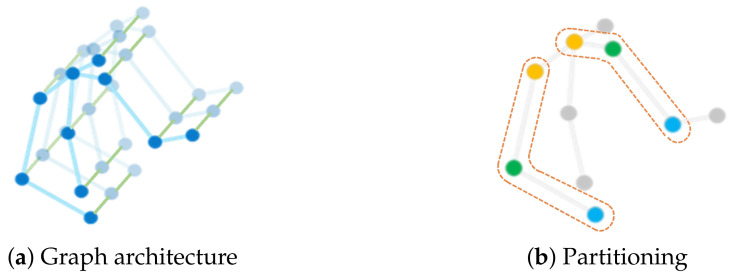Graduate School of Engineering Science, Osaka University, Osaka 565-0871, Japan.
Advanced Telecommunications Research Institute International, Kyoto 619-0237, Japan.
Sensors (Basel). 2020 Dec 30;21(1):205. doi: 10.3390/s21010205.
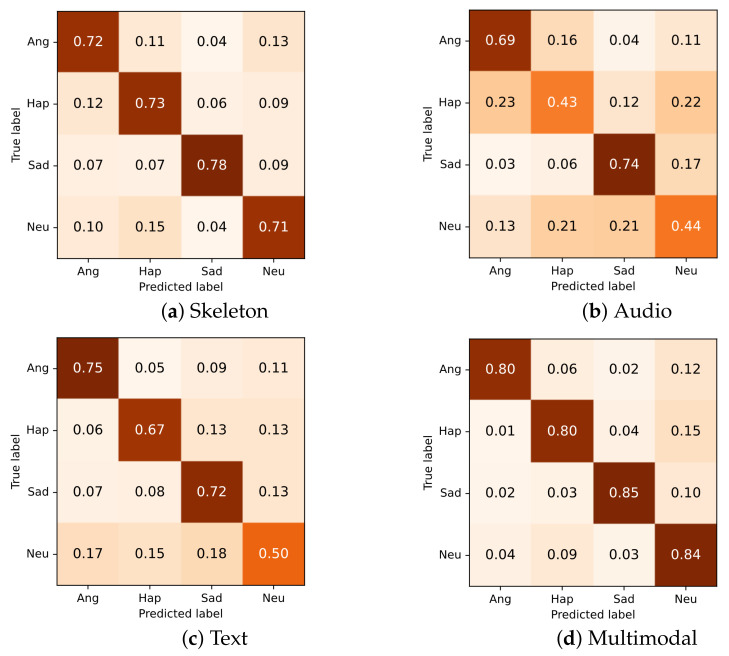
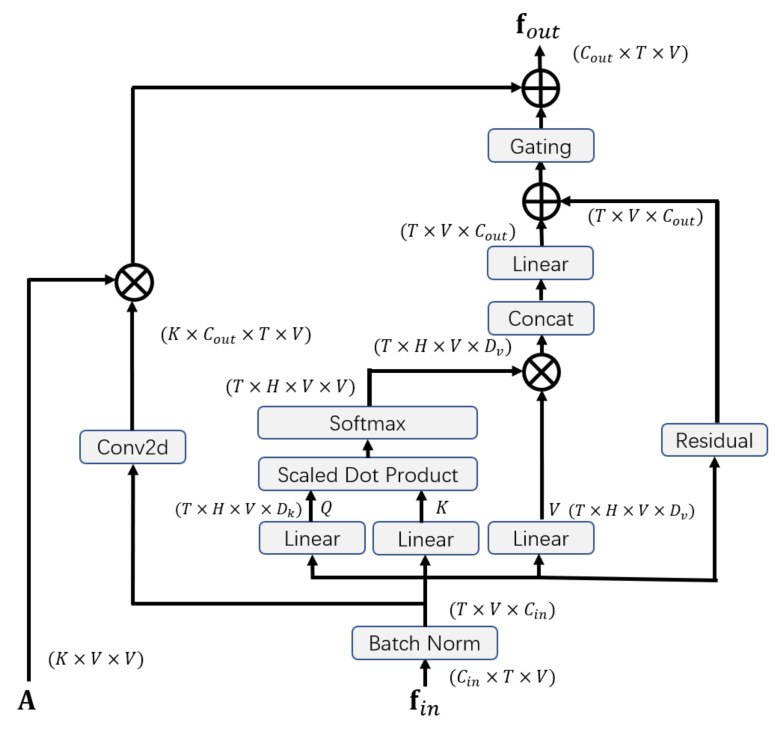
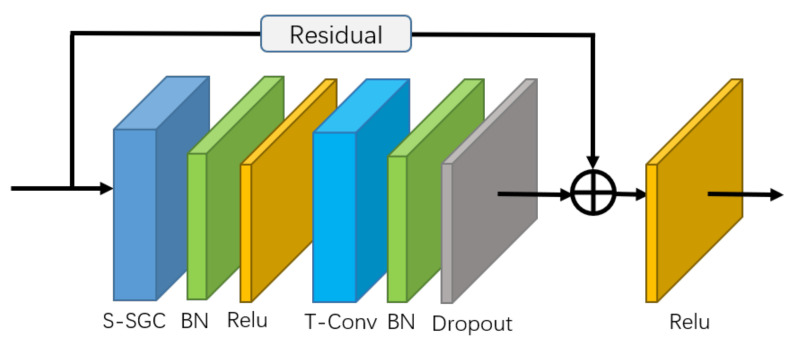
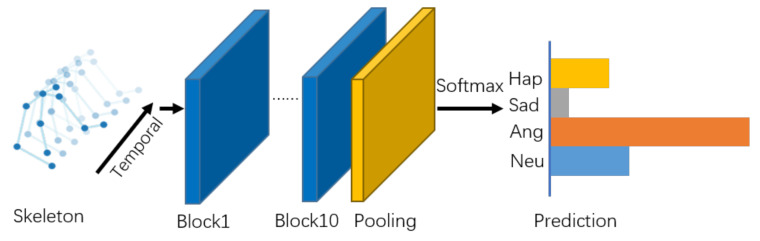
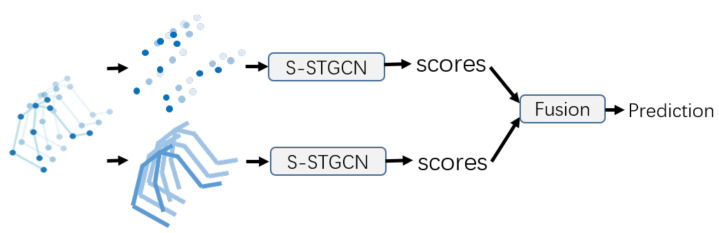
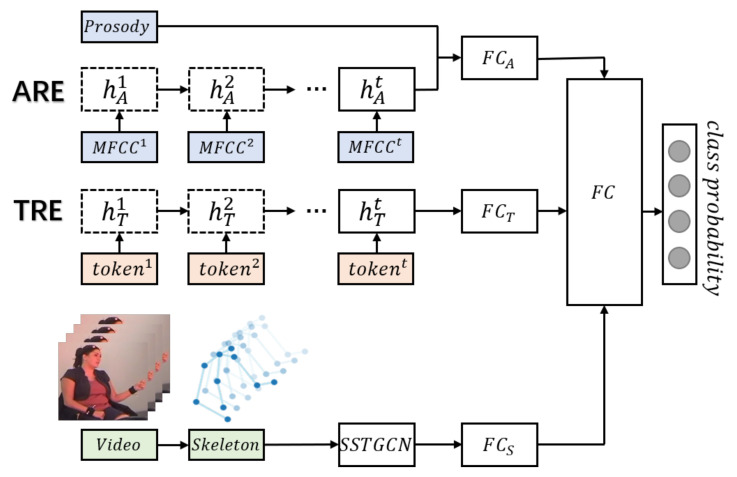
Emotion recognition has drawn consistent attention from researchers recently. Although gesture modality plays an important role in expressing emotion, it is seldom considered in the field of emotion recognition. A key reason is the scarcity of labeled data containing 3D skeleton data. Some studies in action recognition have applied graph-based neural networks to explicitly model the spatial connection between joints. However, this method has not been considered in the field of gesture-based emotion recognition, so far. In this work, we applied a pose estimation based method to extract 3D skeleton coordinates for IEMOCAP database. We propose a self-attention enhanced spatial temporal graph convolutional network for skeleton-based emotion recognition, in which the spatial convolutional part models the skeletal structure of the body as a static graph, and the self-attention part dynamically constructs more connections between the joints and provides supplementary information. Our experiment demonstrates that the proposed model significantly outperforms other models and that the features of the extracted skeleton data improve the performance of multimodal emotion recognition.
情感识别最近引起了研究人员的持续关注。尽管手势模态在表达情感方面起着重要作用,但在情感识别领域很少被考虑。一个关键原因是缺乏包含 3D 骨骼数据的标记数据。一些动作识别研究已经应用基于图的神经网络来显式地建模关节之间的空间连接。然而,到目前为止,这种方法在基于手势的情感识别领域还没有被考虑。在这项工作中,我们应用了一种基于姿势估计的方法来提取 IEMOCAP 数据库的 3D 骨骼坐标。我们提出了一种基于注意力增强的时空图卷积网络,用于基于骨骼的情感识别,其中空间卷积部分将身体的骨骼结构建模为静态图,而注意力部分动态地在关节之间建立更多的连接,并提供补充信息。我们的实验表明,所提出的模型显著优于其他模型,并且提取的骨骼数据的特征提高了多模态情感识别的性能。