Rybinski Maciej, Dai Xiang, Singh Sonit, Karimi Sarvnaz, Nguyen Anthony
Commonwealth Scientific and Industrial Research Organisation, Sydney, Australia.
University of Sydney, Sydney, Australia.
JMIR Med Inform. 2021 Apr 30;9(4):e24020. doi: 10.2196/24020.
The prognosis, diagnosis, and treatment of many genetic disorders and familial diseases significantly improve if the family history (FH) of a patient is known. Such information is often written in the free text of clinical notes.
The aim of this study is to develop automated methods that enable access to FH data through natural language processing.
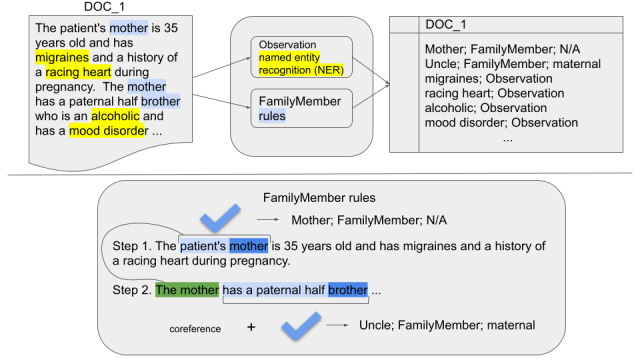
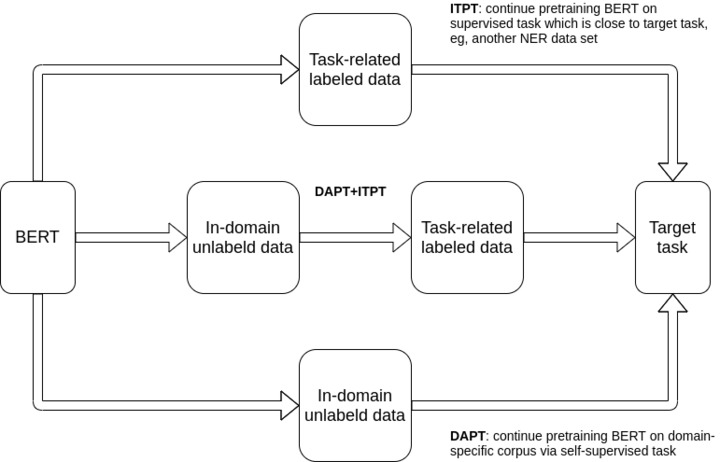
We performed information extraction by using transformers to extract disease mentions from notes. We also experimented with rule-based methods for extracting family member (FM) information from text and coreference resolution techniques. We evaluated different transfer learning strategies to improve the annotation of diseases. We provided a thorough error analysis of the contributing factors that affect such information extraction systems.
Our experiments showed that the combination of domain-adaptive pretraining and intermediate-task pretraining achieved an F1 score of 81.63% for the extraction of diseases and FMs from notes when it was tested on a public shared task data set from the National Natural Language Processing Clinical Challenges (N2C2), providing a statistically significant improvement over the baseline (P<.001). In comparison, in the 2019 N2C2/Open Health Natural Language Processing Shared Task, the median F1 score of all 17 participating teams was 76.59%.
Our approach, which leverages a state-of-the-art named entity recognition model for disease mention detection coupled with a hybrid method for FM mention detection, achieved an effectiveness that was close to that of the top 3 systems participating in the 2019 N2C2 FH extraction challenge, with only the top system convincingly outperforming our approach in terms of precision.
如果已知患者的家族病史(FH),许多遗传疾病和家族性疾病的预后、诊断和治疗将得到显著改善。此类信息通常写在临床记录的自由文本中。
本研究的目的是开发通过自然语言处理获取FH数据的自动化方法。
我们使用变压器从记录中提取疾病提及来进行信息提取。我们还试验了基于规则的方法从文本中提取家庭成员(FM)信息以及共指消解技术。我们评估了不同的迁移学习策略以改善疾病标注。我们对影响此类信息提取系统的因素进行了全面的错误分析。
我们的实验表明,当在来自国家自然语言处理临床挑战(N2C2)的公共共享任务数据集上进行测试时,领域自适应预训练和中间任务预训练的组合在从记录中提取疾病和FM方面的F1分数达到了81.63%,与基线相比有统计学显著改善(P<.001)。相比之下,在2019年N2C2/开放健康自然语言处理共享任务中,所有17个参与团队的中位数F1分数为76.59%。
我们的方法利用最先进的命名实体识别模型进行疾病提及检测,并结合混合方法进行FM提及检测,其有效性接近参与2019年N2C2 FH提取挑战的前3个系统,只有顶级系统在精度方面明显优于我们的方法。