Institute of Structural Biology, Helmholtz Zentrum München-Research Center for Environmental Health (GmbH), Ingolstädter Landstraße 1, D-85764, Neuherberg, Germany.
BIGCHEM GmbH, Valerystr. 49, D-85716, Unterschleißheim, Germany.
Nat Commun. 2020 Nov 4;11(1):5575. doi: 10.1038/s41467-020-19266-y.
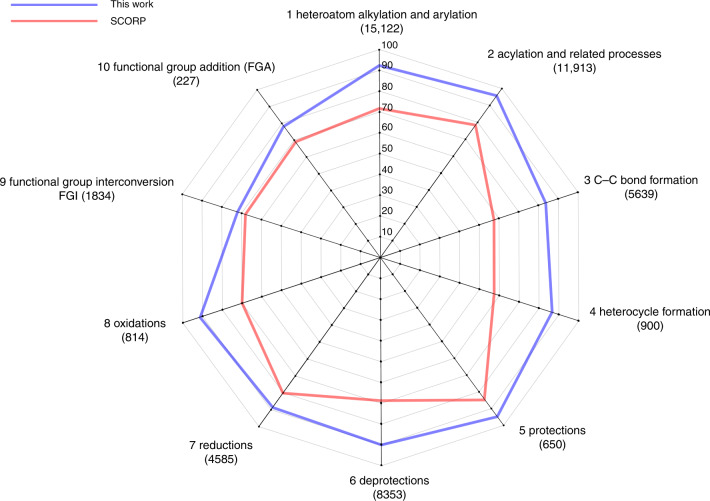
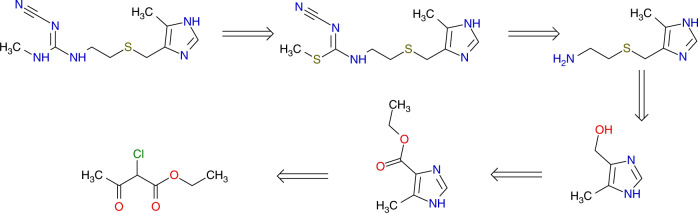
We investigated the effect of different training scenarios on predicting the (retro)synthesis of chemical compounds using text-like representation of chemical reactions (SMILES) and Natural Language Processing (NLP) neural network Transformer architecture. We showed that data augmentation, which is a powerful method used in image processing, eliminated the effect of data memorization by neural networks and improved their performance for prediction of new sequences. This effect was observed when augmentation was used simultaneously for input and the target data simultaneously. The top-5 accuracy was 84.8% for the prediction of the largest fragment (thus identifying principal transformation for classical retro-synthesis) for the USPTO-50k test dataset, and was achieved by a combination of SMILES augmentation and a beam search algorithm. The same approach provided significantly better results for the prediction of direct reactions from the single-step USPTO-MIT test set. Our model achieved 90.6% top-1 and 96.1% top-5 accuracy for its challenging mixed set and 97% top-5 accuracy for the USPTO-MIT separated set. It also significantly improved results for USPTO-full set single-step retrosynthesis for both top-1 and top-10 accuracies. The appearance frequency of the most abundantly generated SMILES was well correlated with the prediction outcome and can be used as a measure of the quality of reaction prediction.
我们研究了不同的训练场景对使用化学反应的文本表示形式(SMILES)和自然语言处理(NLP)神经网络 Transformer 架构预测化合物的(反)合成的影响。我们表明,数据增强是图像处理中使用的一种强大方法,通过神经网络消除了数据记忆的影响,并提高了它们对新序列的预测性能。当同时对输入和目标数据进行增强时,会观察到这种效果。对于 USPTO-50k 测试数据集,我们的模型在预测最大片段(从而确定经典反合成的主要转化)方面的准确率最高可达 84.8%,这是通过 SMILES 增强和波束搜索算法的组合实现的。同样的方法为直接反应的预测提供了显著更好的结果,来自单步 USPTO-MIT 测试集。我们的模型在其具有挑战性的混合集中实现了 90.6%的 top-1 和 96.1%的 top-5 准确率,在 USPTO-MIT 分离集中实现了 97%的 top-5 准确率。它还显著提高了 USPTO-ful 集单步反合成的 top-1 和 top-10 准确率。最丰富生成的 SMILES 的出现频率与预测结果密切相关,可作为反应预测质量的衡量标准。