Department of Biostatistics, University of Florida, 2004 Mowry Rd, Gainesville, FL, 32610, USA.
Department of Oral Biology, University of Florida, 1395 Center Drive, Gainesville, FL, 32610, USA.
Biol Direct. 2021 Jan 4;16(1):1. doi: 10.1186/s13062-020-00284-1.
Composition of microbial communities can be location-specific, and the different abundance of taxon within location could help us to unravel city-specific signature and predict the sample origin locations accurately. In this study, the whole genome shotgun (WGS) metagenomics data from samples across 16 cities around the world and samples from another 8 cities were provided as the main and mystery datasets respectively as the part of the CAMDA 2019 MetaSUB "Forensic Challenge". The feature selecting, normalization, three methods of machine learning, PCoA (Principal Coordinates Analysis) and ANCOM (Analysis of composition of microbiomes) were conducted for both the main and mystery datasets.
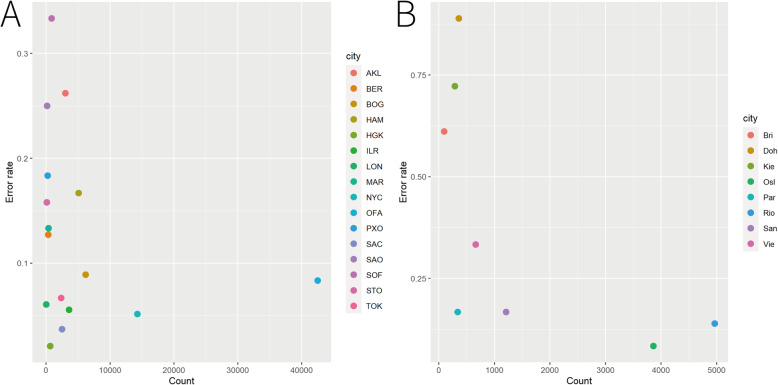
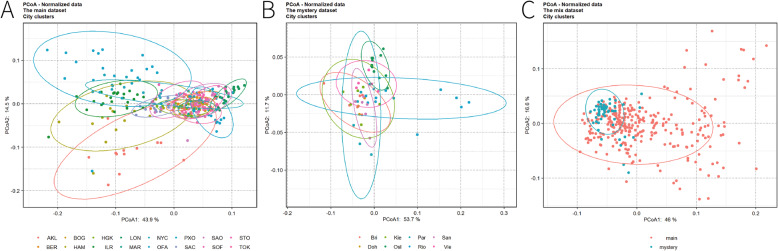
Features selecting, combined with the machines learning methods, revealed that the combination of the common features was effective for predicting the origin of the samples. The average error rates of 11.93 and 30.37% of three machine learning methods were obtained for main and mystery datasets respectively. Using the samples from main dataset to predict the labels of samples from mystery dataset, nearly 89.98% of the test samples could be correctly labeled as "mystery" samples. PCoA showed that nearly 60% of the total variability of the data could be explained by the first two PCoA axes. Although many cities overlapped, the separation of some cities was found in PCoA. The results of ANCOM, combined with importance score from the Random Forest, indicated that the common "family", "order" of the main-dataset and the common "order" of the mystery dataset provided the most efficient information for prediction respectively.
The results of the classification suggested that the composition of the microbiomes was distinctive across the cities, which could be used to identify the sample origins. This was also supported by the results from ANCOM and importance score from the RF. In addition, the accuracy of the prediction could be improved by more samples and better sequencing depth.
微生物群落的组成可能具有特定的位置特征,而特定位置中分类单元的不同丰度可以帮助我们揭示城市特有的特征,并准确预测样本的来源地。在这项研究中,来自全球 16 个城市的样本的全基因组鸟枪法(WGS)宏基因组学数据和来自另外 8 个城市的样本作为主要数据集和神秘数据集分别提供,作为 2019 年 CAMDA 宏基因组学数据分析挑战赛“法医挑战”的一部分。对主要数据集和神秘数据集都进行了特征选择、归一化以及三种机器学习方法(主坐标分析(PCoA)和微生物组组成分析(ANCOM))。
特征选择与机器学习方法相结合,表明共同特征的组合对预测样本来源非常有效。三种机器学习方法的平均错误率分别为主要数据集和神秘数据集的 11.93%和 30.37%。使用主要数据集的样本预测神秘数据集的标签,近 89.98%的测试样本可以正确标记为“神秘”样本。PCoA 表明,数据的总可变性近 60%可以用前两个 PCoA 轴来解释。虽然许多城市重叠,但在 PCoA 中发现了一些城市的分离。结合随机森林的重要性得分的 ANCOM 结果表明,主要数据集的共同“科”和神秘数据集的共同“目”为预测提供了最有效的信息。
分类结果表明,微生物组的组成在不同城市之间具有独特性,可以用于识别样本来源。这也得到了 ANCOM 和 RF 的重要性得分的支持。此外,通过增加样本数量和提高测序深度可以提高预测的准确性。