Moore Bethany M, Wang Peipei, Fan Pengxiang, Lee Aaron, Leong Bryan, Lou Yann-Ru, Schenck Craig A, Sugimoto Koichi, Last Robert, Lehti-Shiu Melissa D, Barry Cornelius S, Shiu Shin-Han
Department of Plant Biology, Michigan State University, East Lansing, MI, USA.
Ecology, Evolutionary Biology, and Behavior Program, Michigan State University, East Lansing, MI, USA.
In Silico Plants. 2020;2(1):diaa005. doi: 10.1093/insilicoplants/diaa005. Epub 2020 Jul 30.
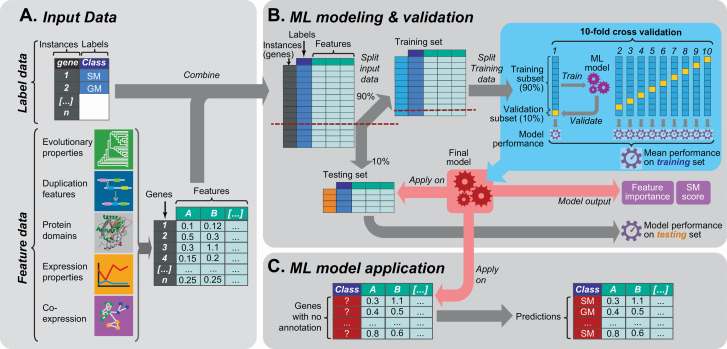
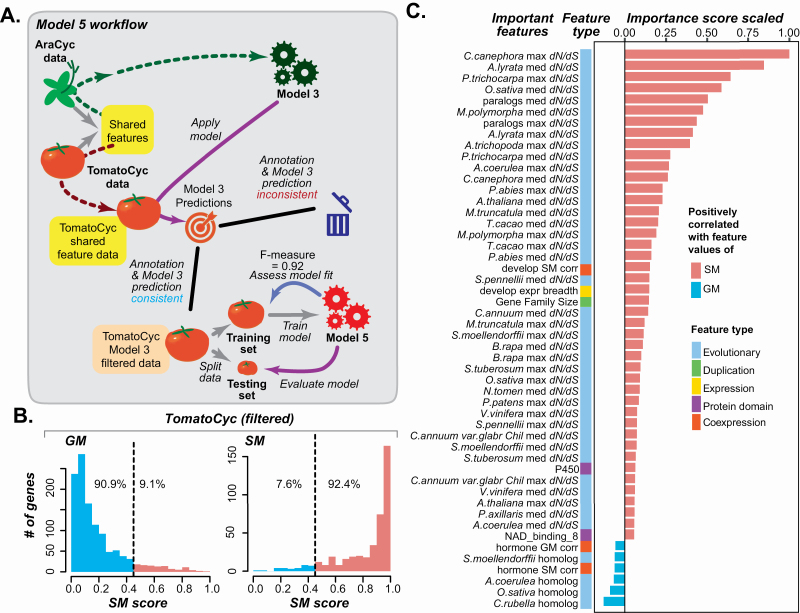
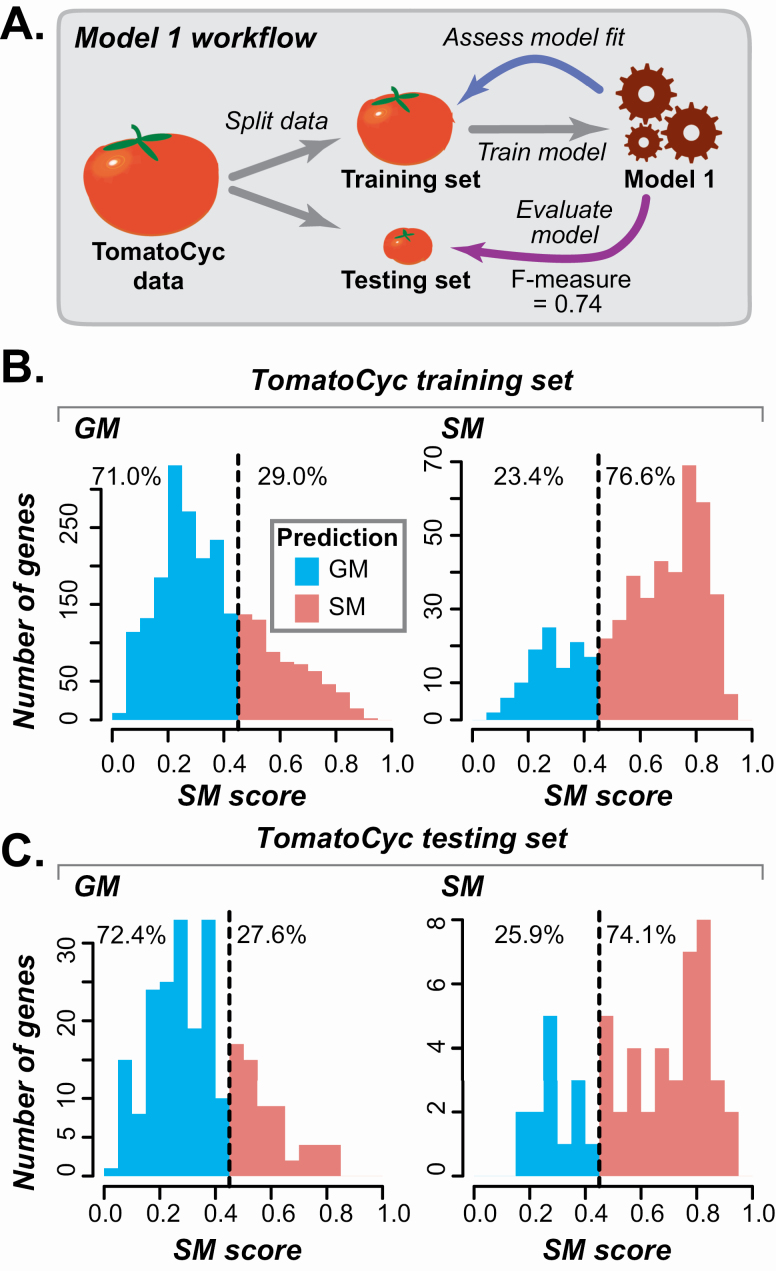
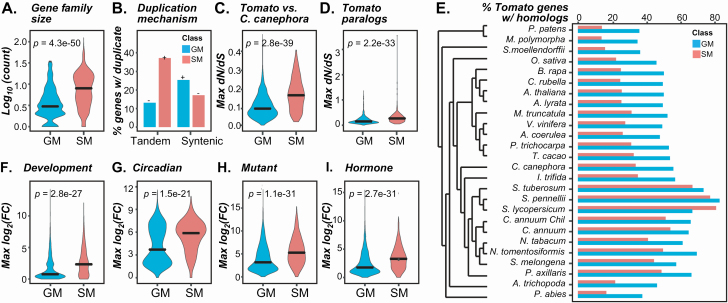
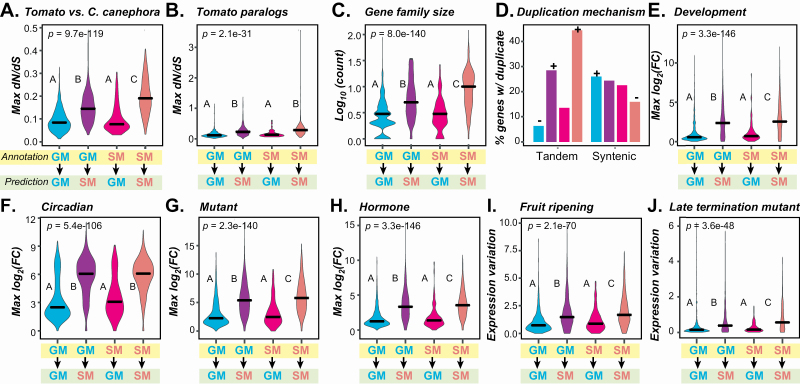
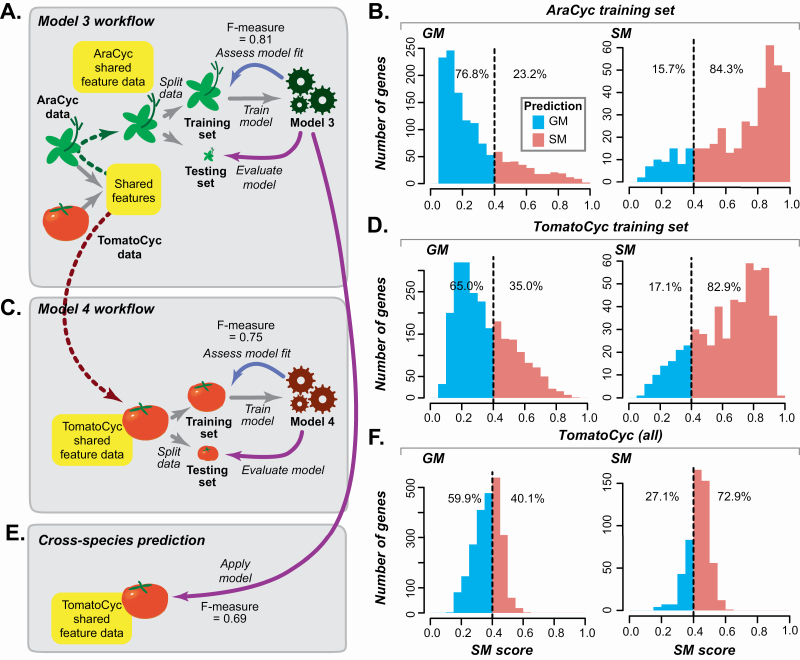
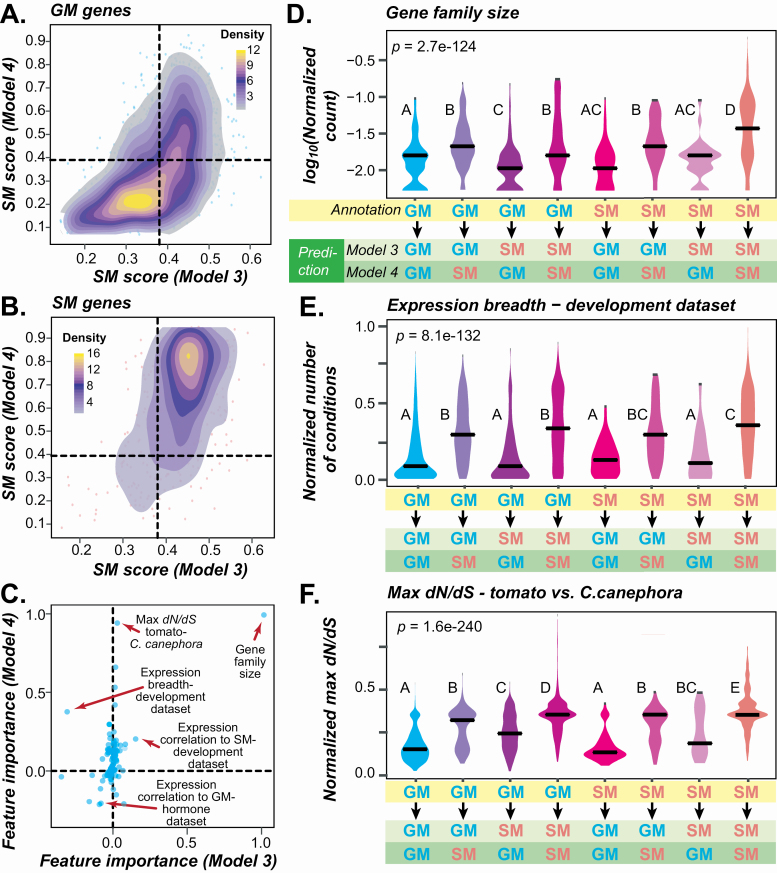
Plant specialized metabolites mediate interactions between plants and the environment and have significant agronomical/pharmaceutical value. Most genes involved in specialized metabolism (SM) are unknown because of the large number of metabolites and the challenge in differentiating SM genes from general metabolism (GM) genes. Plant models like have extensive, experimentally derived annotations, whereas many non-model species do not. Here we employed a machine learning strategy, transfer learning, where knowledge from is transferred to predict gene functions in cultivated tomato with fewer experimentally annotated genes. The first tomato SM/GM prediction model using only tomato data performs well (-measure = 0.74, compared with 0.5 for random and 1.0 for perfect predictions), but from manually curating 88 SM/GM genes, we found many mis-predicted entries were likely mis-annotated. When the SM/GM prediction models built with data were used to filter out genes where the based model predictions disagreed with tomato annotations, the new tomato model trained with filtered data improved significantly (-measure = 0.92). Our study demonstrates that SM/GM genes can be better predicted by leveraging cross-species information. Additionally, our findings provide an example for transfer learning in genomics where knowledge can be transferred from an information-rich species to an information-poor one.
植物特化代谢产物介导植物与环境之间的相互作用,具有重要的农学/药学价值。由于代谢产物数量众多,且难以将特化代谢(SM)基因与一般代谢(GM)基因区分开来,参与特化代谢的大多数基因尚不清楚。像[具体植物模型名称未给出]这样的植物模型有广泛的、通过实验得出的注释,而许多非模式物种则没有。在这里,我们采用了一种机器学习策略——迁移学习,即将来自[具体植物模型名称未给出]的知识进行迁移,以预测栽培番茄中基因的功能,而栽培番茄中通过实验注释的基因较少。第一个仅使用番茄数据的番茄SM/GM预测模型表现良好(F值 = 0.74,随机预测为0.5,完美预测为1.0),但通过人工筛选88个SM/GM基因,我们发现许多错误预测的条目可能是注释错误。当使用基于[具体植物模型名称未给出]数据构建的SM/GM预测模型来筛选出基于该模型的预测与番茄注释不一致的基因时,用筛选后的数据训练的新番茄模型有了显著改进(F值 = 0.92)。我们的研究表明,利用跨物种信息可以更好地预测SM/GM基因。此外,我们的研究结果为基因组学中的迁移学习提供了一个范例,即知识可以从信息丰富的物种转移到信息匮乏的物种。