Bhandari Nikita, Khare Satyajeet, Walambe Rahee, Kotecha Ketan
Computer Science, Symbiosis Institute of Technology, Symbiosis International (Deemed University), Pune, MH, India.
Symbiosis School of Biological Sciences, Symbiosis International (Deemed University), Pune, MH, India.
PeerJ Comput Sci. 2021 Feb 9;7:e365. doi: 10.7717/peerj-cs.365. eCollection 2021.
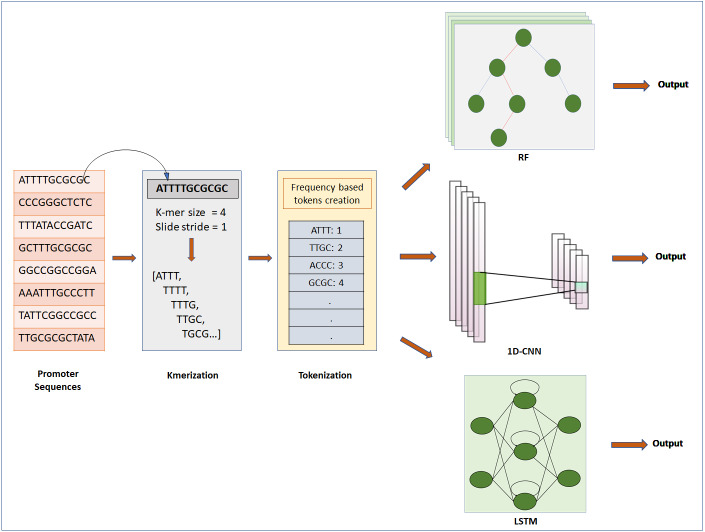
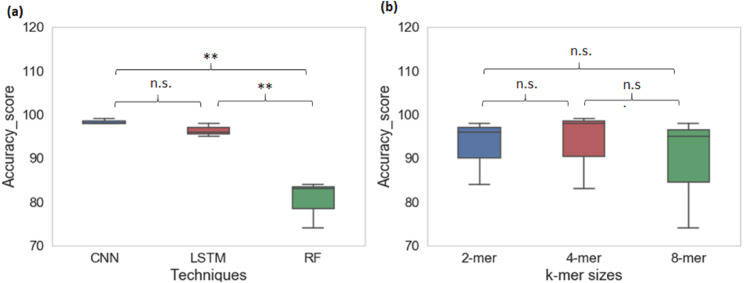
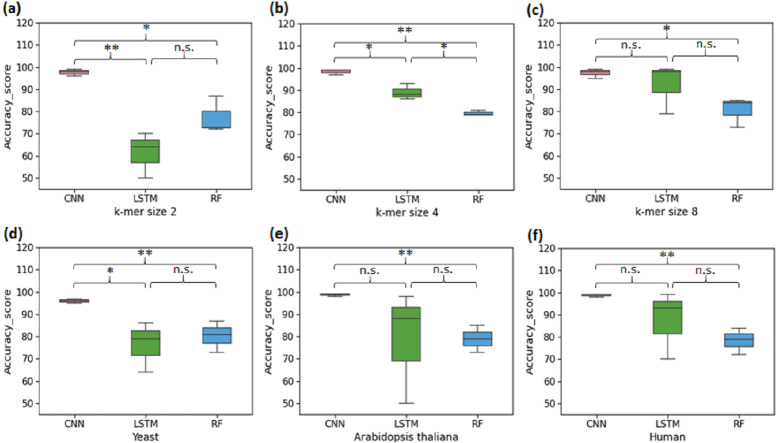
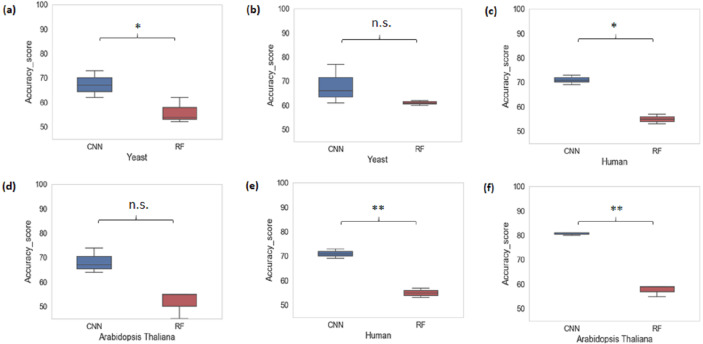
Gene promoters are the key DNA regulatory elements positioned around the transcription start sites and are responsible for regulating gene transcription process. Various alignment-based, signal-based and content-based approaches are reported for the prediction of promoters. However, since all promoter sequences do not show explicit features, the prediction performance of these techniques is poor. Therefore, many machine learning and deep learning models have been proposed for promoter prediction. In this work, we studied methods for vector encoding and promoter classification using genome sequences of three distinct higher eukaryotes viz. yeast (Saccharomyces cerevisiae), (plant) and human (Homo ). We compared one-hot vector encoding method with frequency-based tokenization (FBT) for data pre-processing on 1-D Convolutional Neural Network (CNN) model. We found that FBT gives a shorter input dimension reducing the training time without affecting the sensitivity and specificity of classification. We employed the deep learning techniques, mainly CNN and recurrent neural network with Long Short Term Memory (LSTM) and random forest (RF) classifier for promoter classification at k-mer sizes of 2, 4 and 8. We found CNN to be superior in classification of promoters from non-promoter sequences (binary classification) as well as species-specific classification of promoter sequences (multiclass classification). In summary, the contribution of this work lies in the use of synthetic shuffled negative dataset and frequency-based tokenization for pre-processing. This study provides a comprehensive and generic framework for classification tasks in genomic applications and can be extended to various classification problems.
基因启动子是位于转录起始位点周围的关键DNA调控元件,负责调控基因转录过程。已有多种基于比对、基于信号和基于内容的方法用于启动子预测。然而,由于并非所有启动子序列都具有明显特征,这些技术的预测性能较差。因此,人们提出了许多机器学习和深度学习模型用于启动子预测。在这项工作中,我们研究了使用三种不同高等真核生物(即酵母(酿酒酵母)、植物和人类)的基因组序列进行向量编码和启动子分类的方法。我们在一维卷积神经网络(CNN)模型上比较了独热向量编码方法和基于频率的词元化(FBT)用于数据预处理的效果。我们发现FBT能提供更短的输入维度,在不影响分类灵敏度和特异性的情况下减少训练时间。我们采用深度学习技术,主要是CNN以及带有长短期记忆(LSTM)的循环神经网络和随机森林(RF)分类器,对k-mer大小为2、4和8的启动子进行分类。我们发现CNN在从非启动子序列中分类启动子(二元分类)以及启动子序列的物种特异性分类(多类分类)方面表现更优。总之,这项工作的贡献在于使用合成洗牌负数据集和基于频率的词元化进行预处理。本研究为基因组应用中的分类任务提供了一个全面且通用的框架,并且可以扩展到各种分类问题。