Yousef Ahmed M, Deliyski Dimitar D, Zacharias Stephanie R C, de Alarcon Alessandro, Orlikoff Robert F, Naghibolhosseini Maryam
Department of Communicative Sciences and Disorders, Michigan State University, East Lansing, MI 48824, USA.
Head and Neck Regenerative Medicine Program, Mayo Clinic, Scottsdale, AZ 85259, and Department of Otolaryngology-Head and Neck Surgery, Mayo Clinic, Phoenix, AZ 85054, USA.
Appl Sci (Basel). 2021 Feb;11(3). doi: 10.3390/app11031179. Epub 2021 Jan 27.
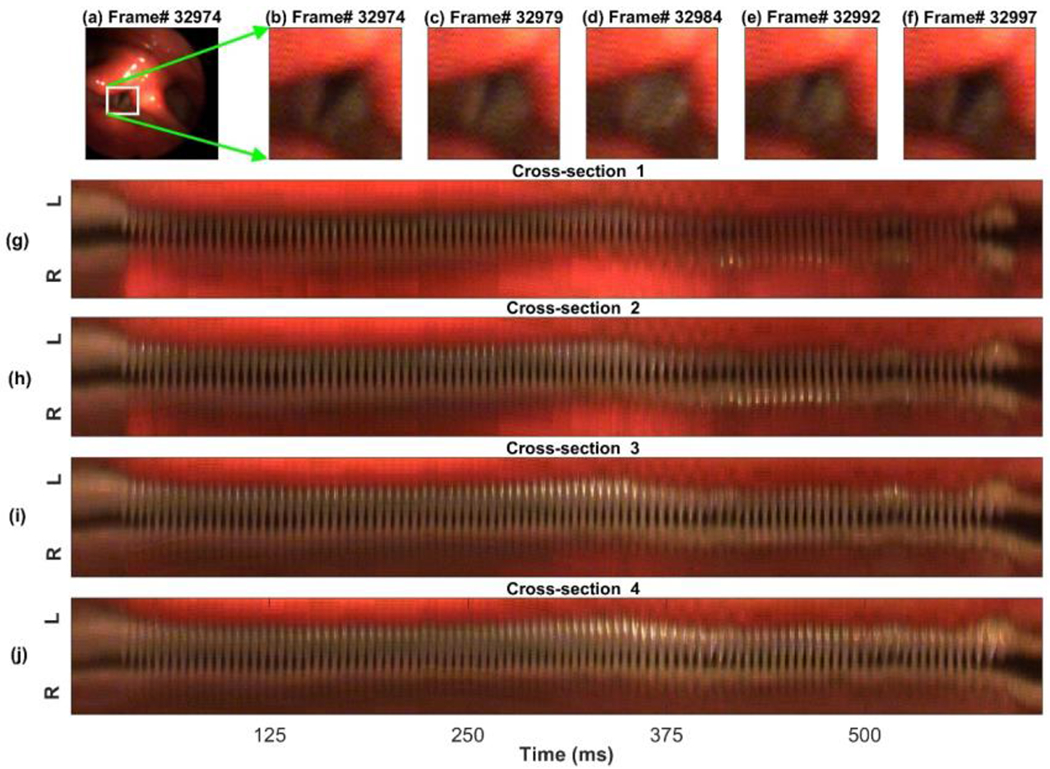
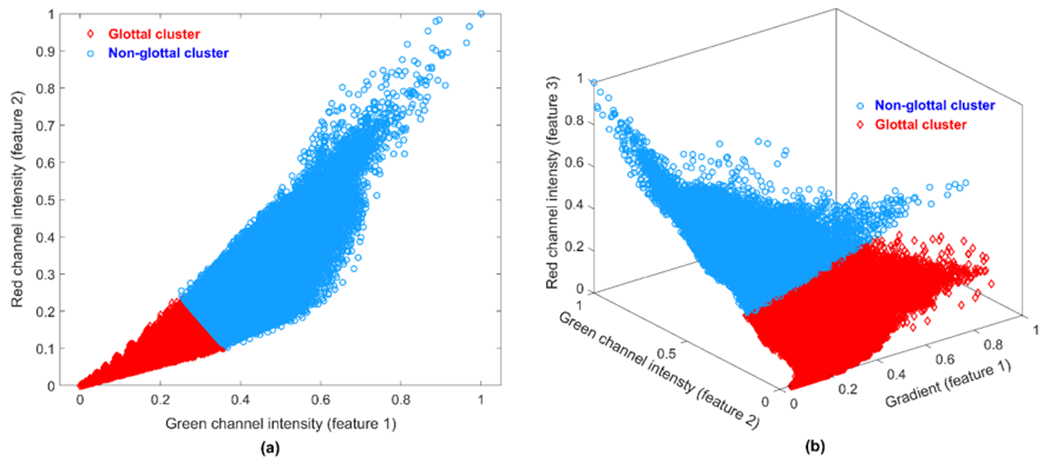
Investigating the phonatory processes in connected speech from high-speed videoendoscopy (HSV) demands the accurate detection of the vocal fold edges during vibration. The present paper proposes a new spatio-temporal technique to automatically segment vocal fold edges in HSV data during running speech. The HSV data were recorded from a vocally normal adult during a reading of the "Rainbow Passage." The introduced technique was based on an unsupervised machine-learning (ML) approach combined with an active contour modeling (ACM) technique (also known as a hybrid approach). The hybrid method was implemented to capture the edges of vocal folds on different HSV kymograms, extracted at various cross-sections of vocal folds during vibration. The k-means clustering method, an ML approach, was first applied to cluster the kymograms to identify the clustered glottal area and consequently provided an initialized contour for the ACM. The ACM algorithm was then used to precisely detect the glottal edges of the vibrating vocal folds. The developed algorithm was able to accurately track the vocal fold edges across frames with low computational cost and high robustness against image noise. This algorithm offers a fully automated tool for analyzing the vibratory features of vocal folds in connected speech.
利用高速视频内镜(HSV)研究连贯语音中的发声过程需要在振动过程中准确检测声带边缘。本文提出了一种新的时空技术,用于在连续语音期间自动分割HSV数据中的声带边缘。HSV数据是在一名嗓音正常的成年人朗读《彩虹篇章》时记录的。所介绍的技术基于一种无监督机器学习(ML)方法与主动轮廓建模(ACM)技术相结合(也称为混合方法)。实施该混合方法以捕捉不同HSV波形图上的声带边缘,这些波形图是在振动期间从声带的各个横截面提取的。首先应用ML方法中的k均值聚类方法对波形图进行聚类,以识别聚类的声门区域,从而为ACM提供初始化轮廓。然后使用ACM算法精确检测振动声带的声门边缘。所开发的算法能够以低计算成本跨帧准确跟踪声带边缘,并且对图像噪声具有高鲁棒性。该算法为分析连贯语音中声带的振动特征提供了一个完全自动化的工具。