Mehltretter Joseph, Rollins Colleen, Benrimoh David, Fratila Robert, Perlman Kelly, Israel Sonia, Miresco Marc, Wakid Marina, Turecki Gustavo
Department of Computer Science, University of Southern California, Los Angeles, CA, United States.
Department of Psychiatry, University of Cambridge, Cambridge, United Kingdom.
Front Artif Intell. 2020 Jan 21;2:31. doi: 10.3389/frai.2019.00031. eCollection 2019.
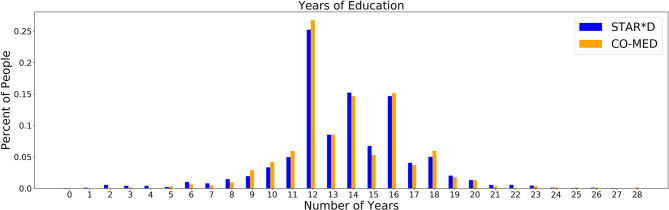
Deep learning has utility in predicting differential antidepressant treatment response among patients with major depressive disorder, yet there remains a paucity of research describing how to interpret deep learning models in a clinically or etiologically meaningful way. In this paper, we describe methods for analyzing deep learning models of clinical and demographic psychiatric data, using our recent work on a deep learning model of STARD and CO-MED remission prediction. Our deep learning analysis with STARD and CO-MED yielded four models that predicted response to the four treatments used across the two datasets. Here, we use classical statistics and simple data representations to improve interpretability of the features output by our deep learning model and provide finer grained understanding of their clinical and etiological significance. Specifically, we use representations derived from our model to yield features predicting both treatment non-response and differential treatment response to four standard antidepressants, and use linear regression and -tests to address questions about the contribution of trauma, education, and somatic symptoms to our models. Traditional statistics were able to probe the input features of our deep learning models, reproducing results from previous research, while providing novel insights into depression causes and treatments. We found that specific features were predictive of treatment response, and were able to break these down by treatment and non-response categories; that specific trauma indices were differentially predictive of baseline depression severity; that somatic symptoms were significantly different between males and females, and that education and low income proved important psycho-social stressors associated with depression. Traditional statistics can augment interpretation of deep learning models. Such interpretation can lend us new hypotheses about depression and contribute to building causal models of etiology and prognosis. We discuss dataset-specific effects and ideal clinical samples for machine learning analysis aimed at improving tools to assist in optimizing treatment.
深度学习在预测重度抑郁症患者的不同抗抑郁治疗反应方面具有实用性,但仍缺乏以临床或病因学上有意义的方式描述如何解释深度学习模型的研究。在本文中,我们描述了分析临床和人口统计学精神病学数据深度学习模型的方法,采用了我们最近关于STARD和CO-MED缓解预测深度学习模型的研究成果。我们对STARD和CO-MED进行的深度学习分析产生了四个模型,这些模型预测了两个数据集中使用的四种治疗方法的反应。在这里,我们使用经典统计和简单的数据表示来提高深度学习模型输出特征的可解释性,并更深入地理解其临床和病因学意义。具体而言,我们使用从模型中导出的表示来生成预测对四种标准抗抑郁药治疗无反应和不同治疗反应的特征,并使用线性回归和检验来解决关于创伤、教育和躯体症状对我们模型贡献的问题。传统统计能够探究我们深度学习模型的输入特征,重现先前研究的结果,同时为抑郁症的病因和治疗提供新的见解。我们发现特定特征可预测治疗反应,并能够按治疗和无反应类别进行分解;特定的创伤指数对基线抑郁严重程度有不同的预测作用;躯体症状在男性和女性之间存在显著差异,并且教育程度和低收入被证明是与抑郁症相关的重要社会心理压力源。传统统计可以增强对深度学习模型的解释。这种解释可以为我们提供关于抑郁症的新假设,并有助于建立病因学和预后的因果模型。我们讨论了针对特定数据集的影响以及用于机器学习分析的理想临床样本,旨在改进工具以协助优化治疗。