Korolev Ivan
Department of Economics, Binghamton University, 4400 Vestal Parkway East, PO Box 6000, Binghamton, NY 13902-6000, USA.
J Econom. 2021 Jan;220(1):63-85. doi: 10.1016/j.jeconom.2020.07.038. Epub 2020 Jul 30.
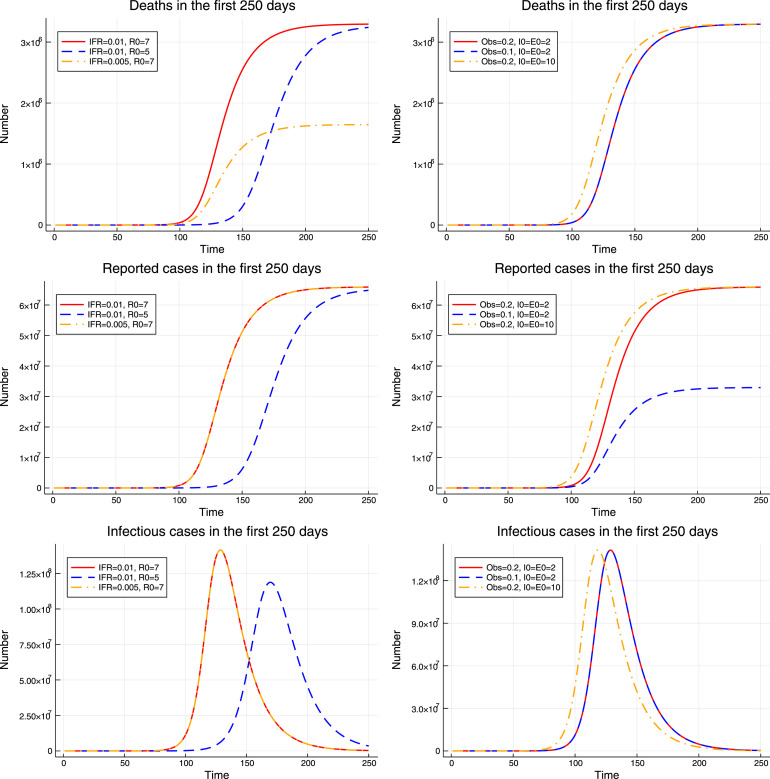
This paper studies the SEIRD epidemic model for COVID-19. First, I show that the model is poorly identified from the observed number of deaths and confirmed cases. There are many sets of parameters that are observationally equivalent in the short run but lead to markedly different long run forecasts. Second, I show that the basic reproduction number can be identified from the data, conditional on epidemiologic parameters, and propose several nonlinear SUR approaches to estimate . I examine the performance of these methods using Monte Carlo studies and demonstrate that they yield fairly accurate estimates of . Next, I apply these methods to estimate for the US, California, and Japan, and document heterogeneity in the value of across regions. My estimation approach accounts for possible underreporting of the number of cases. I demonstrate that if one fails to take underreporting into account and estimates from the reported cases data, the resulting estimate of may be biased downward and the resulting forecasts may exaggerate the long run number of deaths. Finally, I discuss how auxiliary information from random tests can be used to calibrate the initial parameters of the model and narrow down the range of possible forecasts of the future number of deaths.
本文研究了新冠肺炎的SEIRD流行模型。首先,我表明该模型从观察到的死亡人数和确诊病例数来看识别性较差。有许多参数集在短期内观察上是等效的,但会导致明显不同的长期预测。其次,我表明基本再生数可以根据数据,在流行病学参数的条件下进行识别,并提出了几种非线性SUR方法来估计。我使用蒙特卡罗研究检验了这些方法的性能,并证明它们能得出相当准确的估计值。接下来,我应用这些方法来估计美国、加利福尼亚州和日本的,记录各地区值的异质性。我的估计方法考虑了病例数可能漏报的情况。我证明,如果不考虑漏报情况,从报告的病例数据中估计,得到的估计值可能会向下偏倚,并且得到的预测可能会夸大长期死亡人数。最后,我讨论了如何利用随机检测的辅助信息来校准模型的初始参数,并缩小未来死亡人数可能预测的范围。