Centre for Speech and Language Therapy and Hearing Science, Cardiff School of Sport and Health Sciences, Cardiff Metropolitan University, Cardiff, UK.
Center for Rehabilitative Auditory Research, Guizhou Provincial People's Hospital, Guiyang, China.
Int Arch Occup Environ Health. 2021 Jul;94(5):1097-1111. doi: 10.1007/s00420-020-01648-w. Epub 2021 Jan 25.
Noise-induced hearing loss (NIHL) is a global issue that impacts people's life and health. The current review aims to clarify the contributions and limitations of applying machine learning (ML) to predict NIHL by analyzing the performance of different ML techniques and the procedure of model construction.
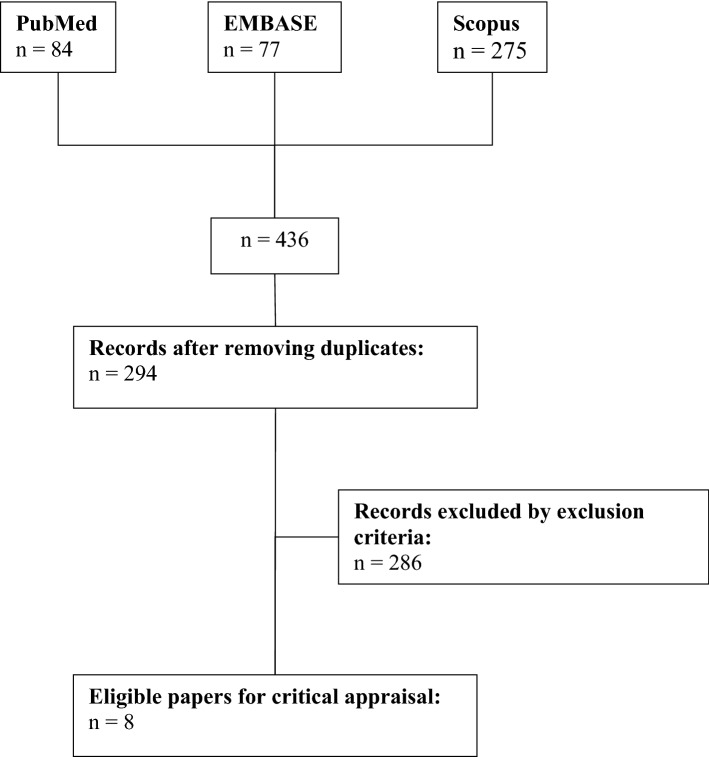
The authors searched PubMed, EMBASE and Scopus on November 26, 2020.
Eight studies were recruited in the current review following defined inclusion and exclusion criteria. Sample size in the selected studies ranged between 150 and 10,567. The most popular models were artificial neural networks (n = 4), random forests (n = 3) and support vector machines (n = 3). Features mostly correlated with NIHL and used in the models were: age (n = 6), duration of noise exposure (n = 5) and noise exposure level (n = 4). Five included studies used either split-sample validation (n = 3) or ten-fold cross-validation (n = 2). Assessment of accuracy ranged in value from 75.3% to 99% with a low prediction error/root-mean-square error in 3 studies. Only 2 studies measured discrimination risk using the receiver operating characteristic (ROC) curve and/or the area under ROC curve.
In spite of high accuracy and low prediction error of machine learning models, some improvement can be expected from larger sample sizes, multiple algorithm use, completed reports of model construction and the sufficient evaluation of calibration and discrimination risk.
噪声性听力损失(NIHL)是一个全球性问题,影响着人们的生活和健康。本综述旨在通过分析不同机器学习(ML)技术的性能和模型构建过程,阐明应用 ML 预测 NIHL 的贡献和局限性。
作者于 2020 年 11 月 26 日在 PubMed、EMBASE 和 Scopus 上进行了检索。
本综述共纳入了 8 项符合纳入和排除标准的研究。入选研究的样本量范围为 150 至 10567。最受欢迎的模型是人工神经网络(n=4)、随机森林(n=3)和支持向量机(n=3)。与 NIHL 相关性最强且用于模型中的特征包括:年龄(n=6)、噪声暴露持续时间(n=5)和噪声暴露水平(n=4)。有 5 项研究分别使用了拆分样本验证(n=3)或 10 折交叉验证(n=2)。有 3 项研究评估准确性的范围值从 75.3%到 99%,预测误差/均方根误差较低。仅有 2 项研究使用接收者操作特征(ROC)曲线和/或 ROC 曲线下面积来衡量判别风险。
尽管机器学习模型具有较高的准确性和较低的预测误差,但可以通过增加样本量、使用多种算法、完整报告模型构建过程以及充分评估校准和判别风险来进一步提高。