Clinical and Applied Genomics Laboratory, Department of Biological Sciences, Aliah University, Kolkata, India
Life Sci Alliance. 2021 Mar 16;4(5). doi: 10.26508/lsa.202000925. Print 2021 May.
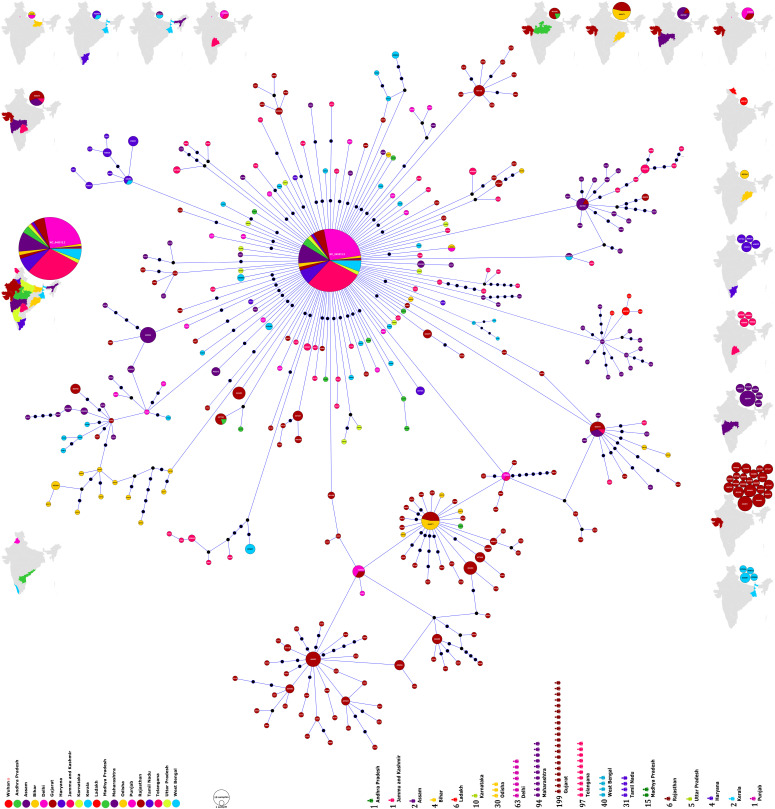
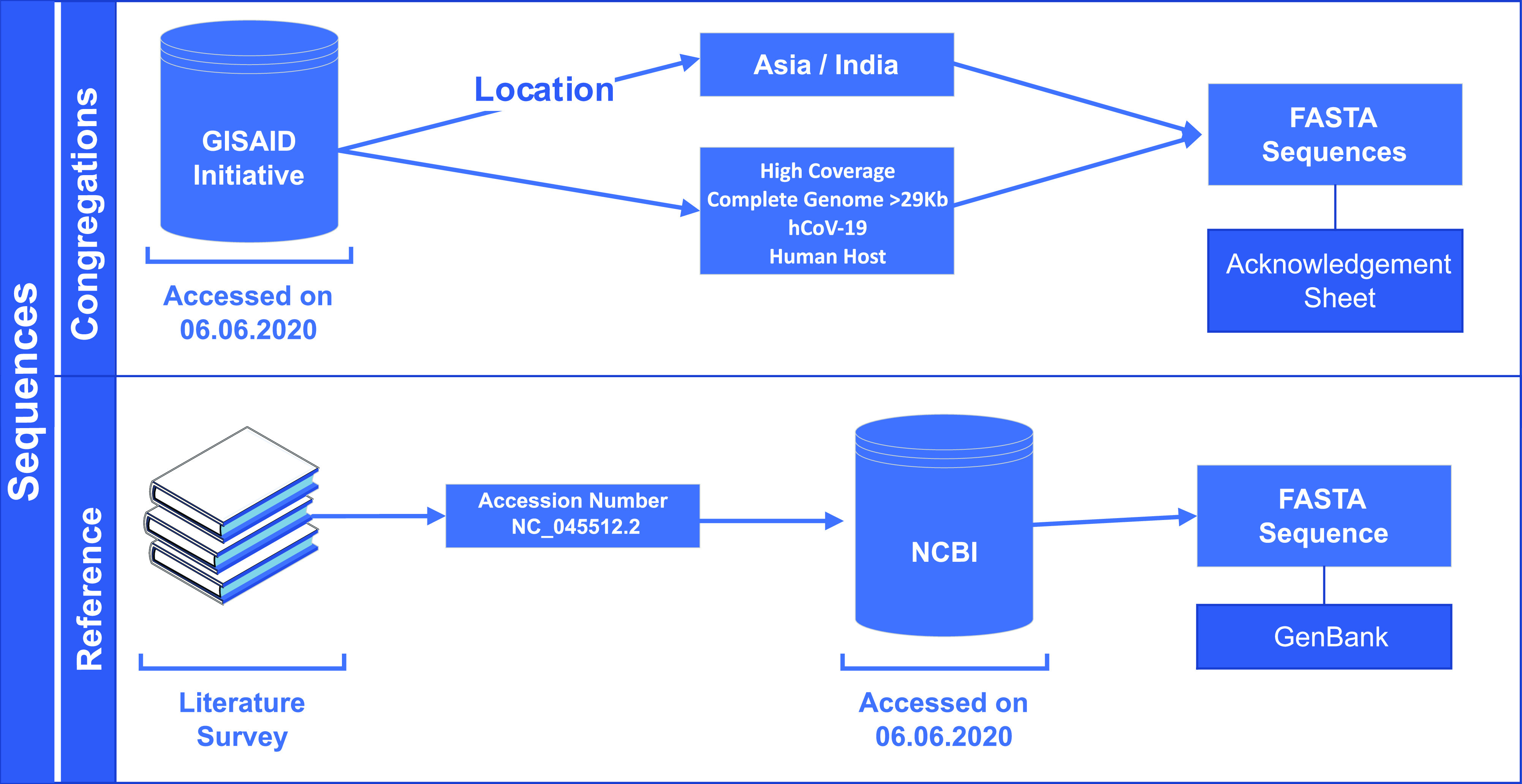
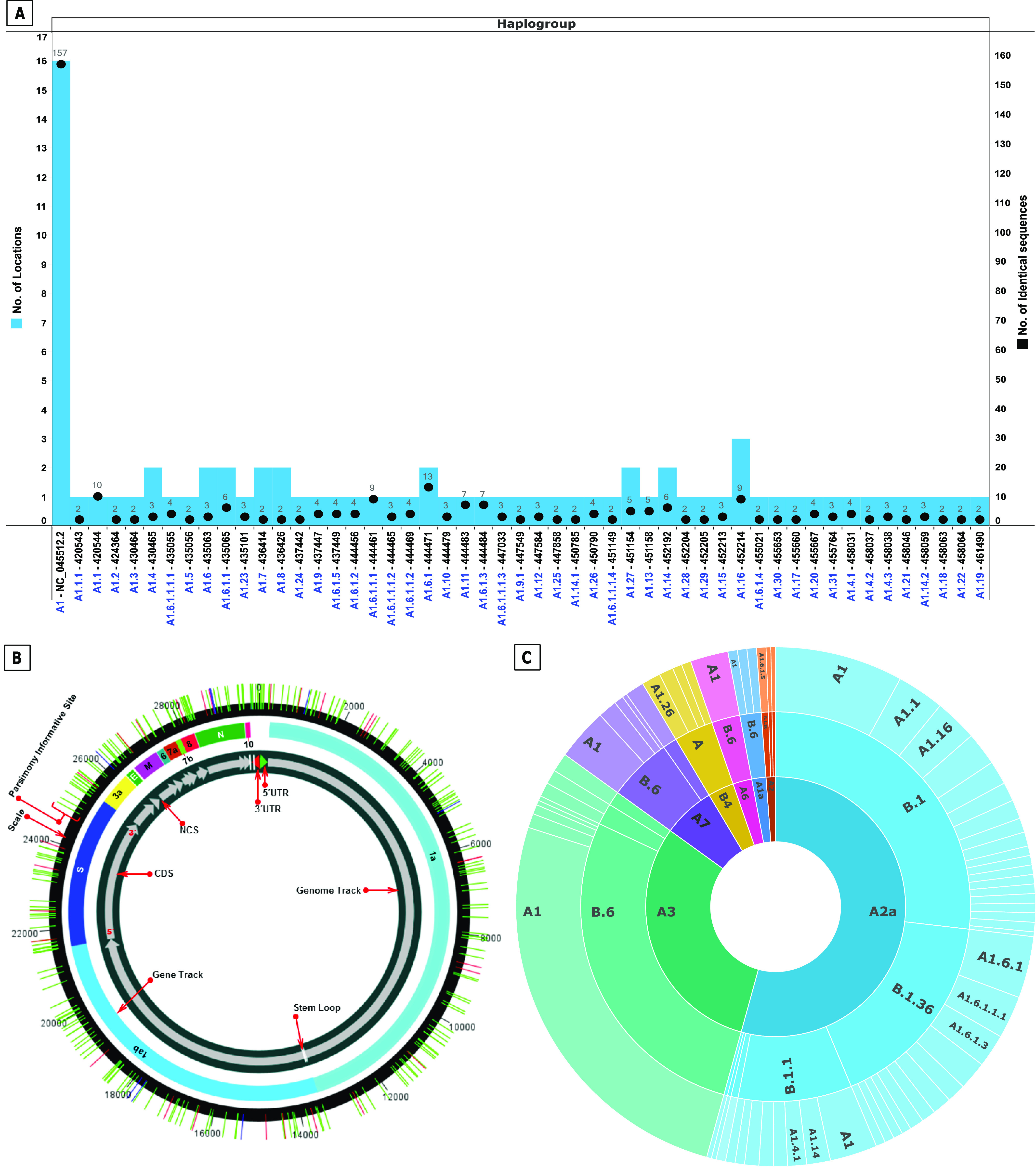
The novel coronavirus (SARS-CoV-2) from Wuhan China discovered in December 2019 has since developed into a global epidemic. Presently, we constructed and analyzed the phylo-geo-network of SARS-CoV-2 genomes from across India to understand the viral evolution in the country. A total of 611 full-length genomes from different states of India were extracted from the EpiCov repository of GISAID initiative on 6 June, 2020. Their alignment with the reference sequence (Wuhan, NCBI accession number NC_045512.2) uncovered 270 parsimony informative sites. Furthermore, 339 genomes were divided into 51 haplogroups. The network revealed the core haplogroup as that of reference sequence NC_045512.2 (Haplogroup A1) with 157 identical sequences present across 16 states. Remaining haplogroups had <10 identical sequences across a maximum of three states. Some states with fewer samples had more haplogroups. Forty-one haplogroups were localized exclusively to any one state. The two most common lineages are B6 and B1 (Pangolin) whereas clade A2a (Covidex) appears to be the most predominant in India. Because the pandemic is still emerging, the observations need to be monitored.
2019 年 12 月在中国武汉发现的新型冠状病毒(SARS-CoV-2)已在全球范围内流行。目前,我们构建并分析了来自印度各地的 SARS-CoV-2 基因组的系统发生地理网络,以了解该国的病毒进化情况。2020 年 6 月 6 日,从 GISAID 倡议的 EpiCov 存储库中提取了来自印度不同邦的 611 条全长基因组,与参考序列(武汉,NCBI 登录号 NC_045512.2)进行比对,共发现 270 个简约信息位。此外,339 条基因组分为 51 个单倍型群。网络显示核心单倍型群为参考序列 NC_045512.2(单倍型群 A1),在 16 个邦中有 157 个相同序列。其余单倍型群在最多三个邦中只有不到 10 个相同序列。一些样本较少的邦具有更多的单倍型群。41 个单倍型群仅存在于任何一个邦。两个最常见的谱系是 B6 和 B1(穿山甲),而 A2a 谱系(Covidex)似乎在印度最为普遍。由于大流行仍在出现,需要对这些观察结果进行监测。