Roy Satyaki, Dutta Ronojoy, Ghosh Preetam
University of North Carolina, Chapel Hill, USA.
Deep Run High School, Glen Allen, VA USA.
Appl Netw Sci. 2021;6(1):2. doi: 10.1007/s41109-020-00349-0. Epub 2021 Jan 7.
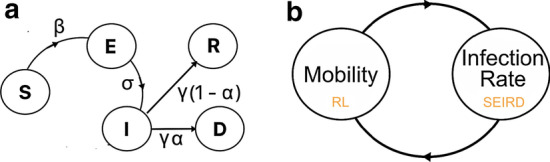
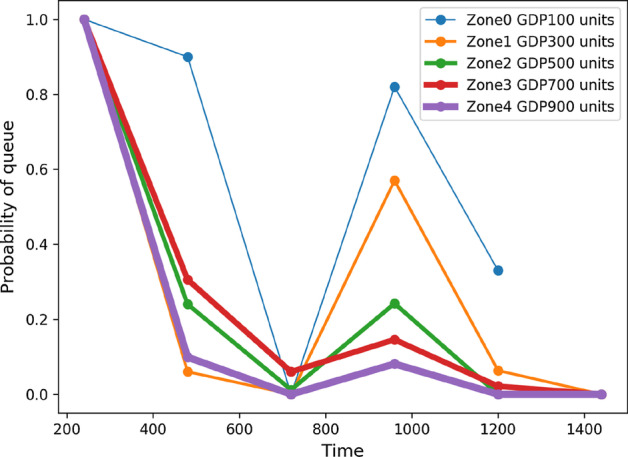
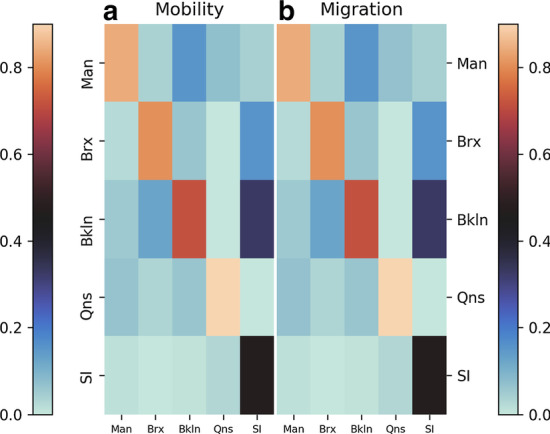
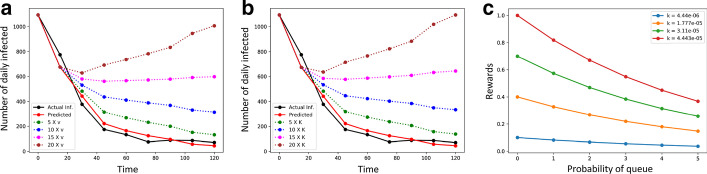
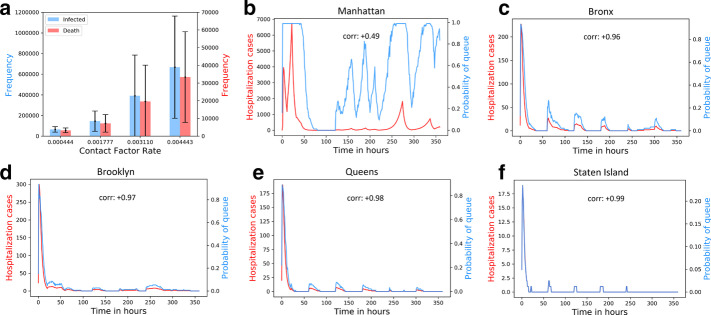
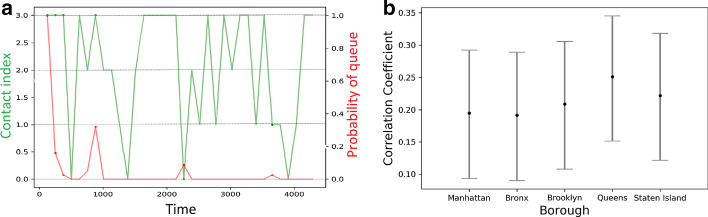
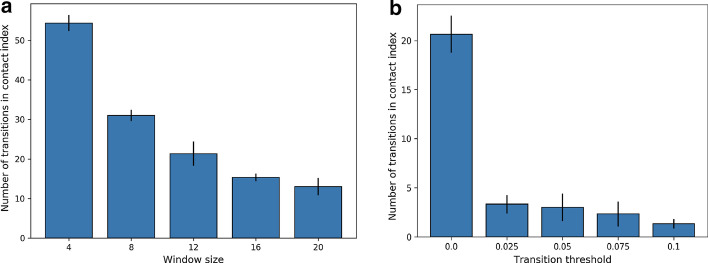
COVID-19 is one of the deadliest pandemics in modern human history that has killed nearly a million people and rapidly inundated the healthcare resources around the world. Current lockdown measures to curb infection spread are threatening to bring the world economy to a halt, necessitating dynamic lockdown policies that incorporate the healthcare resource budget of people in a zone. We conceive a dynamic pandemic lockdown strategy that employs reinforcement learning to modulate the zone mobility, while restricting the COVID-19 hospitalizations within its healthcare resource budget. We employ queueing theory to model the inflow and outflow of patients and validate the approach through extensive simulation on real demographic and epidemiological data from the boroughs of New York City. Our experiments demonstrate that this approach can not only adapt to the varying trends in contagion in a region by regulating its own lockdown level, but also manages the overheads associated with time-varying dynamic lockdown policies.
新冠疫情是现代人类历史上最致命的大流行病之一,已导致近百万人死亡,并迅速耗尽了全球的医疗资源。当前为遏制感染传播而采取的封锁措施有可能使世界经济陷入停滞,因此需要制定动态封锁政策,将某地区民众的医疗资源预算考虑在内。我们构想了一种动态疫情封锁策略,该策略运用强化学习来调节地区流动性,同时将新冠住院人数控制在其医疗资源预算范围内。我们运用排队论对患者的流入和流出进行建模,并通过对纽约市各行政区真实人口和流行病学数据进行广泛模拟来验证该方法。我们的实验表明,这种方法不仅可以通过调整自身的封锁级别来适应地区内不断变化的传染趋势,还能管理与时变动态封锁政策相关的管理费用。