Berkeley Institute for Data Science, University of California Berkeley, Berkeley, California, United States of America.
Statistical & Data Sciences Program, Smith College, Northampton, Massachusetts, United States of America.
PLoS Comput Biol. 2021 Mar 18;17(3):e1008770. doi: 10.1371/journal.pcbi.1008770. eCollection 2021 Mar.
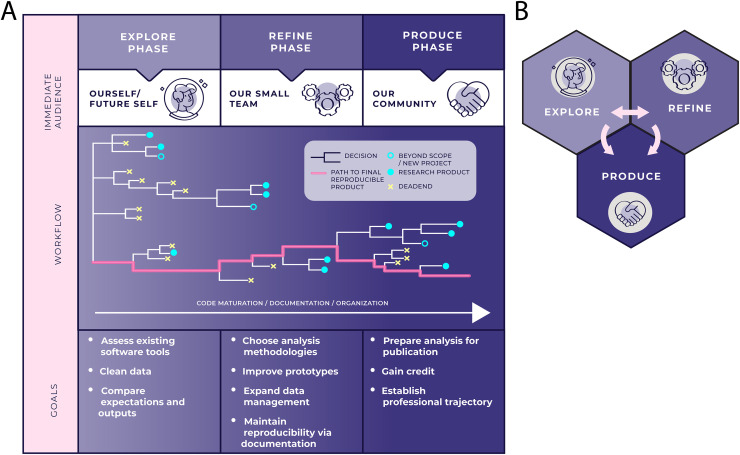
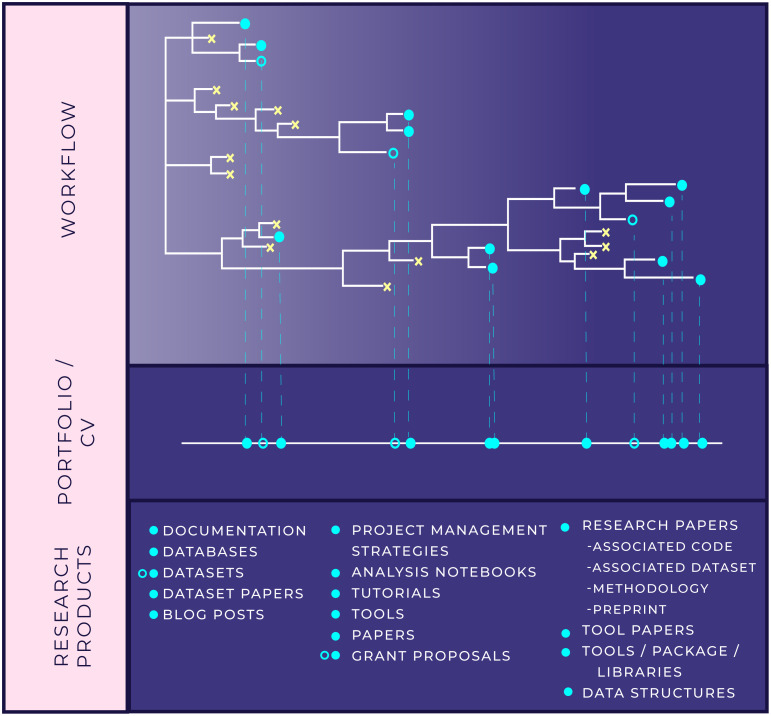
A systematic and reproducible "workflow"-the process that moves a scientific investigation from raw data to coherent research question to insightful contribution-should be a fundamental part of academic data-intensive research practice. In this paper, we elaborate basic principles of a reproducible data analysis workflow by defining 3 phases: the Explore, Refine, and Produce Phases. Each phase is roughly centered around the audience to whom research decisions, methodologies, and results are being immediately communicated. Importantly, each phase can also give rise to a number of research products beyond traditional academic publications. Where relevant, we draw analogies between design principles and established practice in software development. The guidance provided here is not intended to be a strict rulebook; rather, the suggestions for practices and tools to advance reproducible, sound data-intensive analysis may furnish support for both students new to research and current researchers who are new to data-intensive work.
一个系统的、可重复的“工作流程”——将科学研究从原始数据转化为连贯的研究问题并得出有见地的贡献的过程——应该是学术数据密集型研究实践的基本组成部分。在本文中,我们通过定义三个阶段来详细阐述可重复数据分析工作流程的基本原则:探索阶段、精炼阶段和产出阶段。每个阶段大致以正在即时交流研究决策、方法和结果的受众为中心。重要的是,每个阶段还可以产生许多超出传统学术出版物的研究产品。在相关的地方,我们还借鉴了软件开发中既定设计原则和实践之间的类比。这里提供的指导意见并非严格的规则手册;相反,推进可重复的、合理的数据密集型分析的实践和工具建议,可以为新接触研究的学生和新接触数据密集型工作的现有研究人员提供支持。