Iyer Gayatri R, Wigginton Janis, Duren William, LaBarre Jennifer L, Brandenburg Marci, Burant Charles, Michailidis George, Karnovsky Alla
Department of Computational Medicine and Bioinformatics, University of Michigan Medical School, Ann Arbor, MI 48109, USA.
Michigan Regional Comprehensive Metabolomics Resource Core, Biomedical Research Core Facilities, University of Michigan Medical School, Ann Arbor, MI 48109, USA.
Metabolites. 2020 Nov 24;10(12):479. doi: 10.3390/metabo10120479.
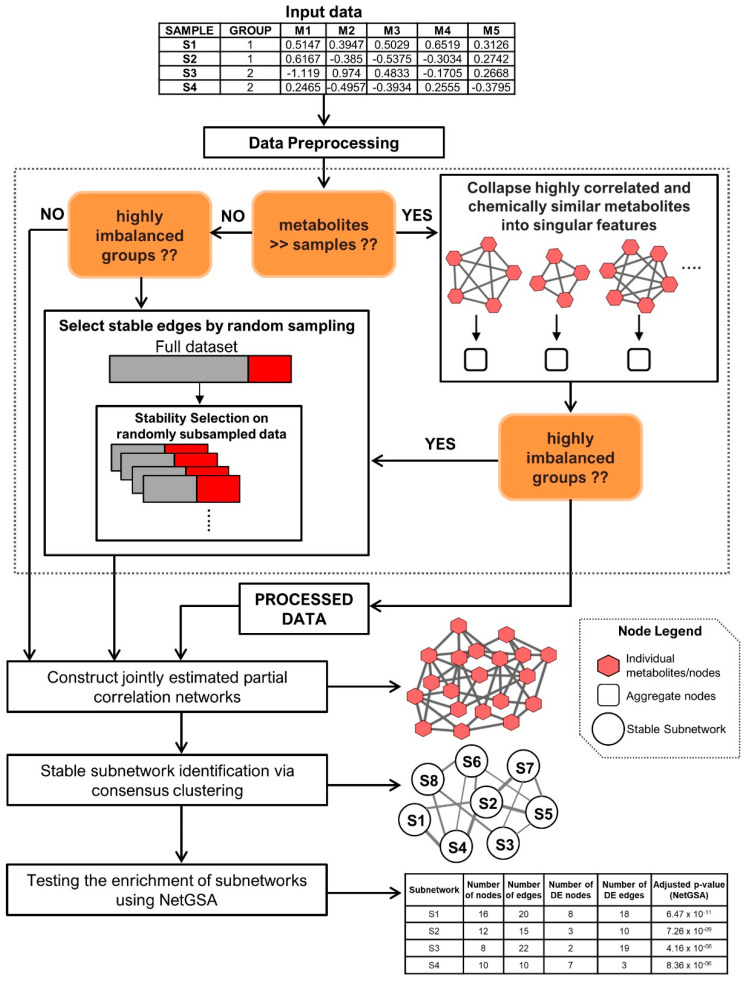
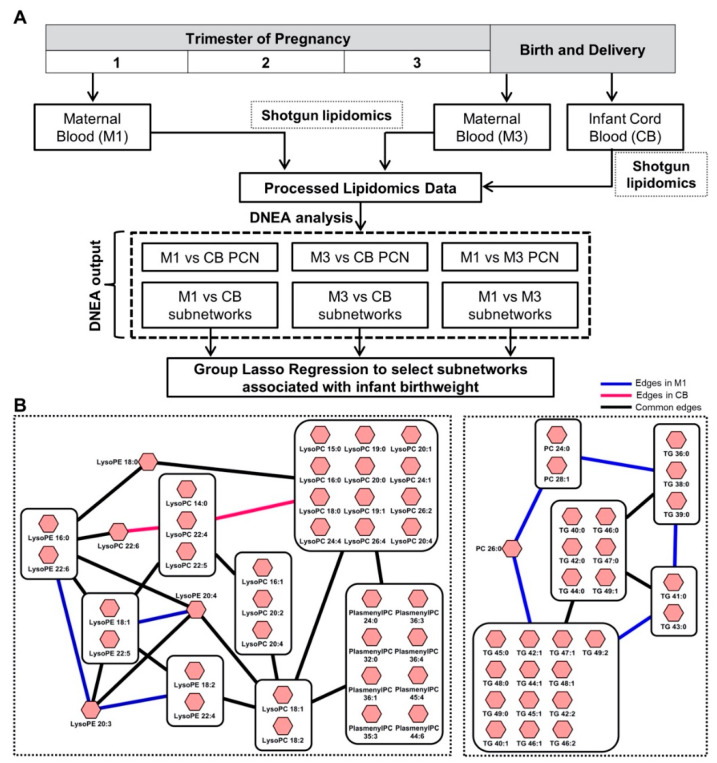
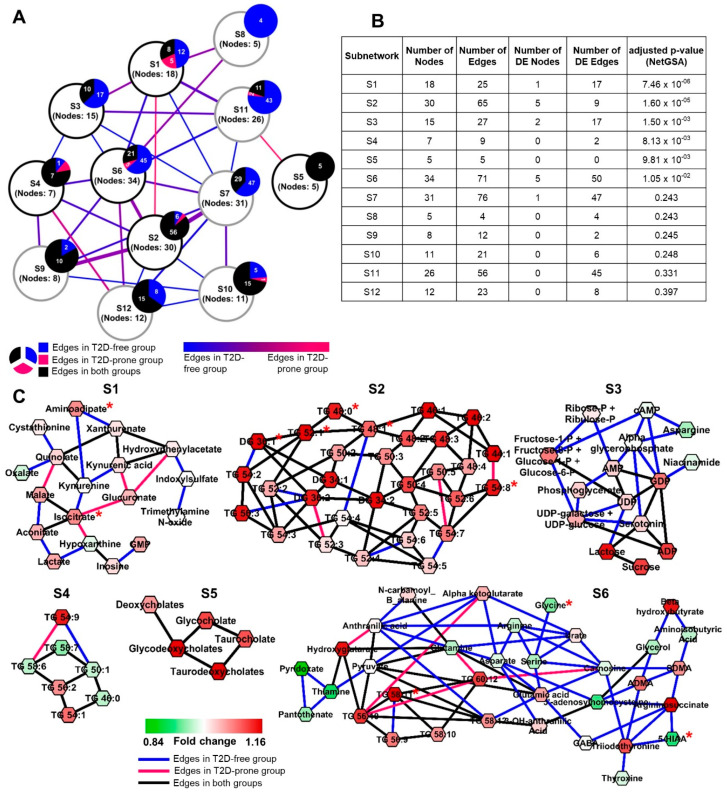
Modern analytical methods allow for the simultaneous detection of hundreds of metabolites, generating increasingly large and complex data sets. The analysis of metabolomics data is a multi-step process that involves data processing and normalization, followed by statistical analysis. One of the biggest challenges in metabolomics is linking alterations in metabolite levels to specific biological processes that are disrupted, contributing to the development of disease or reflecting the disease state. A common approach to accomplishing this goal involves pathway mapping and enrichment analysis, which assesses the relative importance of predefined metabolic pathways or other biological categories. However, traditional knowledge-based enrichment analysis has limitations when it comes to the analysis of metabolomics and lipidomics data. We present a Java-based, user-friendly bioinformatics tool named Filigree that provides a primarily data-driven alternative to the existing knowledge-based enrichment analysis methods. Filigree is based on our previously published differential network enrichment analysis (DNEA) methodology. To demonstrate the utility of the tool, we applied it to previously published studies analyzing the metabolome in the context of metabolic disorders (type 1 and 2 diabetes) and the maternal and infant lipidome during pregnancy.
现代分析方法能够同时检测数百种代谢物,生成规模越来越大且越来越复杂的数据集。代谢组学数据分析是一个多步骤过程,包括数据处理和归一化,随后是统计分析。代谢组学面临的最大挑战之一是将代谢物水平的变化与特定的生物过程联系起来,这些生物过程受到干扰,导致疾病的发展或反映疾病状态。实现这一目标的常用方法包括通路映射和富集分析,该分析评估预定义代谢通路或其他生物类别的相对重要性。然而,传统的基于知识的富集分析在代谢组学和脂质组学数据分析方面存在局限性。我们展示了一种名为Filigree的基于Java的、用户友好的生物信息学工具,它为现有的基于知识的富集分析方法提供了一种主要由数据驱动的替代方法。Filigree基于我们之前发表的差异网络富集分析(DNEA)方法。为了证明该工具的实用性,我们将其应用于之前发表的研究,这些研究在代谢紊乱(1型和2型糖尿病)的背景下分析代谢组,以及在怀孕期间分析母婴脂质组。