Kuenneth Christopher, Rajan Arunkumar Chitteth, Tran Huan, Chen Lihua, Kim Chiho, Ramprasad Rampi
School of Materials Science and Engineering, Georgia Institute of Technology, Atlanta, GA 30332, USA.
Patterns (N Y). 2021 Apr 9;2(4):100238. doi: 10.1016/j.patter.2021.100238.
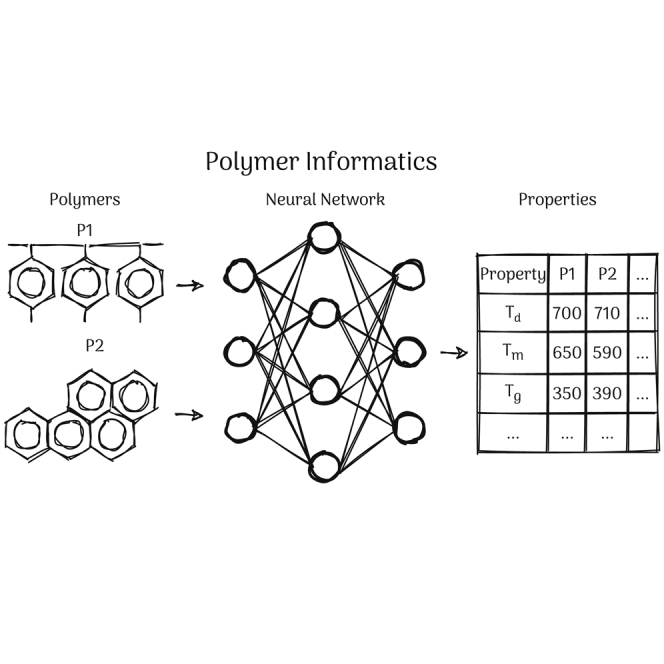
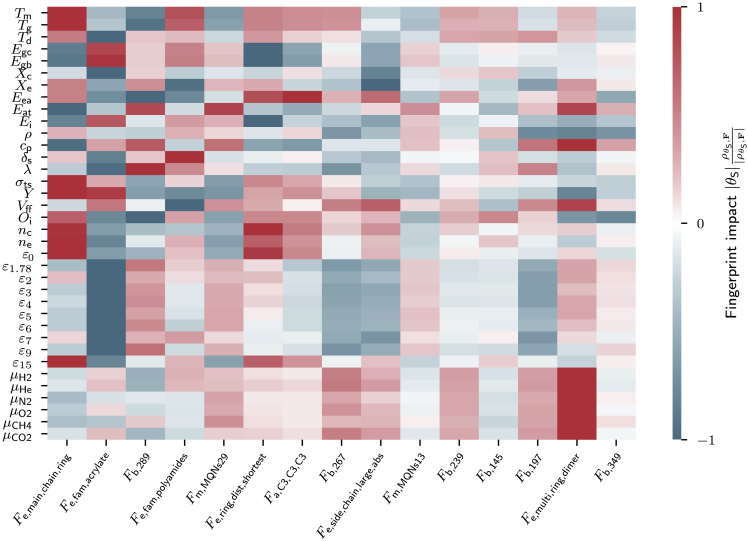
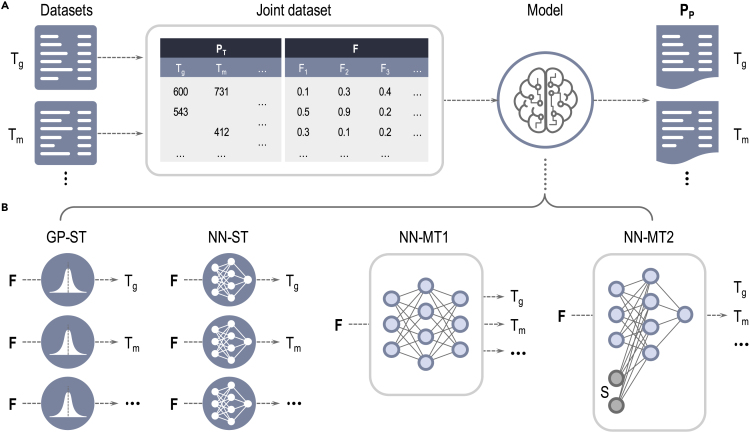
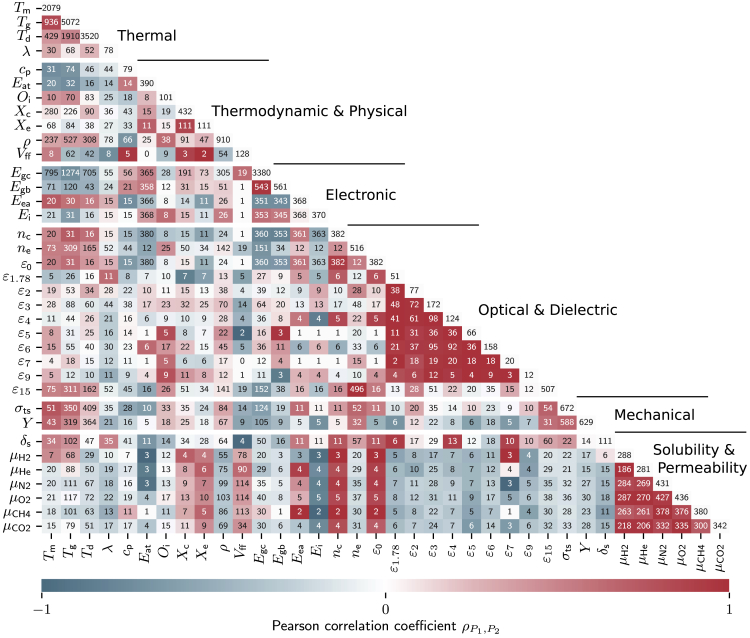
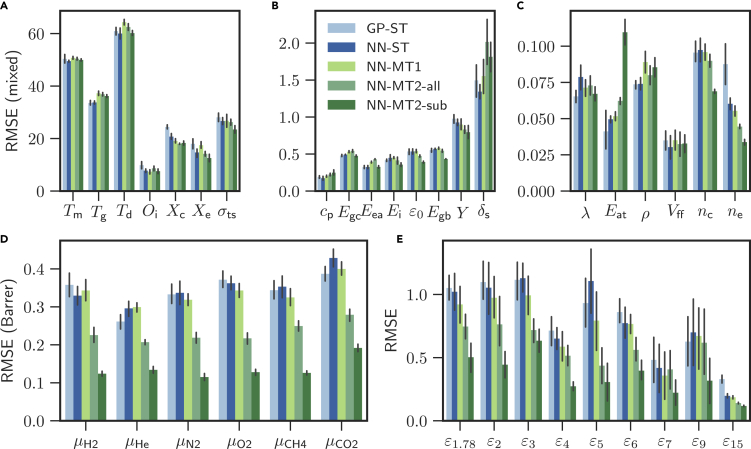
Modern data-driven tools are transforming application-specific polymer development cycles. Surrogate models that can be trained to predict properties of polymers are becoming commonplace. Nevertheless, these models do not utilize the full breadth of the knowledge available in datasets, which are oftentimes sparse; inherent correlations between different property datasets are disregarded. Here, we demonstrate the potency of multi-task learning approaches that exploit such inherent correlations effectively. Data pertaining to 36 different properties of over 13,000 polymers are supplied to deep-learning multi-task architectures. Compared to conventional single-task learning models, the multi-task approach is accurate, efficient, scalable, and amenable to transfer learning as more data on the same or different properties become available. Moreover, these models are interpretable. Chemical rules, that explain how certain features control trends in property values, emerge from the present work, paving the way for the rational design of application specific polymers meeting desired property or performance objectives.
现代数据驱动工具正在改变特定应用聚合物的开发周期。可以训练来预测聚合物性能的替代模型正变得越来越普遍。然而,这些模型并未利用数据集中可用知识的全部广度,而这些数据集往往是稀疏的;不同性能数据集之间的内在相关性被忽略了。在这里,我们展示了有效利用这种内在相关性的多任务学习方法的效力。与13000多种聚合物的36种不同性能相关的数据被提供给深度学习多任务架构。与传统的单任务学习模型相比,多任务方法准确、高效、可扩展,并且随着关于相同或不同性能的更多数据可用,适合进行迁移学习。此外,这些模型是可解释的。解释某些特征如何控制性能值趋势的化学规则从当前工作中浮现出来,为满足所需性能或性能目标的特定应用聚合物的合理设计铺平了道路。