Department of Medicine, Division of Medical Genetics, University of California San Diego, La Jolla, CA 92093, USA.
Bioinformatics and Systems Biology Program, University of California San Diego, La Jolla, CA 92093, USA.
Database (Oxford). 2021 Apr 29;2021. doi: 10.1093/database/baab021.
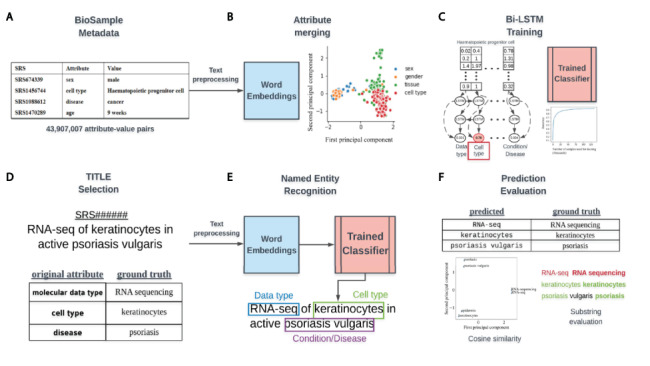
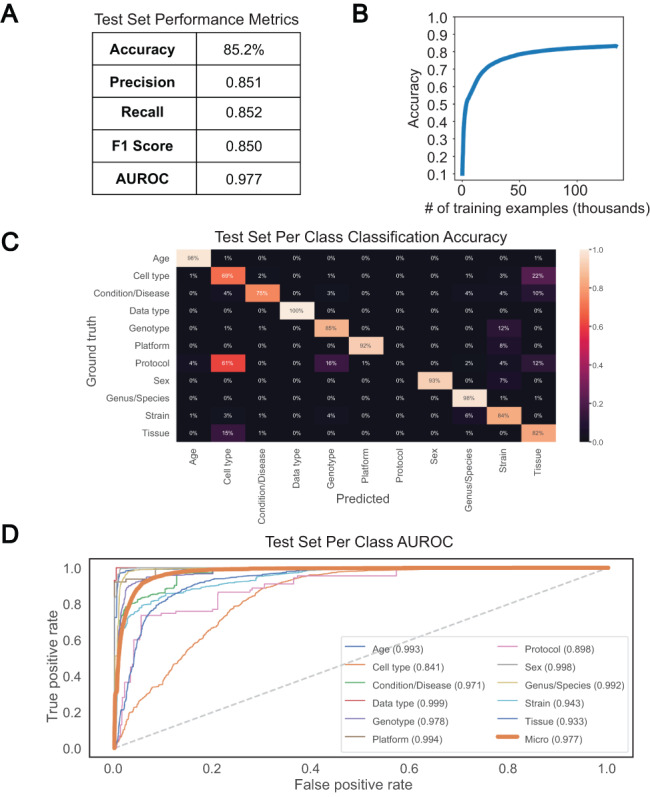
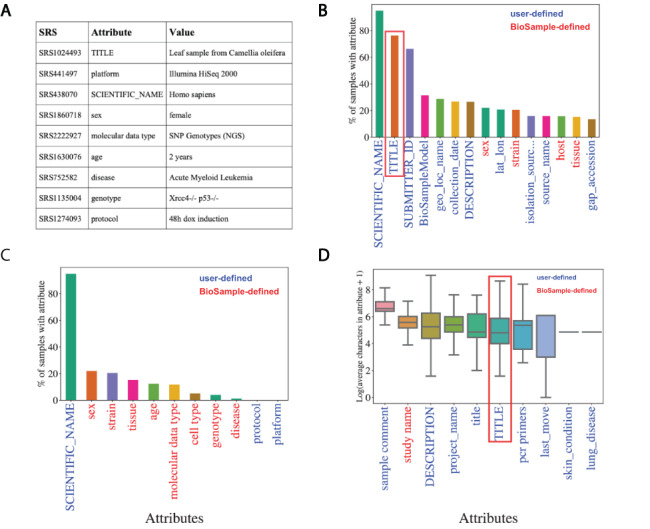
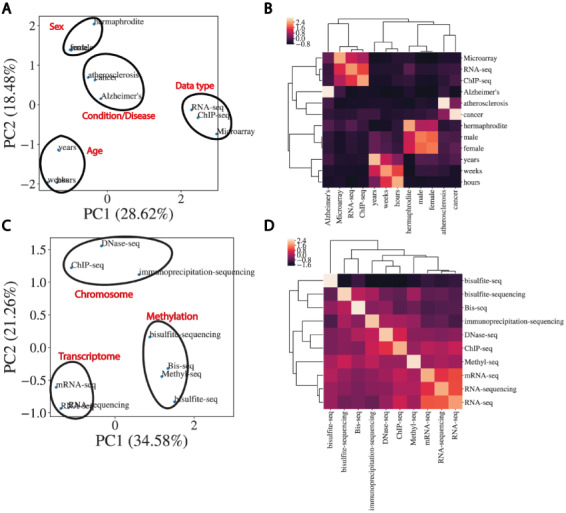
High-quality metadata annotations for data hosted in large public repositories are essential for research reproducibility and for conducting fast, powerful and scalable meta-analyses. Currently, a majority of sequencing samples in the National Center for Biotechnology Information's Sequence Read Archive (SRA) are missing metadata across several categories. In an effort to improve the metadata coverage of these samples, we leveraged almost 44 million attribute-value pairs from SRA BioSample to train a scalable, recurrent neural network that predicts missing metadata via named entity recognition (NER). The network was first trained to classify short text phrases according to 11 metadata categories and achieved an overall accuracy and area under the receiver operating characteristic curve of 85.2% and 0.977, respectively. We then applied our classifier to predict 11 metadata categories from the longer TITLE attribute of samples, evaluating performance on a set of samples withheld from model training. Prediction accuracies were high when extracting sample Genus/Species (94.85%), Condition/Disease (95.65%) and Strain (82.03%) from TITLEs, with lower accuracies and lack of predictions for other categories highlighting multiple issues with the current metadata annotations in BioSample. These results indicate the utility of recurrent neural networks for NER-based metadata prediction and the potential for models such as the one presented here to increase metadata coverage in BioSample while minimizing the need for manual curation. Database URL: https://github.com/cartercompbio/PredictMEE.
高质量的元数据注释对于数据的可重复性研究和快速、强大和可扩展的元分析至关重要。目前,国家生物技术信息中心序列读取档案 (SRA) 中的大多数测序样本在多个类别中都缺少元数据。为了提高这些样本的元数据覆盖率,我们利用了来自 SRA BioSample 的近 4400 万属性值对来训练一个可扩展的递归神经网络,通过命名实体识别 (NER) 预测缺失的元数据。该网络首先根据 11 个元数据类别来对短文本短语进行分类,总体准确率和接收者操作特征曲线下的面积分别达到 85.2%和 0.977。然后,我们将我们的分类器应用于从样本的较长 TITLE 属性中预测 11 个元数据类别,在一组从模型训练中保留的样本上评估性能。从 TITLE 中提取样本属/种 (94.85%)、条件/疾病 (95.65%)和菌株 (82.03%)时,预测准确率很高,而其他类别的准确率较低且缺乏预测,突出了 BioSample 中当前元数据注释的多个问题。这些结果表明,递归神经网络在基于 NER 的元数据预测方面具有实用性,并且像这里提出的模型这样的模型具有增加 BioSample 中元数据覆盖率的潜力,同时最大限度地减少对人工策展的需求。数据库 URL:https://github.com/cartercompbio/PredictMEE。