Department of Pathology, Massachusetts General Hospital, 501 Warren Bldg, 55 Fruit Street, Boston, MA, 02114, USA.
BMC Med Genomics. 2021 Mar 19;14(1):86. doi: 10.1186/s12920-021-00891-5.
RNA gene expression of renal transplantation biopsies is commonly used to identify the immunological patterns of graft rejection. Mostly done with microarrays, seminal findings defined the patterns of gene sets associated with rejection and non-rejection kidney allograft diagnoses. To make gene expression more accessible, the Molecular Diagnostics Working Group of the Banff Foundation for Allograft Pathology and NanoString Technologies partnered to create the Banff Human Organ Transplant Panel (BHOT), a gene panel set of 770 genes as a surrogate for microarrays (~ 50,000 genes). The advantage of this platform is that gene expressions are quantifiable on formalin fixed and paraffin embedded archival tissue samples, making gene expression analyses more accessible. The purpose of this report is to test in silico the utility of the BHOT panel as a surrogate for microarrays on archival microarray data and test the performance of the modelled BHOT data.
BHOT genes as a subset of genes from downloaded archival public microarray data on human renal allograft gene expression were analyzed and modelled by a variety of statistical methods.
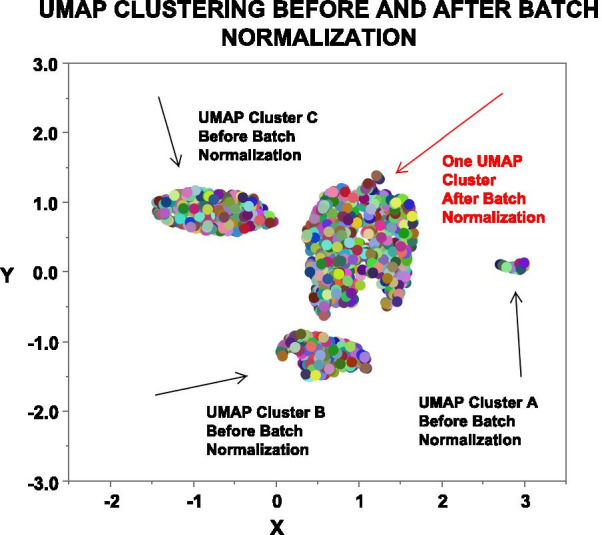
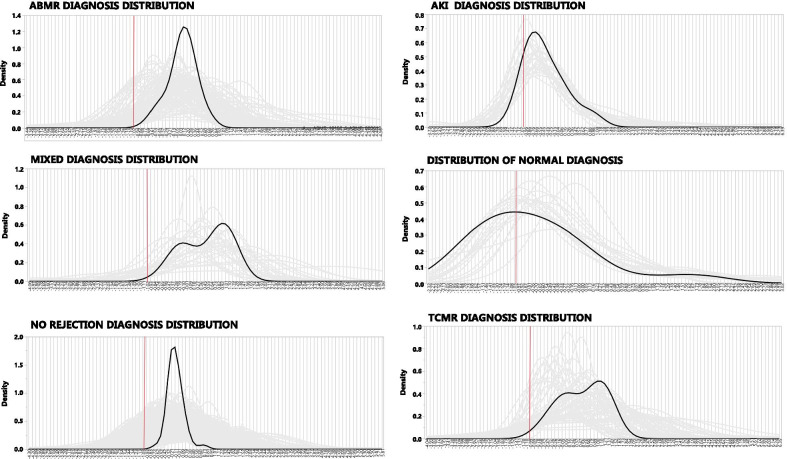
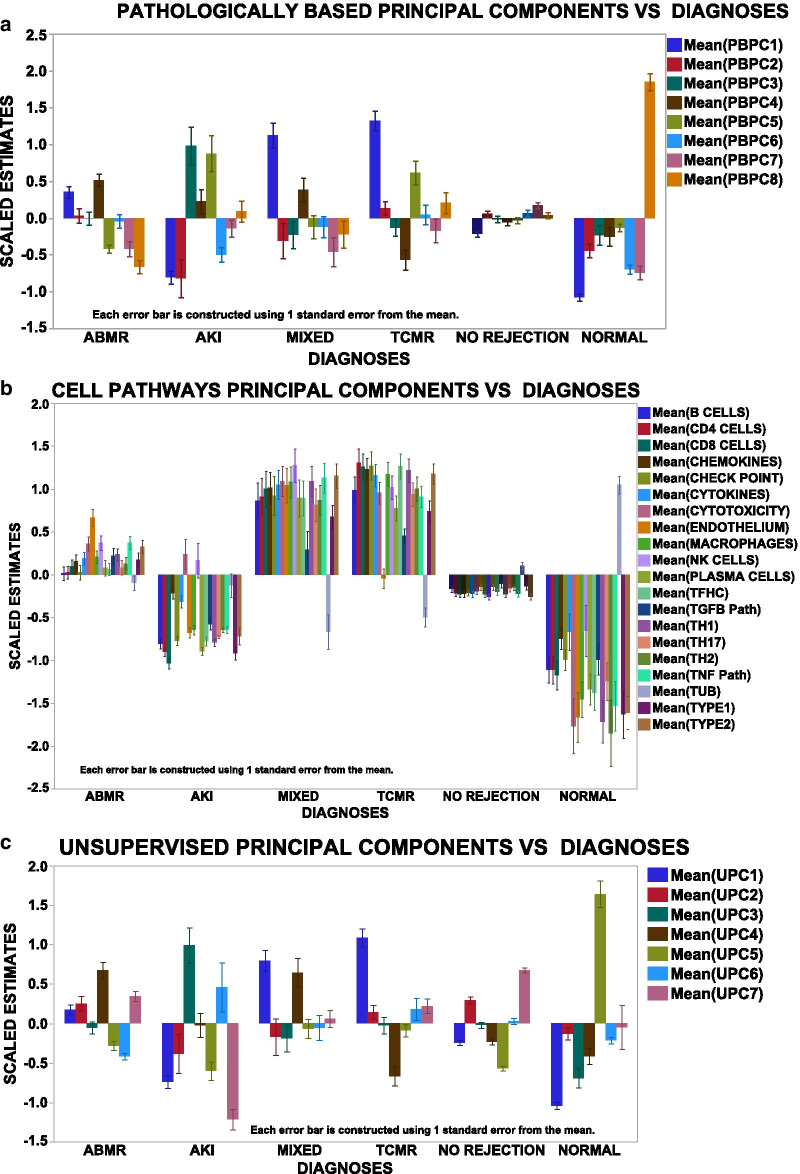
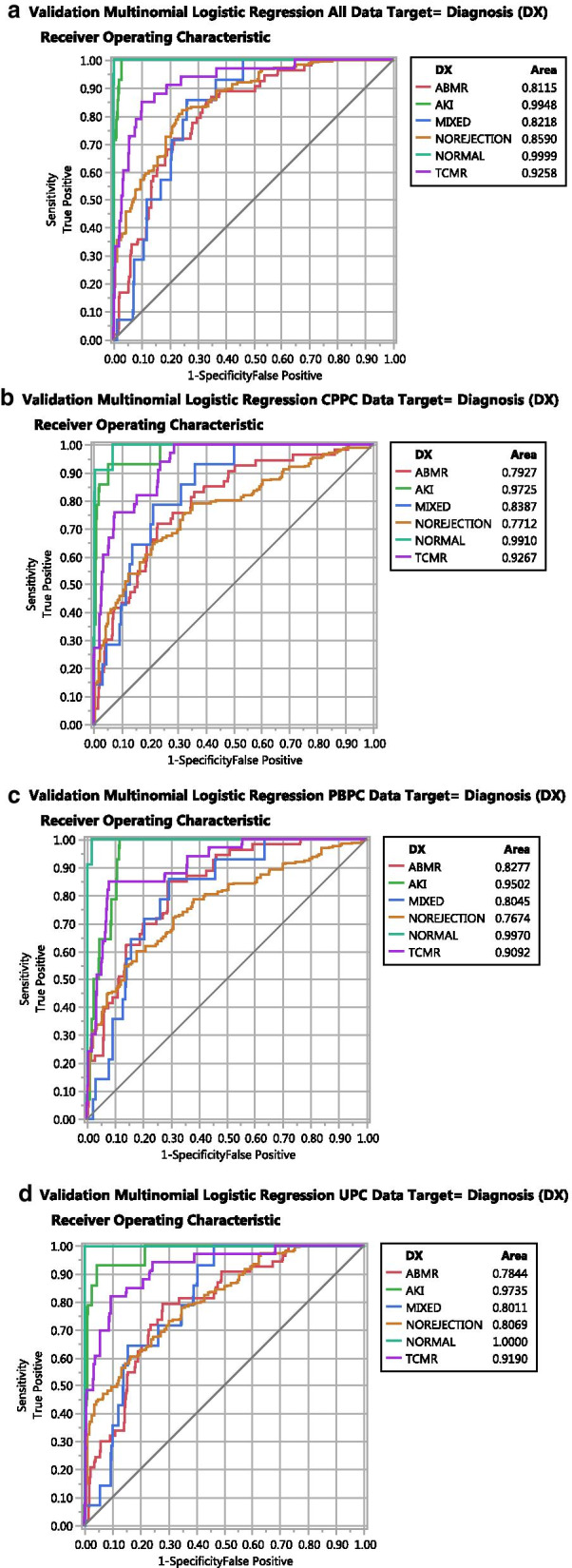
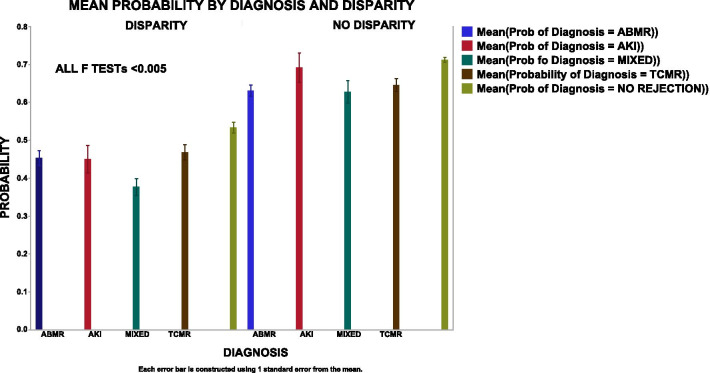
Three methods of parsing genes verify that the BHOT panel readily identifies renal rejection and non-rejection diagnoses using in silico statistical analyses of seminal archival databases. Multiple modelling algorithms show a highly variable pattern of misclassifications per sample, either between differently constructed principal components or between modelling algorithms. The misclassifications are related to the gene expression heterogeneity within a given diagnosis because clustering the data into 9 groups modelled with fewer misclassifications.
This report supports using the Banff Human Organ Transplant Panel for gene expression of human renal allografts as a surrogate for microarrays on archival tissue. The data modelled satisfactorily with aggregate diagnoses although with limited per sample accuracy and, thereby, reflects and confirms the modelling complexity and the challenges of modelling gene expression as previously reported.
肾移植活检的 RNA 基因表达常用于鉴定移植物排斥的免疫学模式。主要通过微阵列进行,开创性的发现定义了与排斥和非排斥肾移植诊断相关的基因集模式。为了使基因表达更易于使用,Banff 移植病理学基金会的分子诊断工作组和 NanoString 技术合作创建了 Banff 人类器官移植面板 (BHOT),这是一个由 770 个基因组成的基因面板集,作为微阵列的替代品(~50,000 个基因)。该平台的优势在于可以对福尔马林固定和石蜡包埋的存档组织样本进行基因表达的定量分析,从而使基因表达分析更加容易。本报告的目的是在存档的微阵列数据上进行 BHOT 面板作为微阵列替代物的计算机模拟,并测试建模的 BHOT 数据的性能。
通过各种统计方法对 BHOT 基因作为从人类肾移植基因表达存档公共微阵列数据中下载的基因子集进行分析和建模。
三种基因解析方法验证了 BHOT 面板可以通过对有开创性的存档数据库的计算机统计分析,轻松识别肾移植排斥和非排斥诊断。多种建模算法显示每个样本的错误分类模式高度可变,无论是在不同构建的主成分之间,还是在建模算法之间。错误分类与给定诊断中的基因表达异质性有关,因为将数据聚类成 9 个组进行建模可减少错误分类。
本报告支持使用 Banff 人类器官移植面板作为存档组织上的微阵列替代物进行人类肾移植的基因表达。虽然每个样本的准确性有限,但数据用综合诊断建模令人满意,从而反映并确认了之前报道的建模复杂性和基因表达建模的挑战。