Guo Rundi, Ellis Nick C
Language Learning Laboratory, Department of Psychology, University of Michigan, Ann Arbor, MI, United States.
Front Psychol. 2021 Apr 29;12:582259. doi: 10.3389/fpsyg.2021.582259. eCollection 2021.
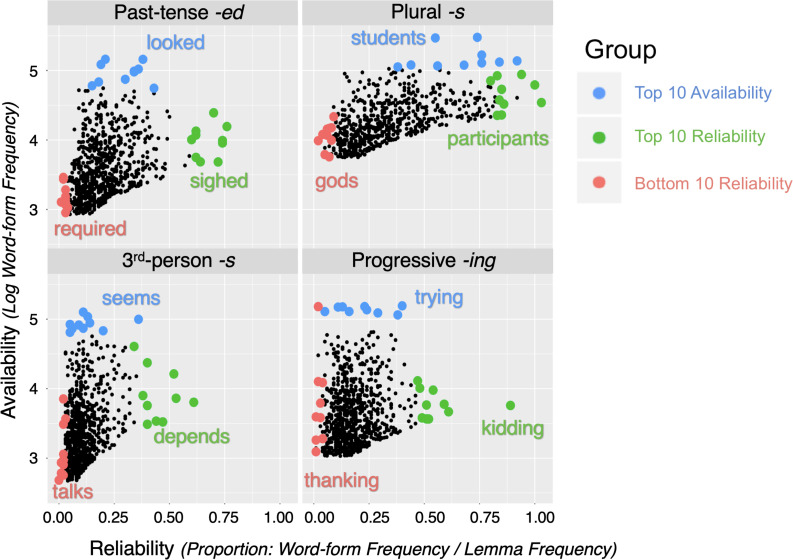
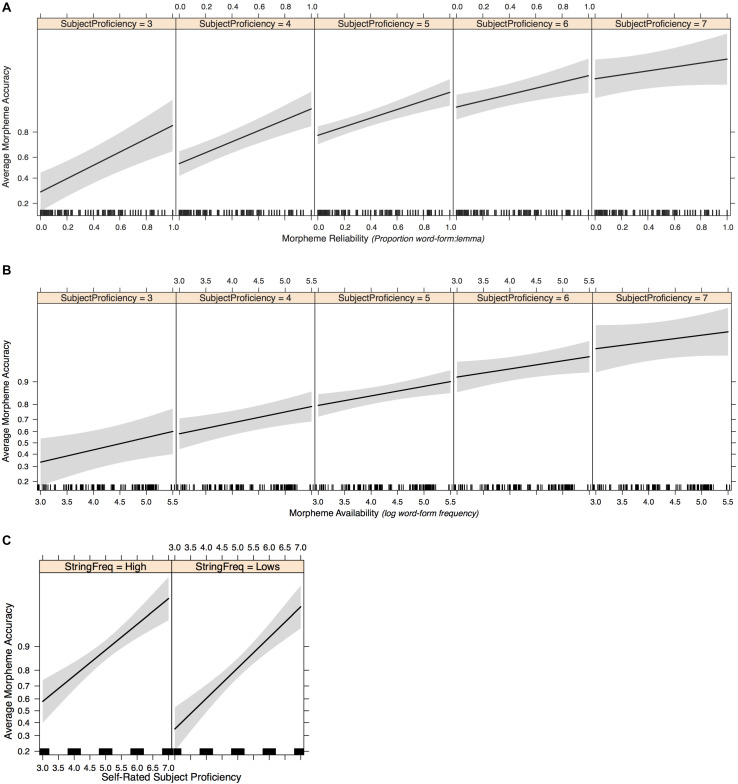
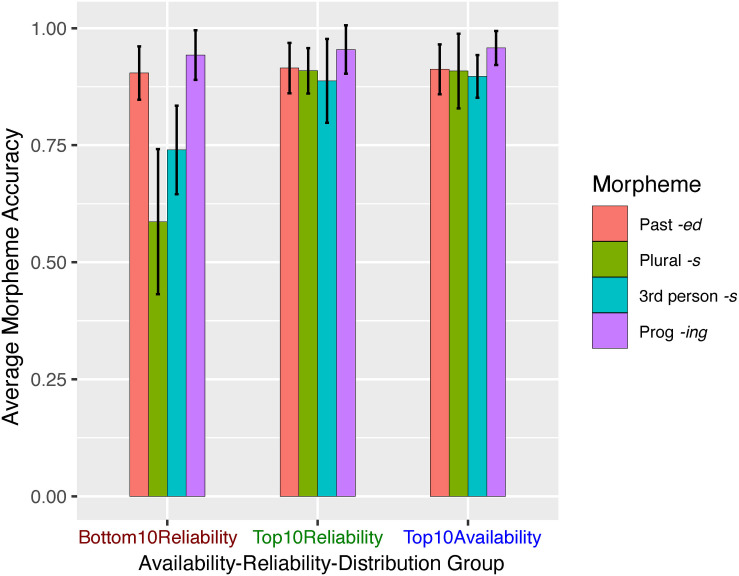
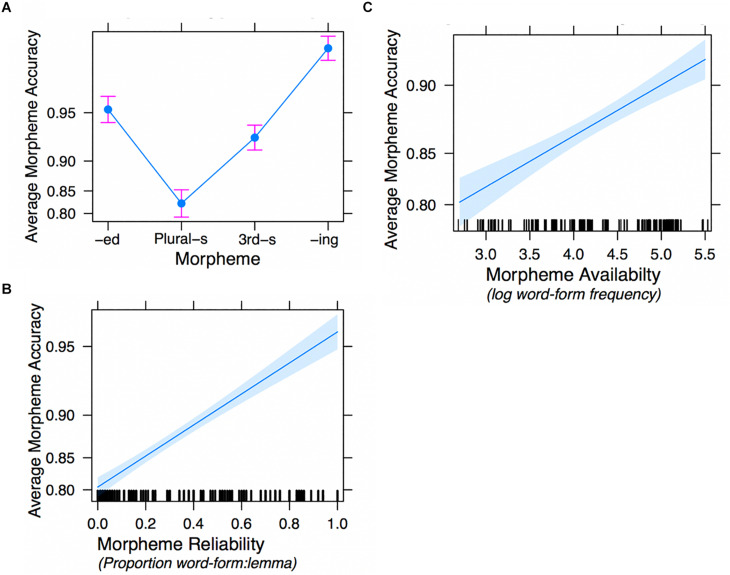
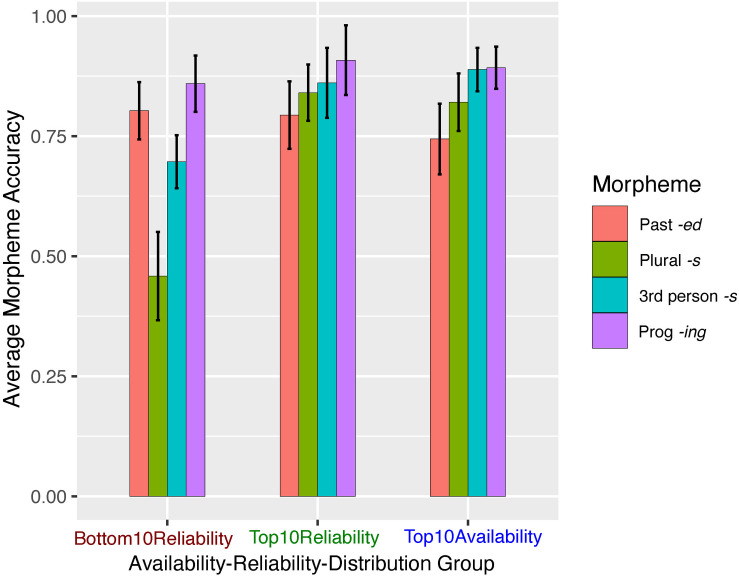
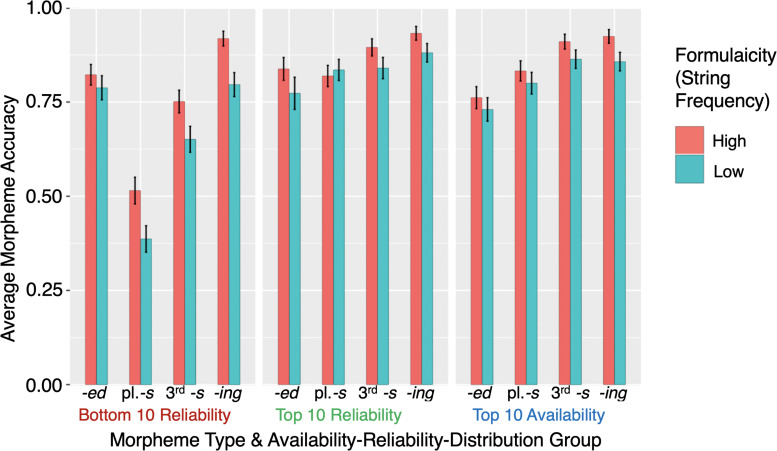
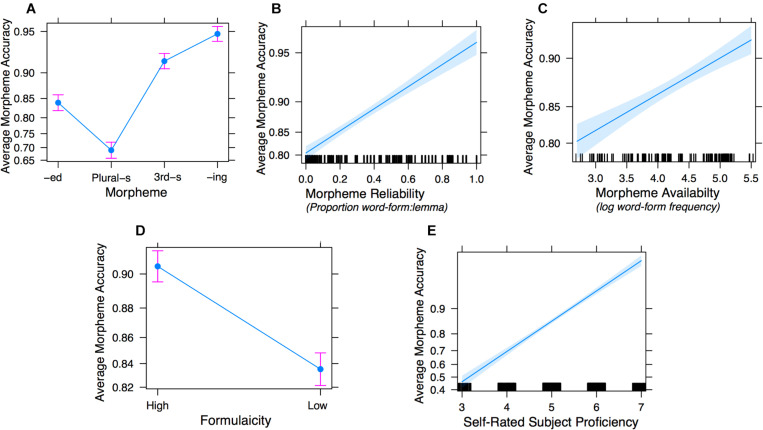
A large body of psycholinguistic research demonstrates that both language processing and language acquisition are sensitive to the distributions of linguistic constructions in usage. Here we investigate how statistical distributions at different linguistic levels - morphological and lexical (Experiments 1 and 2), and phrasal (Experiment 2) - contribute to the ease with which morphosyntax is processed and produced by second language learners. We analyze Chinese ESL learners' knowledge of four English inflectional morphemes: , , and third-person on verbs, and plural on nouns. In Elicited Imitation Tasks, participants listened to length- and difficulty-matched sentences each containing one target morpheme and typed the whole sentence as accurately as they could after a short delay. Experiment 1 investigated lexical and morphemic levels, testing the hypotheses that a morpheme is expected to be more easily processed when it is (1) highly (i.e., occurring in frequent word-forms), and (2) highly (i.e., occurring in lemma words that are consistently conjugated in the form containing this morpheme). Thirty sentences were made for each morpheme, divided into three Availability-Reliability Distribution (ARD) groups on the basis of corpus analysis in the Corpus of Contemporary American English (COCA; Davies, 2008-): 10 target words high in availability, 10 high in reliability, and 10 low in both reliability and availability. Responses were scored on whether the target morpheme was accurately reproduced given the provision of the correct lemma. A generalized linear mixed-effects logit model (GLMM) revealed fixed effects of morpheme type, availability, and reliability on the accuracy of morpheme provision. There were no effects of lemma frequency. Experiment 2 successfully replicated these results and extended the investigation to explore phrasal formulaicity by manipulating the frequency of the four-word strings in which the morpheme was embedded. GLMMs replicated the effects of word-form availability and reliability and additionally revealed independent where morphemes were better reproduced in contexts of higher string-frequency. Taken together, these findings demonstrate that morpheme acquisition reflects the distributional properties of learners' experience and the mappings therein between lexis, morphology, phraseology, and semantics. These conclusions support an emergentist view of the statistical symbolic learning of morphology where language acquisition involves the satisfaction of competing constraints across multiple grainsizes of units.
大量心理语言学研究表明,语言处理和语言习得都对语言结构在使用中的分布敏感。在此,我们研究不同语言层面——形态和词汇层面(实验1和实验2)以及短语层面(实验2)——的统计分布如何影响第二语言学习者处理和生成形态句法的难易程度。我们分析了中国英语学习者对四个英语屈折语素的掌握情况:动词上的第三人称单数 -s、-es、-ies,以及名词上的复数 -s。在诱发模仿任务中,参与者听长度和难度匹配的句子,每个句子包含一个目标语素,短暂延迟后尽可能准确地打出整个句子。实验1研究了词汇和语素层面,检验了以下假设:当一个语素(1)具有高可用性(即出现在高频词形中),以及(2)具有高可靠性(即出现在始终以包含该语素的形式进行词形变化的词元词中)时,它会更容易被处理。针对每个语素制作了30个句子,根据当代美国英语语料库(COCA;戴维斯,2008年至今)中的语料分析,将其分为三个可用性 - 可靠性分布(ARD)组:10个目标词具有高可用性,10个具有高可靠性,10个在可靠性和可用性方面都较低。根据是否在提供正确词元的情况下准确再现目标语素对回答进行评分。一个广义线性混合效应逻辑模型(GLMM)揭示了语素类型、可用性和可靠性对语素提供准确性的固定效应。词元频率没有影响。实验2成功复制了这些结果,并通过操纵嵌入语素的四字字符串的频率,将研究扩展到探索短语公式化。GLMM复制了词形可用性和可靠性的影响,此外还揭示了独立效应,即在更高字符串频率的语境中语素被更好地再现。综合来看,这些发现表明语素习得反映了学习者经验的分布特性以及其中词汇、形态、短语和语义之间的映射。这些结论支持了形态学统计符号学习的涌现主义观点,即语言习得涉及满足跨多个粒度单位的相互竞争的限制。