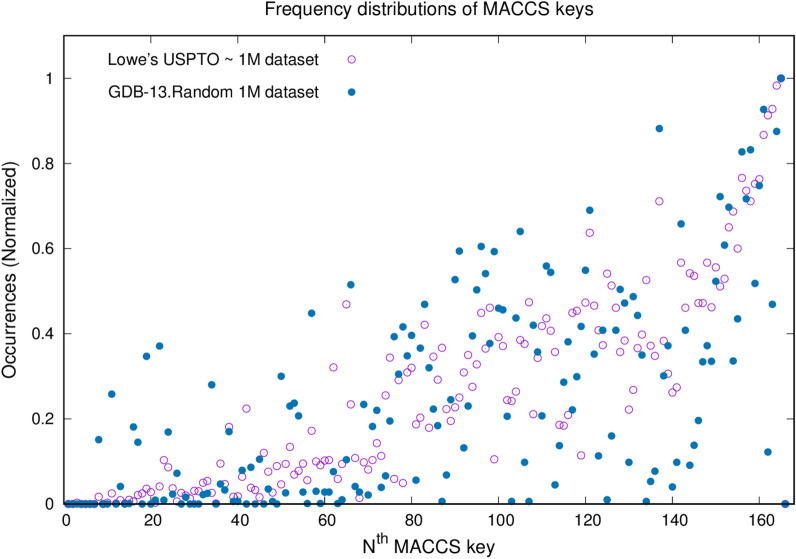
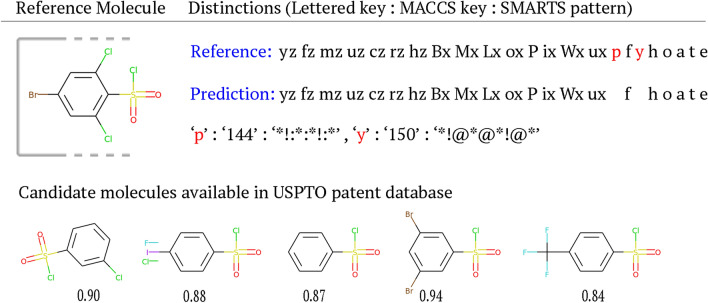
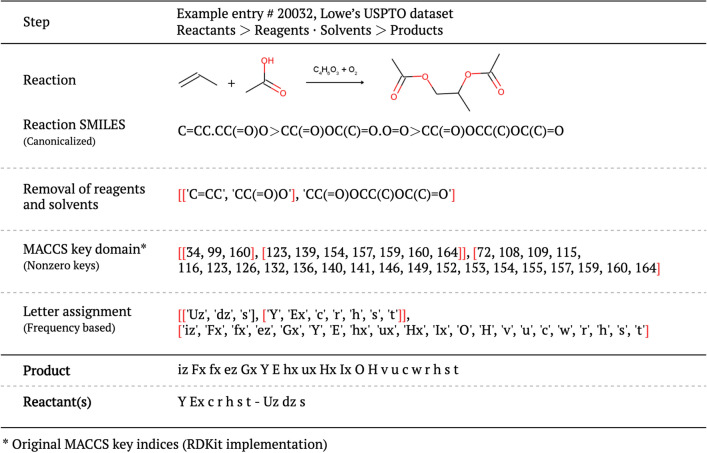
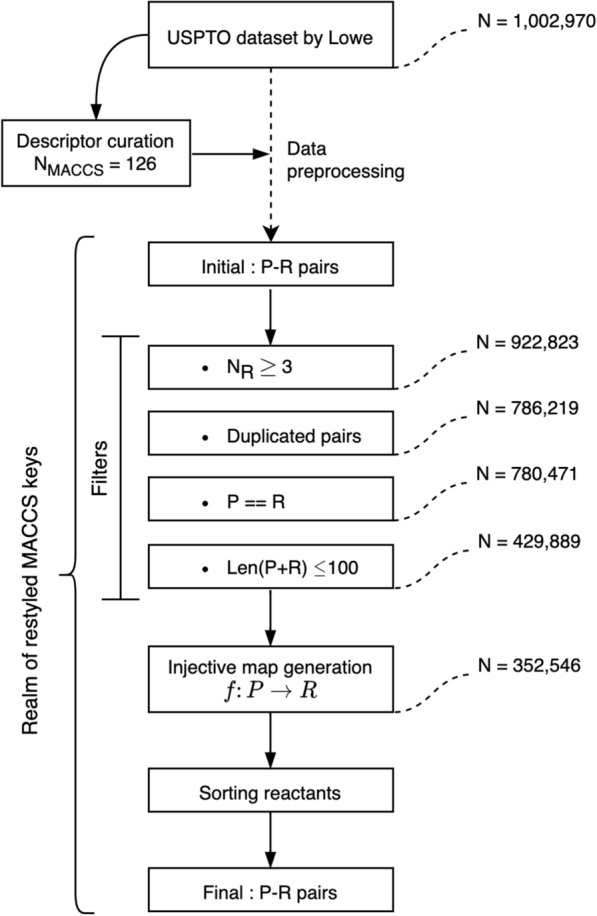
Ucak Umit V, Kang Taek, Ko Junsu, Lee Juyong
Division of Chemistry and Biochemistry, Department of Chemistry, Kangwon National University, Chuncheon, South Korea.
Center for Neuro-Medicine, Brain Science Institute, Korea Institute of Science and Technology, Seoul, South Korea.
J Cheminform. 2021 Jan 11;13(1):4. doi: 10.1186/s13321-020-00482-z.
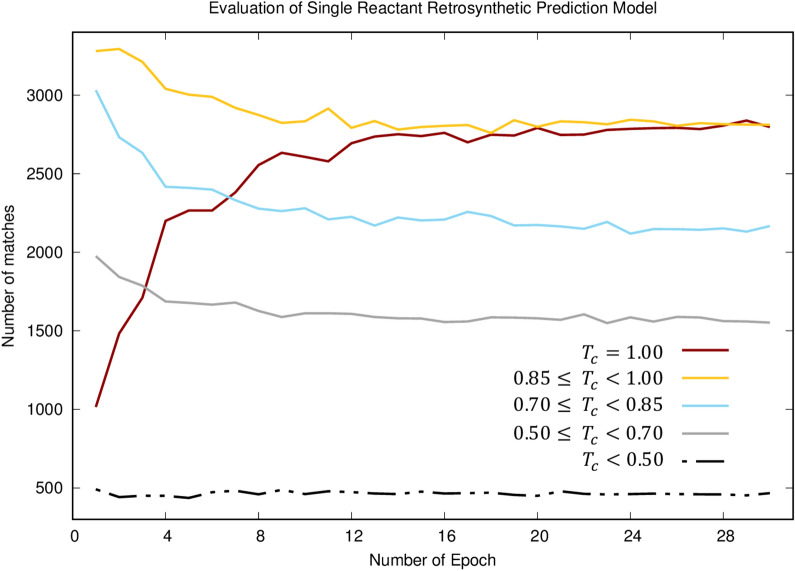
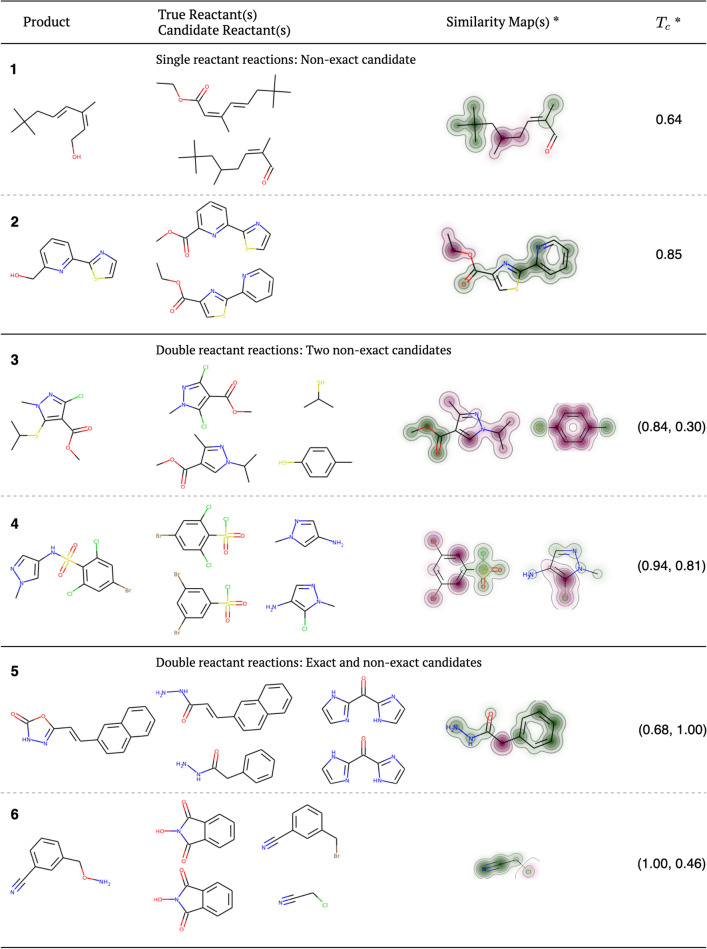
With the rapid improvement of machine translation approaches, neural machine translation has started to play an important role in retrosynthesis planning, which finds reasonable synthetic pathways for a target molecule. Previous studies showed that utilizing the sequence-to-sequence frameworks of neural machine translation is a promising approach to tackle the retrosynthetic planning problem. In this work, we recast the retrosynthetic planning problem as a language translation problem using a template-free sequence-to-sequence model. The model is trained in an end-to-end and a fully data-driven fashion. Unlike previous models translating the SMILES strings of reactants and products, we introduced a new way of representing a chemical reaction based on molecular fragments. It is demonstrated that the new approach yields better prediction results than current state-of-the-art computational methods. The new approach resolves the major drawbacks of existing retrosynthetic methods such as generating invalid SMILES strings. Specifically, our approach predicts highly similar reactant molecules with an accuracy of 57.7%. In addition, our method yields more robust predictions than existing methods.
随着机器翻译方法的迅速改进,神经机器翻译已开始在逆合成规划中发挥重要作用,逆合成规划旨在为目标分子找到合理的合成途径。先前的研究表明,利用神经机器翻译的序列到序列框架是解决逆合成规划问题的一种有前途的方法。在这项工作中,我们使用无模板的序列到序列模型将逆合成规划问题重塑为语言翻译问题。该模型以端到端和完全数据驱动的方式进行训练。与之前翻译反应物和产物的SMILES字符串的模型不同,我们引入了一种基于分子片段表示化学反应的新方法。结果表明,新方法比当前最先进的计算方法产生更好的预测结果。新方法解决了现有逆合成方法的主要缺点,如生成无效的SMILES字符串。具体而言,我们的方法预测高度相似的反应物分子的准确率为57.7%。此外,我们的方法比现有方法产生更稳健的预测。