Institute of Psychiatry, Psychology and Neuroscience, King's College London, London, UK
Department of Computer Science, University of Sheffield, Sheffield, UK.
BMJ Open. 2021 Mar 25;11(3):e042274. doi: 10.1136/bmjopen-2020-042274.
We set out to develop, evaluate and implement a novel application using natural language processing to text mine occupations from the free-text of psychiatric clinical notes.
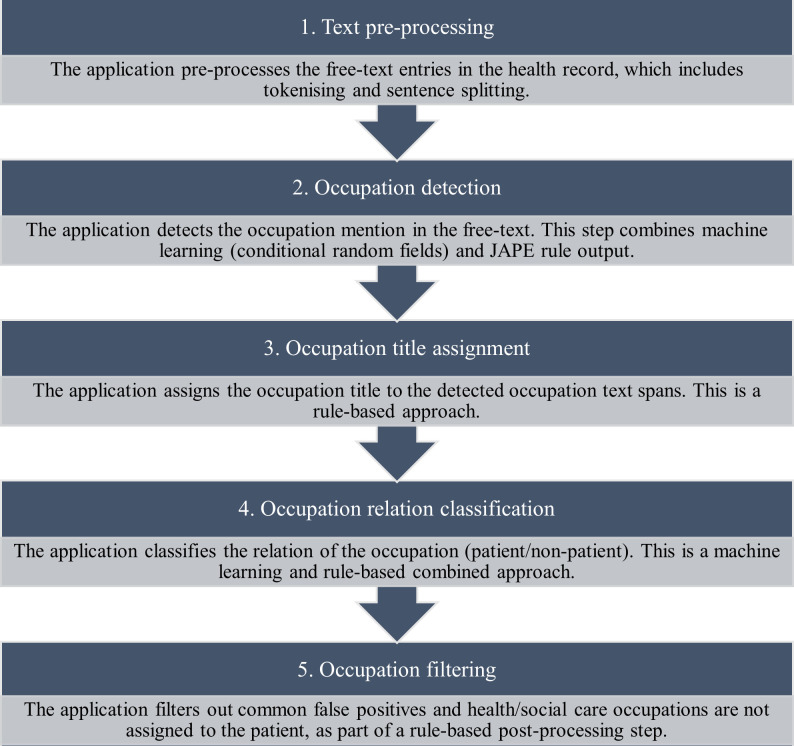
Development and validation of a natural language processing application using General Architecture for Text Engineering software to extract occupations from de-identified clinical records.
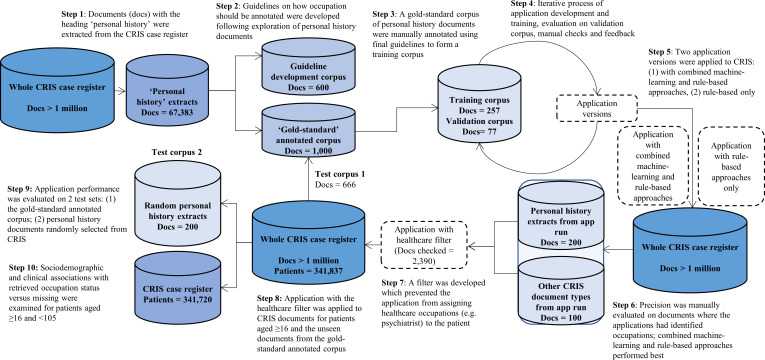
Electronic health records from a large secondary mental healthcare provider in south London, accessed through the Clinical Record Interactive Search platform. The text mining application was run over the free-text fields in the electronic health records of 341 720 patients (all aged ≥16 years).
Precision and recall estimates of the application performance; occupation retrieval using the application compared with structured fields; most common patient occupations; and analysis of key sociodemographic and clinical indicators for occupation recording.
Using the structured fields alone, only 14% of patients had occupation recorded. By implementing the text mining application in addition to the structured fields, occupations were identified in 57% of patients. The application performed on gold-standard human-annotated clinical text at a precision level of 0.79 and recall level of 0.77. The most common patient occupations recorded were 'student' and 'unemployed'. Patients with more service contact were more likely to have an occupation recorded, as were patients of a male gender, older age and those living in areas of lower deprivation.
This is the first time a natural language processing application has been used to successfully derive patient-level occupations from the free-text of electronic mental health records, performing with good levels of precision and recall, and applied at scale. This may be used to inform clinical studies relating to the broader social determinants of health using electronic health records.
我们开发、评估并实施了一个新的应用程序,该程序使用自然语言处理技术从精神科临床记录的自由文本中挖掘职业信息。
使用 General Architecture for Text Engineering 软件开发和验证自然语言处理应用程序,以从去识别的临床记录中提取职业信息。
来自伦敦南部一家大型二级精神保健服务提供商的电子健康记录,通过 Clinical Record Interactive Search 平台访问。该文本挖掘应用程序在 341720 名患者(年龄均≥16 岁)的电子健康记录的自由文本字段上运行。
应用程序性能的精度和召回率估计;应用程序与结构化字段相比的职业检索;最常见的患者职业;以及职业记录的关键社会人口学和临床指标的分析。
仅使用结构化字段,只有 14%的患者有职业记录。通过在结构化字段之外实施文本挖掘应用程序,57%的患者的职业信息得到了识别。该应用程序在经过人工注释的临床文本的黄金标准上的精度为 0.79,召回率为 0.77。记录的最常见的患者职业是“学生”和“失业”。与服务接触更多的患者更有可能有职业记录,男性患者、年龄较大的患者和生活在贫困程度较低地区的患者也是如此。
这是第一次使用自然语言处理应用程序从电子心理健康记录的自由文本中成功提取患者级别的职业信息,该应用程序具有良好的精度和召回率,并在大规模应用。这可以用于使用电子健康记录来告知与健康的更广泛社会决定因素相关的临床研究。