Division of Phoniatrics and Pediatric Audiology, Department of Otorhinolaryngology, Head and Neck Surgery, University Hospital Erlangen, Friedrich-Alexander University Erlangen-Nürnberg, Waldstraße 1, 91054, Erlangen, Germany.
Department of Head and Neck Surgery, David Geffen School of Medicine at the University of California, Los Angeles, Los Angeles, California, USA.
Sci Data. 2020 Jun 19;7(1):186. doi: 10.1038/s41597-020-0526-3.
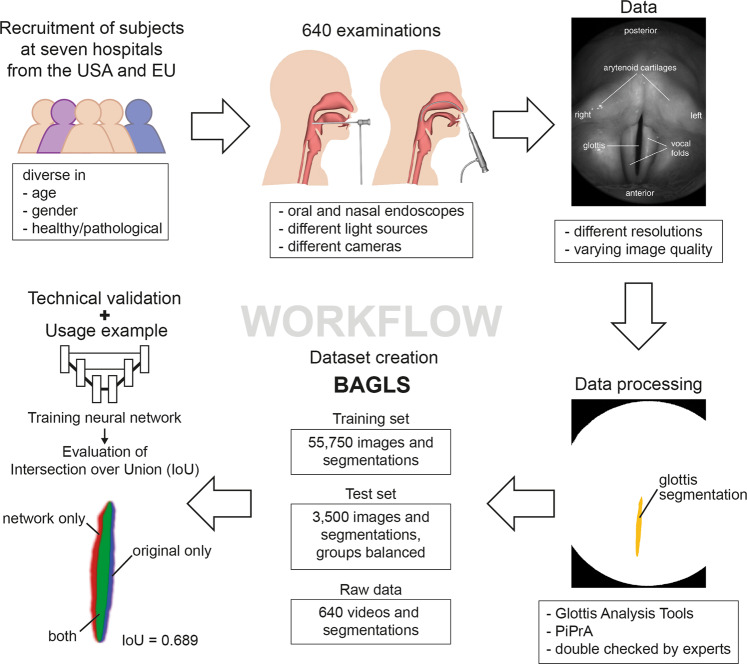
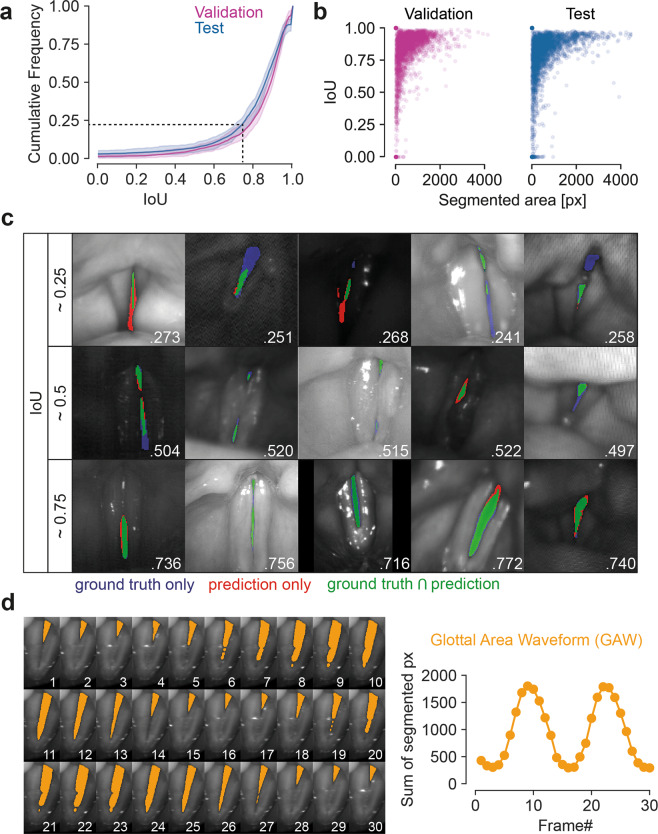
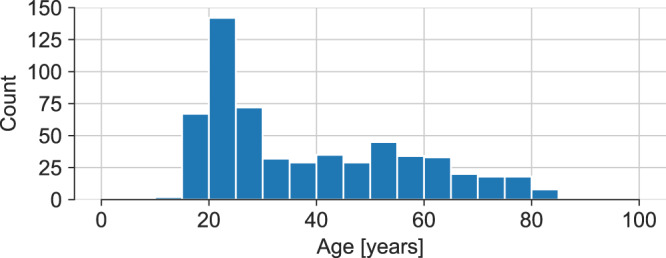
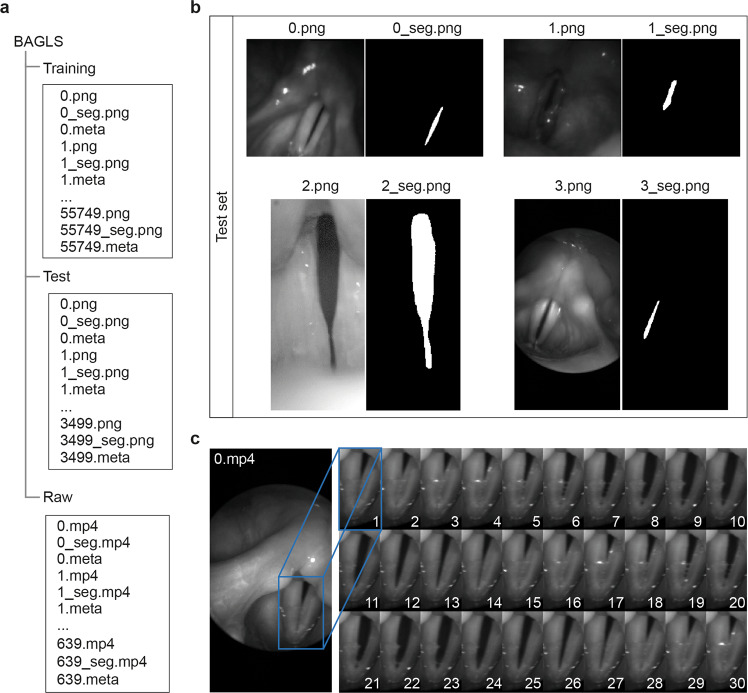
Laryngeal videoendoscopy is one of the main tools in clinical examinations for voice disorders and voice research. Using high-speed videoendoscopy, it is possible to fully capture the vocal fold oscillations, however, processing the recordings typically involves a time-consuming segmentation of the glottal area by trained experts. Even though automatic methods have been proposed and the task is particularly suited for deep learning methods, there are no public datasets and benchmarks available to compare methods and to allow training of generalizing deep learning models. In an international collaboration of researchers from seven institutions from the EU and USA, we have created BAGLS, a large, multihospital dataset of 59,250 high-speed videoendoscopy frames with individually annotated segmentation masks. The frames are based on 640 recordings of healthy and disordered subjects that were recorded with varying technical equipment by numerous clinicians. The BAGLS dataset will allow an objective comparison of glottis segmentation methods and will enable interested researchers to train their own models and compare their methods.
喉视频内窥镜检查是嗓音障碍和嗓音研究临床检查的主要工具之一。使用高速视频内窥镜检查,我们可以充分捕捉声带的振动,但通常需要经过专业培训的专家来耗时地分割声门区域。尽管已经提出了一些自动方法,并且该任务特别适合深度学习方法,但目前还没有公共数据集和基准可供比较方法并允许训练泛化的深度学习模型。在来自欧盟和美国的七个机构的国际研究人员合作中,我们创建了 BAGLS,这是一个大型、多医院的数据集,包含 59250 个高速视频内窥镜检查帧,每个帧都有单独的标注分割掩模。这些帧基于 640 个健康和患病受试者的记录,由许多临床医生使用不同的技术设备进行录制。BAGLS 数据集将允许对声门分割方法进行客观比较,并使有兴趣的研究人员能够训练自己的模型并比较他们的方法。