Bento A Patrícia, Hersey Anne, Félix Eloy, Landrum Greg, Gaulton Anna, Atkinson Francis, Bellis Louisa J, De Veij Marleen, Leach Andrew R
European Molecular Biology Laboratory, European Bioinformatics Institute, Wellcome Genome Campus, Hinxton, CB10 1SD, Cambridgeshire, UK.
T5 Informatics GmbH, Basel, 4055, Switzerland.
J Cheminform. 2020 Sep 1;12(1):51. doi: 10.1186/s13321-020-00456-1.
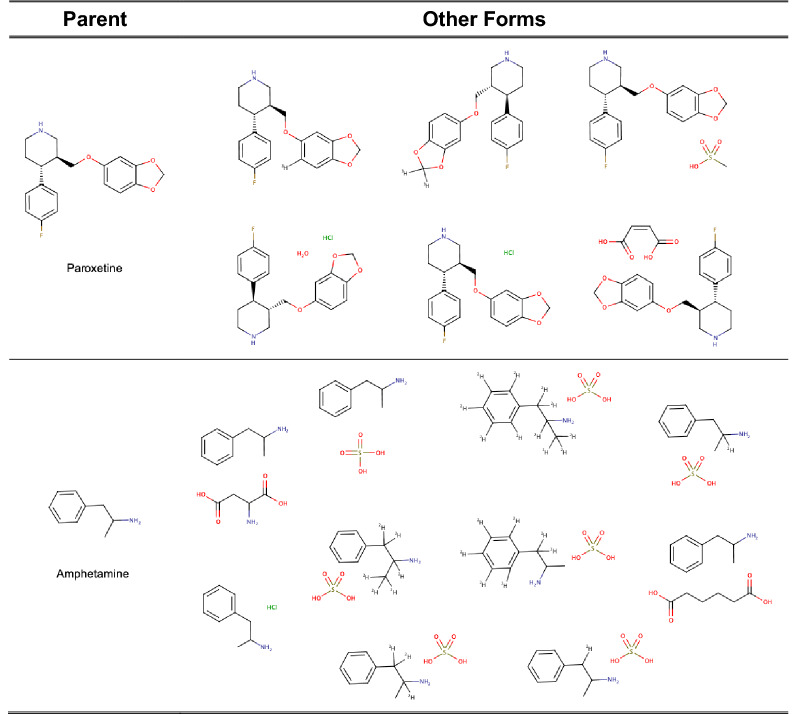
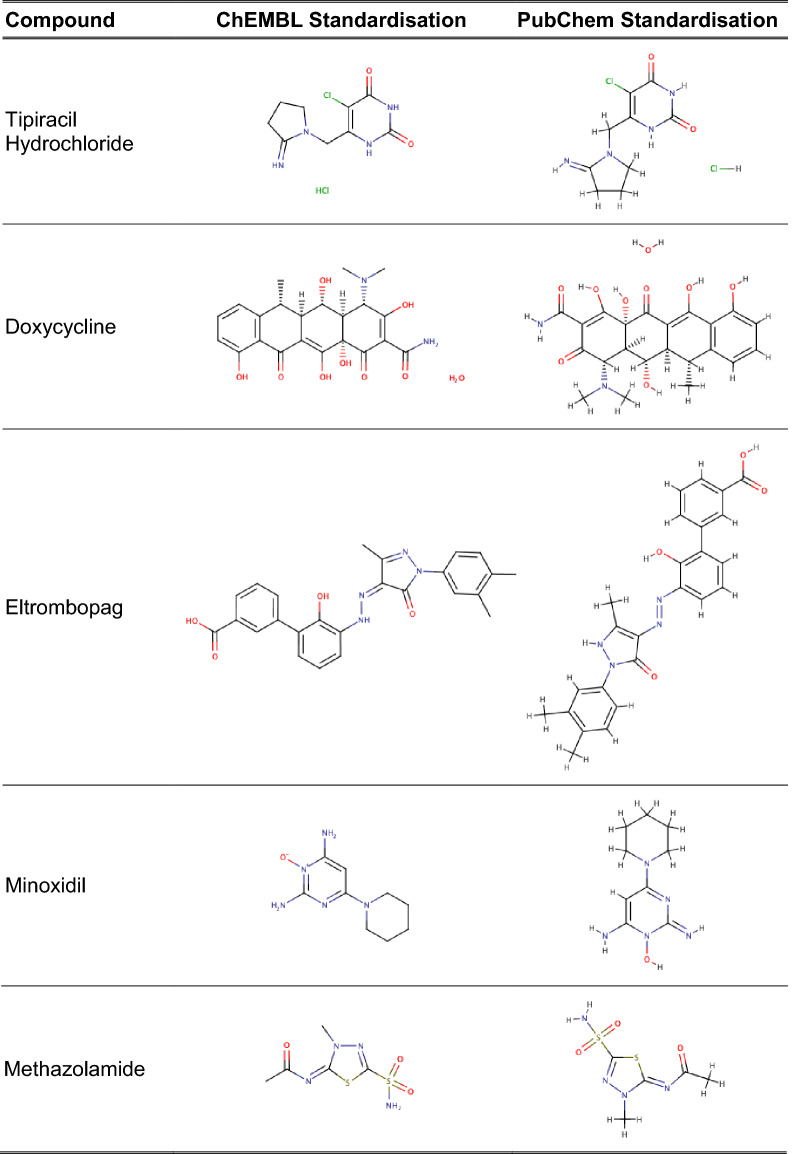
The ChEMBL database is one of a number of public databases that contain bioactivity data on small molecule compounds curated from diverse sources. Incoming compounds are typically not standardised according to consistent rules. In order to maintain the quality of the final database and to easily compare and integrate data on the same compound from different sources it is necessary for the chemical structures in the database to be appropriately standardised.
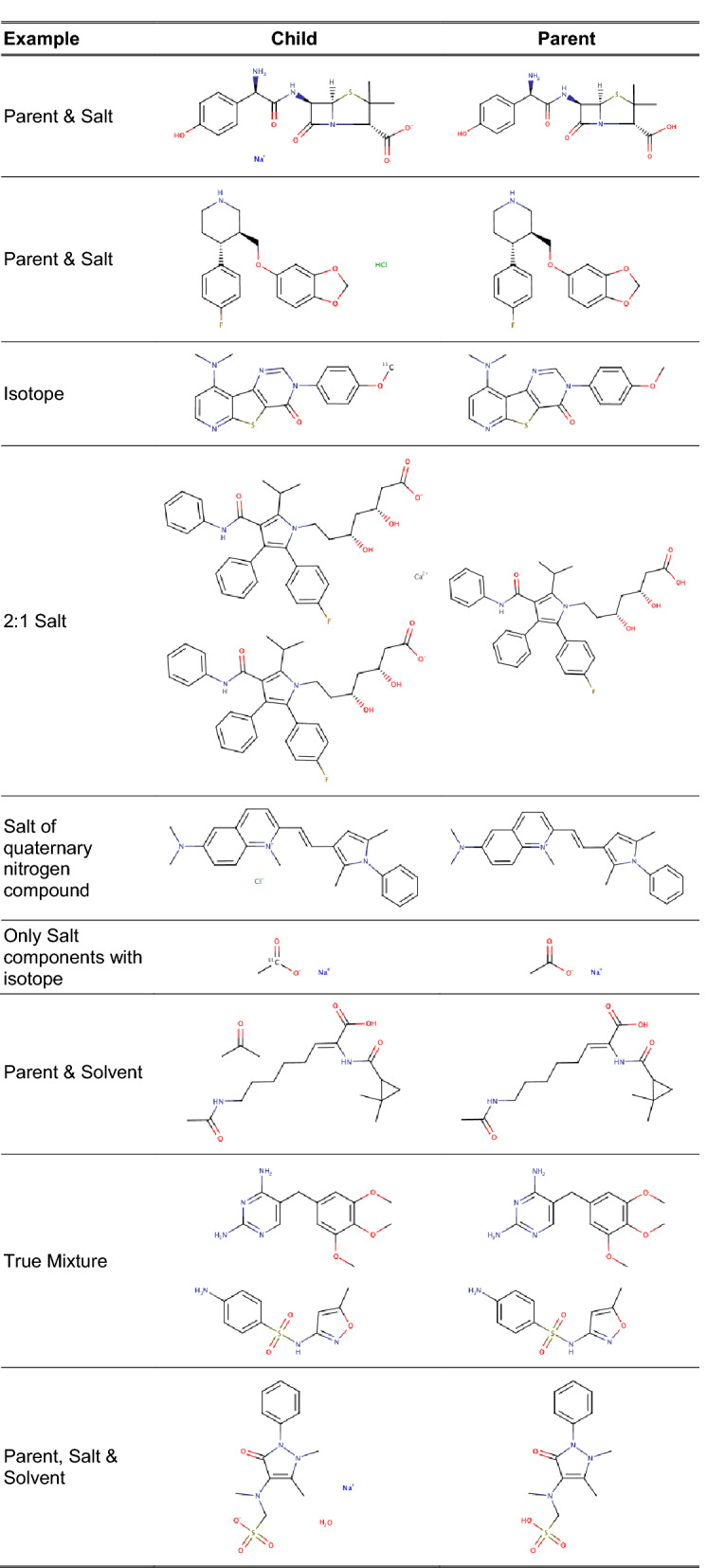
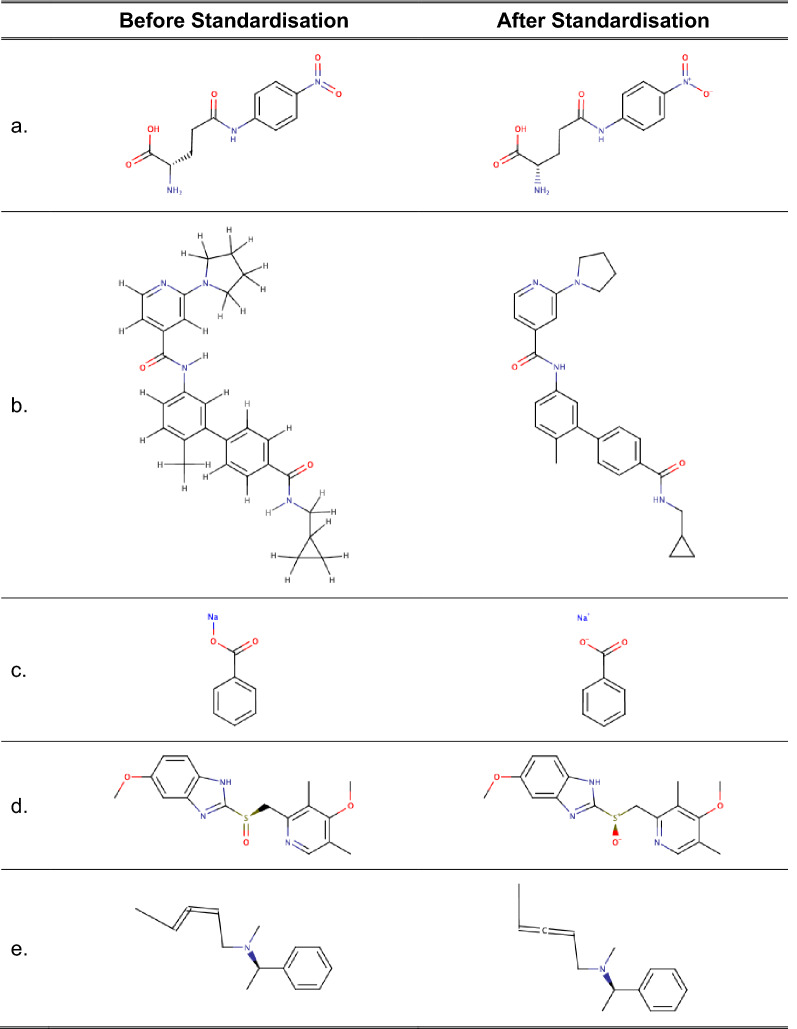
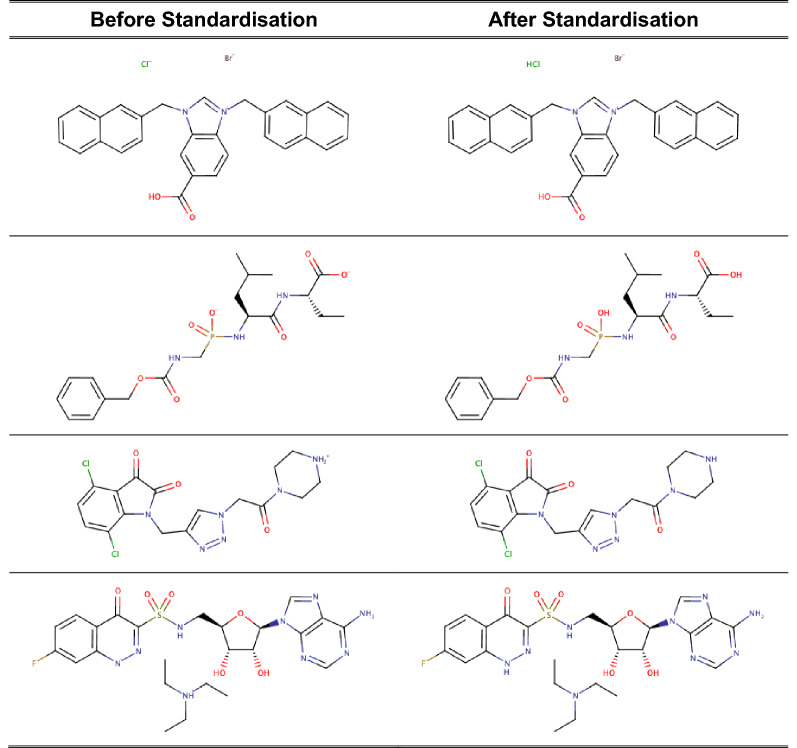
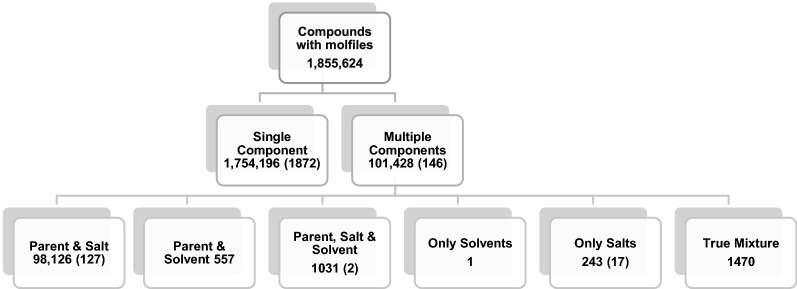
A chemical curation pipeline has been developed using the open source toolkit RDKit. It comprises three components: a Checker to test the validity of chemical structures and flag any serious errors; a Standardizer which formats compounds according to defined rules and conventions and a GetParent component that removes any salts and solvents from the compound to create its parent. This pipeline has been applied to the latest version of the ChEMBL database as well as uncurated datasets from other sources to test the robustness of the process and to identify common issues in database molecular structures.
All the components of the structure pipeline have been made freely available for other researchers to use and adapt for their own use. The code is available in a GitHub repository and it can also be accessed via the ChEMBL Beaker webservices. It has been used successfully to standardise the nearly 2 million compounds in the ChEMBL database and the compound validity checker has been used to identify compounds with the most serious issues so that they can be prioritised for manual curation.
ChEMBL数据库是众多公共数据库之一,这些数据库包含从不同来源整理的小分子化合物的生物活性数据。传入的化合物通常未按照一致的规则进行标准化。为了保持最终数据库的质量,并便于比较和整合来自不同来源的同一化合物的数据,数据库中的化学结构需要进行适当的标准化。
利用开源工具包RDKit开发了一种化学整理流程。它由三个组件组成:一个用于测试化学结构有效性并标记任何严重错误的检查器;一个根据定义的规则和惯例对化合物进行格式化的标准化器;以及一个从化合物中去除任何盐和溶剂以生成其母体的获取母体组件。此流程已应用于ChEMBL数据库的最新版本以及来自其他来源的未整理数据集,以测试该过程的稳健性并识别数据库分子结构中的常见问题。
结构流程的所有组件已免费提供给其他研究人员使用和改编以供他们自己使用。代码可在GitHub存储库中获取,也可通过ChEMBL Beaker网络服务访问。它已成功用于标准化ChEMBL数据库中的近200万种化合物,并且化合物有效性检查器已用于识别问题最严重的化合物,以便可以优先对其进行人工整理。