Safdari Reza, Rezayi Sorayya, Saeedi Soheila, Tanhapour Mozhgan, Gholamzadeh Marsa
Department of Health Information Management, School of Allied Medical Sciences, Tehran University of Medical Sciences, Tehran, Iran.
Ph.D. Student in Medical Informatics, Health Information Management Department, School of Allied Medical Sciences, Tehran University of Medical Sciences, Tehran, Iran.
Health Technol (Berl). 2021;11(4):759-771. doi: 10.1007/s12553-021-00553-7. Epub 2021 May 7.
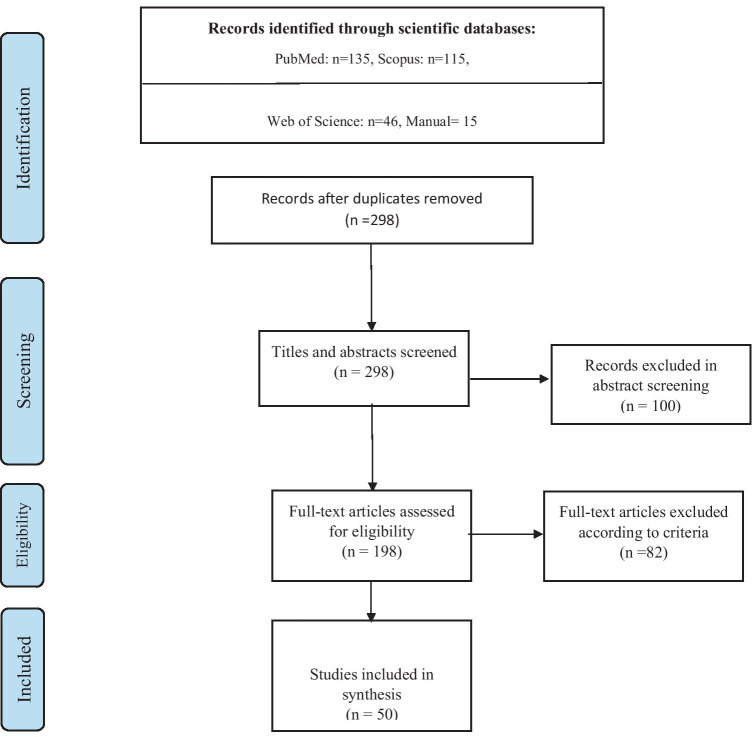
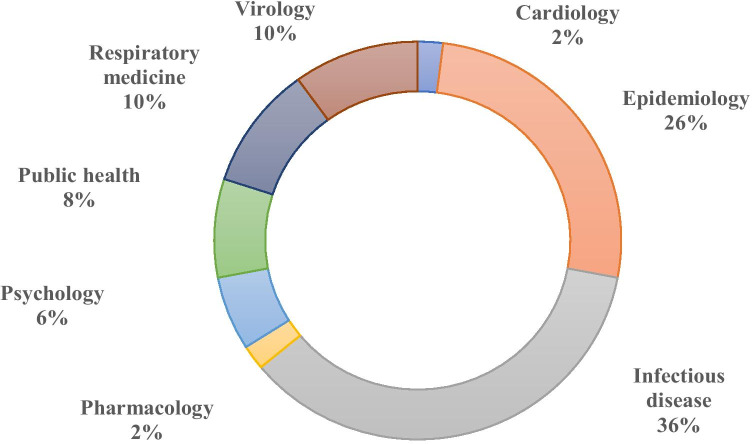
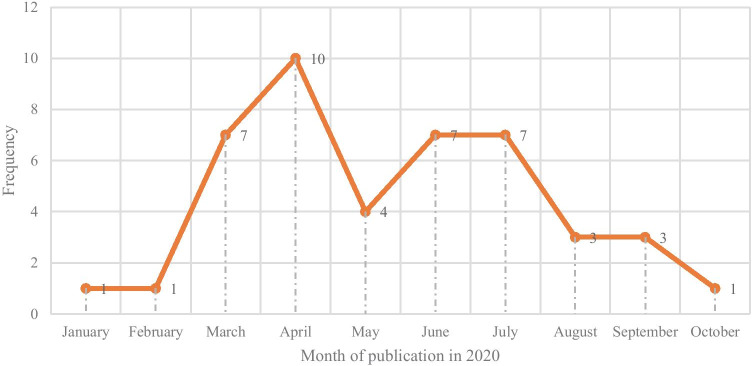
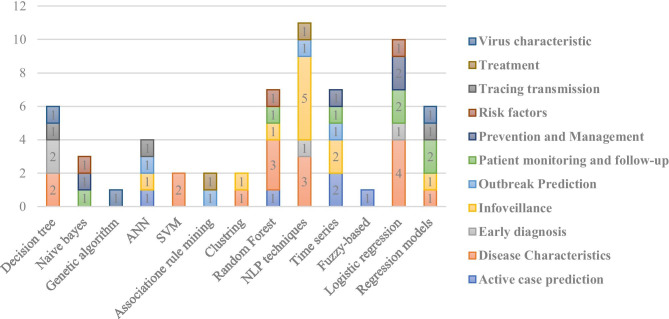
The main objective of this survey is to study the published articles to determine the most favorite data mining methods and gap of knowledge Since the threat of pandemics has raised concerns for public health, data mining techniques were applied by researchers to reveal the hidden knowledge. Web of Science, Scopus, and PubMed databases were selected for systematic searches. Then, all of the retrieved articles were screened in the stepwise process according to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses checklist to select appropriate articles. All of the results were analyzed and summarized based on some classifications. Out of 335 citations were retrieved, 50 articles were determined as eligible articles through a scoping review. The review results showed that the most favorite DM belonged to Natural language processing (22%) and the most commonly proposed approach was revealing disease characteristics (22%). Regarding diseases, the most addressed disease was COVID-19. The studies show a predominance of applying supervised learning techniques (90%). Concerning healthcare scopes, we found that infectious disease (36%) to be the most frequent, closely followed by epidemiology discipline. The most common software used in the studies was SPSS (22%) and R (20%). The results revealed that some valuable researches conducted by employing the capabilities of knowledge discovery methods to understand the unknown dimensions of diseases in pandemics. But most researches will need in terms of treatment and disease control.
本次调查的主要目的是研究已发表的文章,以确定最受欢迎的数据挖掘方法和知识差距。由于大流行的威胁引发了对公共卫生的关注,研究人员应用数据挖掘技术来揭示隐藏的知识。选择了科学网、Scopus和PubMed数据库进行系统检索。然后,根据系统评价和Meta分析的首选报告项目清单,在逐步筛选过程中对所有检索到的文章进行筛选,以选择合适的文章。所有结果都根据一些分类进行了分析和总结。在检索到的335条引用中,通过范围审查确定了50篇文章为合格文章。审查结果表明,最受欢迎的数据挖掘方法属于自然语言处理(22%),最常提出的方法是揭示疾病特征(22%)。关于疾病,提及最多的疾病是COVID-19。研究表明,应用监督学习技术的占主导地位(90%)。关于医疗保健范围,我们发现传染病(36%)是最常见的,紧随其后的是流行病学学科。研究中最常用的软件是SPSS(22%)和R(20%)。结果表明,一些有价值的研究利用知识发现方法的能力来了解大流行中疾病的未知方面。但大多数研究在治疗和疾病控制方面仍有需求。