Christodoulou Evangelia, van Smeden Maarten, Edlinger Michael, Timmerman Dirk, Wanitschek Maria, Steyerberg Ewout W, Van Calster Ben
Department of Development & Regeneration, KU Leuven, Leuven, Belgium.
Julius Center for Health Sciences and Primary Care, University Medical Center Utrecht, Utrecht, Netherlands.
Diagn Progn Res. 2021 Mar 22;5(1):6. doi: 10.1186/s41512-021-00096-5.
We suggest an adaptive sample size calculation method for developing clinical prediction models, in which model performance is monitored sequentially as new data comes in.
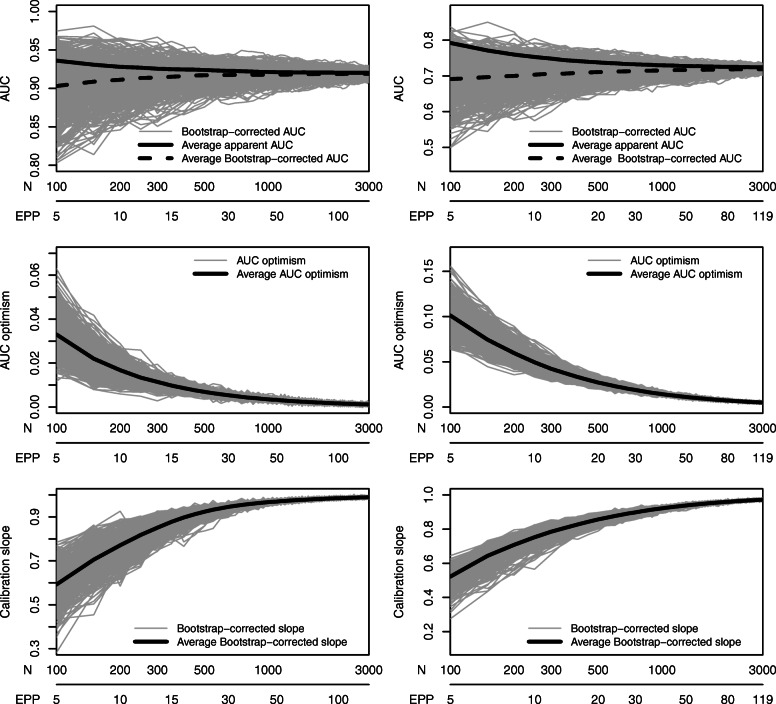
We illustrate the approach using data for the diagnosis of ovarian cancer (n = 5914, 33% event fraction) and obstructive coronary artery disease (CAD; n = 4888, 44% event fraction). We used logistic regression to develop a prediction model consisting only of a priori selected predictors and assumed linear relations for continuous predictors. We mimicked prospective patient recruitment by developing the model on 100 randomly selected patients, and we used bootstrapping to internally validate the model. We sequentially added 50 random new patients until we reached a sample size of 3000 and re-estimated model performance at each step. We examined the required sample size for satisfying the following stopping rule: obtaining a calibration slope ≥ 0.9 and optimism in the c-statistic (or AUC) < = 0.02 at two consecutive sample sizes. This procedure was repeated 500 times. We also investigated the impact of alternative modeling strategies: modeling nonlinear relations for continuous predictors and correcting for bias on the model estimates (Firth's correction).
Better discrimination was achieved in the ovarian cancer data (c-statistic 0.9 with 7 predictors) than in the CAD data (c-statistic 0.7 with 11 predictors). Adequate calibration and limited optimism in discrimination was achieved after a median of 450 patients (interquartile range 450-500) for the ovarian cancer data (22 events per parameter (EPP), 20-24) and 850 patients (750-900) for the CAD data (33 EPP, 30-35). A stricter criterion, requiring AUC optimism < = 0.01, was met with a median of 500 (23 EPP) and 1500 (59 EPP) patients, respectively. These sample sizes were much higher than the well-known 10 EPP rule of thumb and slightly higher than a recently published fixed sample size calculation method by Riley et al. Higher sample sizes were required when nonlinear relationships were modeled, and lower sample sizes when Firth's correction was used.
Adaptive sample size determination can be a useful supplement to fixed a priori sample size calculations, because it allows to tailor the sample size to the specific prediction modeling context in a dynamic fashion.
我们提出一种用于开发临床预测模型的自适应样本量计算方法,在新数据不断输入时,对模型性能进行序贯监测。
我们使用卵巢癌诊断数据(n = 5914,事件发生率33%)和阻塞性冠状动脉疾病(CAD;n = 4888,事件发生率44%)来说明该方法。我们使用逻辑回归开发一个仅由预先选定的预测因子组成的预测模型,并假设连续预测因子存在线性关系。我们通过在100名随机选择的患者上开发模型来模拟前瞻性患者招募,并使用自助法进行模型内部验证。我们序贯添加50名随机新患者,直至样本量达到3000,并在每一步重新估计模型性能。我们检查满足以下停止规则所需的样本量:在两个连续样本量时获得校准斜率≥0.9且c统计量(或AUC)的乐观度<=0.02。此过程重复500次。我们还研究了替代建模策略的影响:对连续预测因子建模非线性关系以及对模型估计值进行偏差校正(Firth校正)。
卵巢癌数据(7个预测因子时c统计量为0.9)比CAD数据(11个预测因子时c统计量为0.7)实现了更好的区分度。对于卵巢癌数据(每个参数22个事件(EPP),20 - 24),在中位450名患者(四分位间距450 - 500)后实现了充分校准和有限的区分度乐观度;对于CAD数据(33个EPP,30 - 35),在850名患者(750 - 900)后实现。一个更严格的标准,即要求AUC乐观度<=0.01,分别在中位500名(23个EPP)和1500名(59个EPP)患者时满足。这些样本量远高于著名的10个EPP经验法则,且略高于Riley等人最近发表的固定样本量计算方法。当对非线性关系建模时需要更高的样本量,而使用Firth校正时样本量较低。
自适应样本量确定可以作为对固定的先验样本量计算的有用补充,因为它允许以动态方式根据特定的预测建模背景调整样本量。