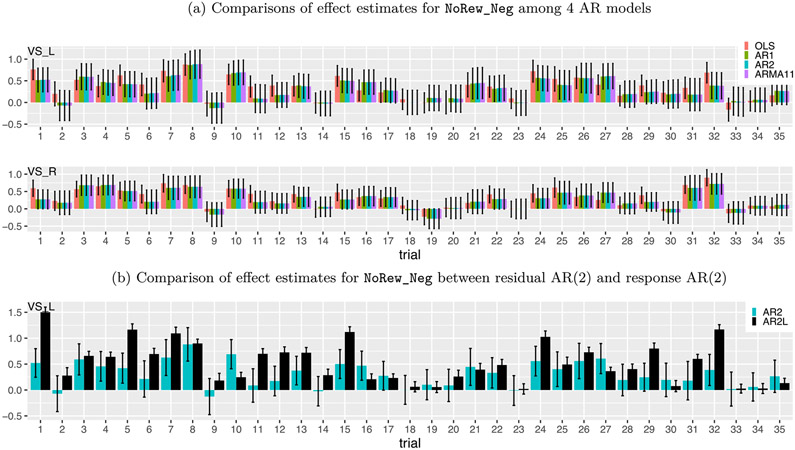
Chen Gang, Padmala Srikanth, Chen Yi, Taylor Paul A, Cox Robert W, Pessoa Luiz
Scientific and Statistical Computing Core, NIMH, National Institutes of Health, USA.
Centre for Neuroscience, Indian Institute of Science, Bangalore, India.
Neuroimage. 2021 Jan 15;225:117496. doi: 10.1016/j.neuroimage.2020.117496. Epub 2020 Oct 24.
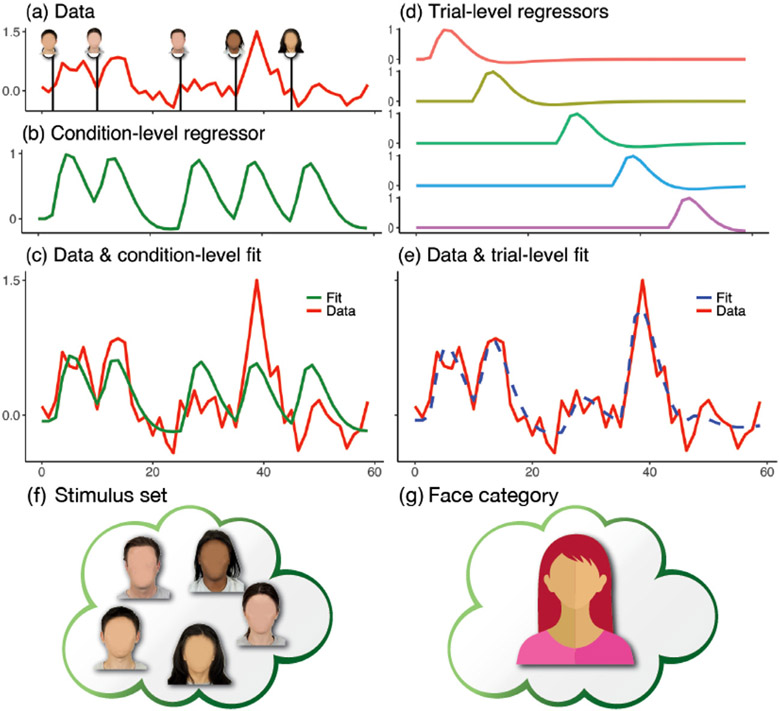
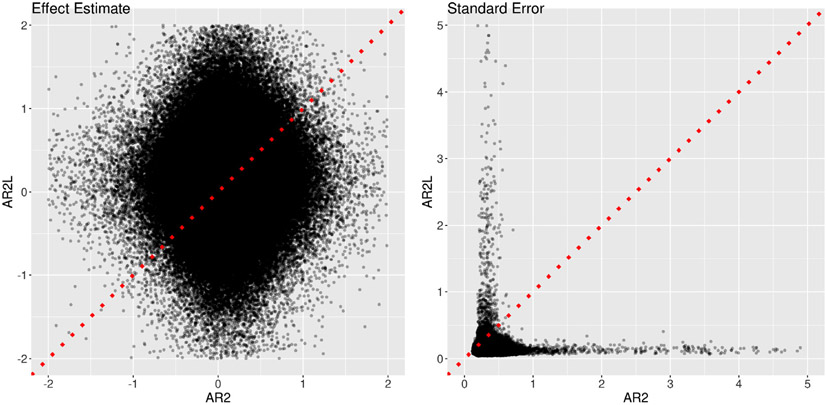
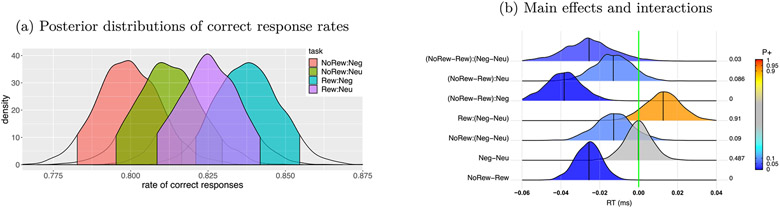
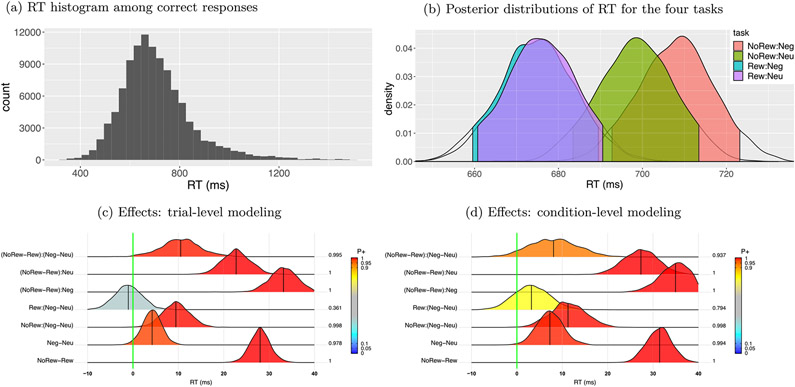
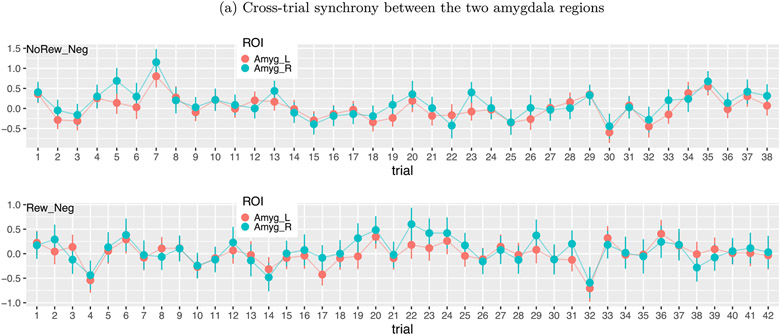
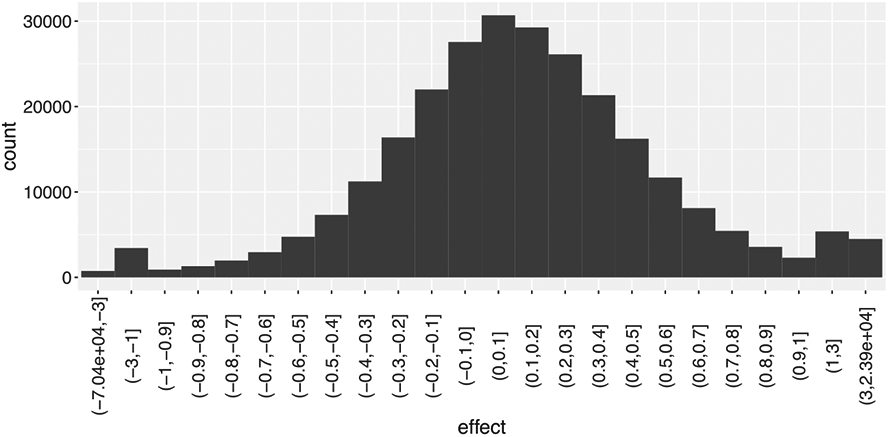
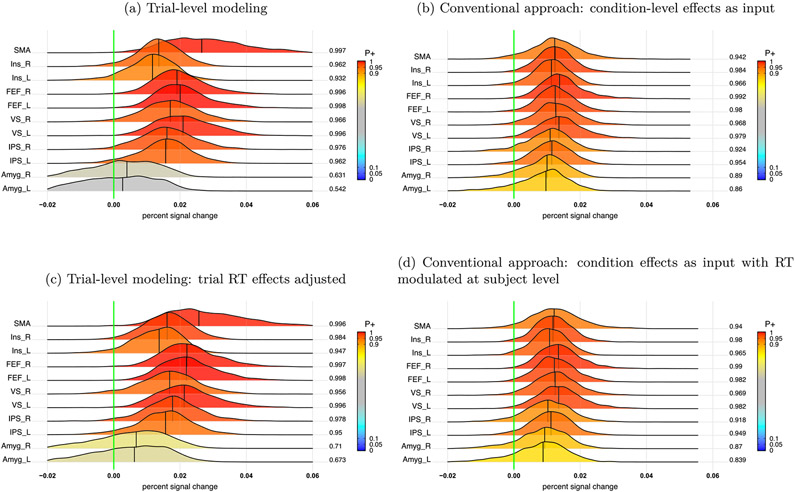
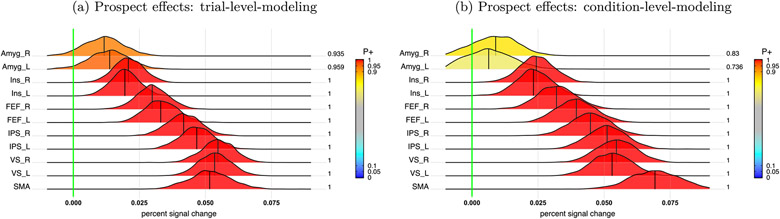
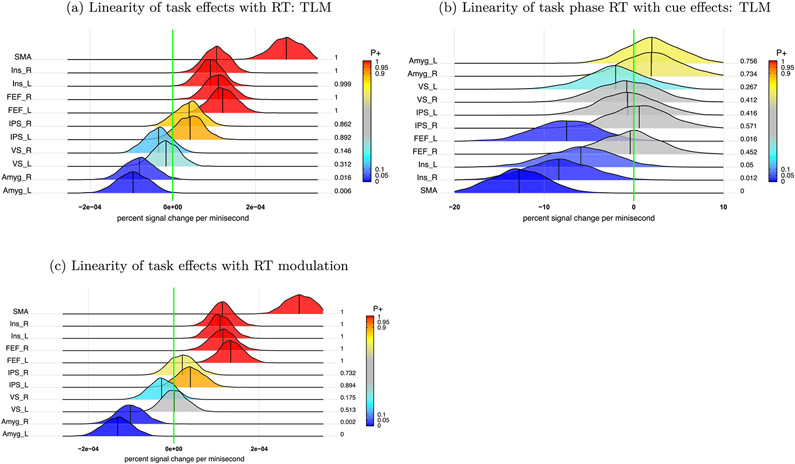
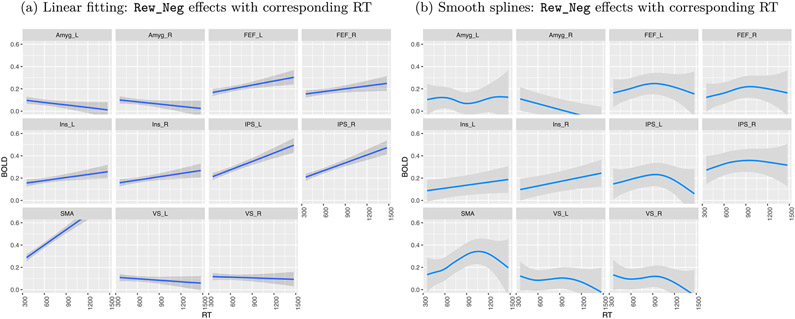
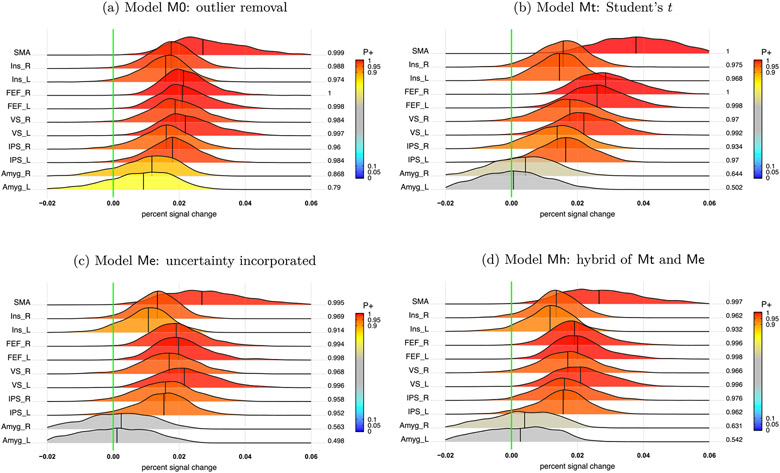
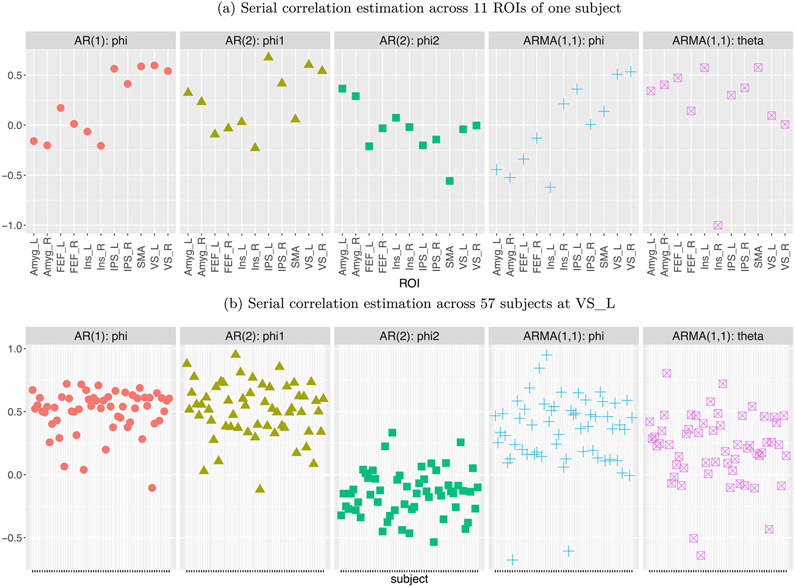
In this work, we investigate the importance of explicitly accounting for cross-trial variability in neuroimaging data analysis. To attempt to obtain reliable estimates in a task-based experiment, each condition is usually repeated across many trials. The investigator may be interested in (a) condition-level effects, (b) trial-level effects, or (c) the association of trial-level effects with the corresponding behavior data. The typical strategy for condition-level modeling is to create one regressor per condition at the subject level with the underlying assumption that responses do not change across trials. In this methodology of complete pooling, all cross-trial variability is ignored and dismissed as random noise that is swept under the rug of model residuals. Unfortunately, this framework invalidates the generalizability from the confine of specific trials (e.g., particular faces) to the associated stimulus category ("face"), and may inflate the statistical evidence when the trial sample size is not large enough. Here we propose an adaptive and computationally tractable framework that meshes well with the current two-level pipeline and explicitly accounts for trial-by-trial variability. The trial-level effects are first estimated per subject through no pooling. To allow generalizing beyond the particular stimulus set employed, the cross-trial variability is modeled at the population level through partial pooling in a multilevel model, which permits accurate effect estimation and characterization. Alternatively, trial-level estimates can be used to investigate, for example, brain-behavior associations or correlations between brain regions. Furthermore, our approach allows appropriate accounting for serial correlation, handling outliers, adapting to data skew, and capturing nonlinear brain-behavior relationships. By applying a Bayesian multilevel model framework at the level of regions of interest to an experimental dataset, we show how multiple testing can be addressed and full results reported without arbitrary dichotomization. Our approach revealed important differences compared to the conventional method at the condition level, including how the latter can distort effect magnitude and precision. Notably, in some cases our approach led to increased statistical sensitivity. In summary, our proposed framework provides an effective strategy to capture trial-by-trial responses that should be of interest to a wide community of experimentalists.
在这项工作中,我们研究了在神经影像数据分析中明确考虑跨试验变异性的重要性。为了在基于任务的实验中获得可靠的估计值,每个条件通常会在多个试验中重复。研究者可能对以下方面感兴趣:(a) 条件水平效应;(b) 试验水平效应;或 (c) 试验水平效应与相应行为数据的关联。条件水平建模的典型策略是在个体水平上为每个条件创建一个回归变量,其潜在假设是反应在不同试验中不会改变。在这种完全合并的方法中,所有跨试验变异性都被忽略,并被视为随机噪声而被归入模型残差之中。不幸的是,这个框架使得从特定试验(例如特定面孔)的范围到相关刺激类别(“面孔”)的可推广性无效,并且当试验样本量不够大时可能会夸大统计证据。在此,我们提出了一个适应性强且计算上易于处理的框架,它与当前的两级流程配合良好,并明确考虑了逐次试验的变异性。首先通过不合并的方式为每个个体估计试验水平效应。为了能够推广到所使用的特定刺激集之外,通过在多层次模型中进行部分合并,在总体水平上对跨试验变异性进行建模,这允许进行准确的效应估计和特征描述。或者,试验水平估计值可用于研究,例如脑 - 行为关联或脑区之间的相关性。此外,我们的方法允许适当地考虑序列相关性、处理异常值、适应数据偏态以及捕捉非线性脑 - 行为关系。通过将感兴趣区域水平的贝叶斯多层次模型框架应用于一个实验数据集,我们展示了如何解决多重检验问题并报告完整结果而无需进行任意二分法处理。与传统方法在条件水平上相比,我们的方法揭示了重要差异,包括后者如何扭曲效应大小和精度。值得注意的是,在某些情况下,我们的方法提高了统计灵敏度。总之,我们提出的框架提供了一种有效的策略来捕捉逐次试验的反应,这应该会引起广大实验人员的兴趣。