Higher Technical School of Engineering, University of Huelva, Huelva, Spain.
Juan Ramón Jiménez University Hospital, Huelva, Spain.
J Med Internet Res. 2021 Apr 14;23(4):e26211. doi: 10.2196/26211.
The COVID-19 pandemic is probably the greatest health catastrophe of the modern era. Spain's health care system has been exposed to uncontrollable numbers of patients over a short period, causing the system to collapse. Given that diagnosis is not immediate, and there is no effective treatment for COVID-19, other tools have had to be developed to identify patients at the risk of severe disease complications and thus optimize material and human resources in health care. There are no tools to identify patients who have a worse prognosis than others.
This study aimed to process a sample of electronic health records of patients with COVID-19 in order to develop a machine learning model to predict the severity of infection and mortality from among clinical laboratory parameters. Early patient classification can help optimize material and human resources, and analysis of the most important features of the model could provide more detailed insights into the disease.
After an initial performance evaluation based on a comparison with several other well-known methods, the extreme gradient boosting algorithm was selected as the predictive method for this study. In addition, Shapley Additive Explanations was used to analyze the importance of the features of the resulting model.
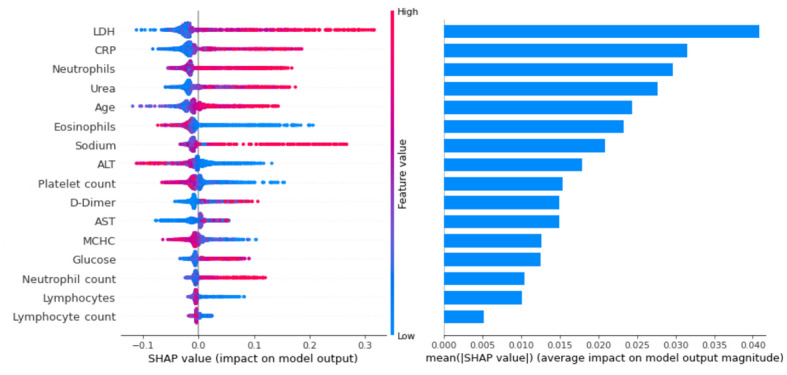
After data preprocessing, 1823 confirmed patients with COVID-19 and 32 predictor features were selected. On bootstrap validation, the extreme gradient boosting classifier yielded a value of 0.97 (95% CI 0.96-0.98) for the area under the receiver operator characteristic curve, 0.86 (95% CI 0.80-0.91) for the area under the precision-recall curve, 0.94 (95% CI 0.92-0.95) for accuracy, 0.77 (95% CI 0.72-0.83) for the F-score, 0.93 (95% CI 0.89-0.98) for sensitivity, and 0.91 (95% CI 0.86-0.96) for specificity. The 4 most relevant features for model prediction were lactate dehydrogenase activity, C-reactive protein levels, neutrophil counts, and urea levels.
Our predictive model yielded excellent results in the differentiating among patients who died of COVID-19, primarily from among laboratory parameter values. Analysis of the resulting model identified a set of features with the most significant impact on the prediction, thus relating them to a higher risk of mortality.
COVID-19 大流行可能是现代史上最大的健康灾难。西班牙的医疗保健系统在短时间内面临着无法控制的大量患者,导致系统崩溃。鉴于诊断并非即时,且 COVID-19 目前尚无有效治疗方法,因此必须开发其他工具来识别有发生严重疾病并发症风险的患者,从而优化医疗保健的物资和人力资源。目前还没有工具可以识别预后比其他患者更差的患者。
本研究旨在处理一组 COVID-19 患者的电子健康记录,以开发一种机器学习模型来预测感染严重程度和死亡率,预测依据是临床实验室参数。早期对患者进行分类有助于优化物资和人力资源,对模型最重要特征的分析可以提供更详细的疾病见解。
在基于与其他几种知名方法的比较进行初步性能评估后,选择极端梯度提升算法作为本研究的预测方法。此外,使用 Shapley 加法解释来分析所得模型的特征重要性。
在数据预处理后,选择了 1823 名确诊 COVID-19 患者和 32 个预测特征。在引导验证中,极端梯度提升分类器在接收者操作特征曲线下的面积为 0.97(95%置信区间 0.96-0.98),在精度-召回曲线下的面积为 0.86(95%置信区间 0.80-0.91),准确度为 0.94(95%置信区间 0.92-0.95),F 分数为 0.77(95%置信区间 0.72-0.83),灵敏度为 0.93(95%置信区间 0.89-0.98),特异性为 0.91(95%置信区间 0.86-0.96)。对模型预测最重要的 4 个特征是乳酸脱氢酶活性、C 反应蛋白水平、中性粒细胞计数和尿素水平。
我们的预测模型在区分 COVID-19 死亡患者方面取得了优异的结果,主要依据是实验室参数值。对所得模型的分析确定了一组对预测影响最大的特征,从而与更高的死亡率相关。