Janssen R&D, LLC, Raritan, NJ, USA.
Johnson & Johnson, New Brunswick, NJ, USA.
BMC Med Res Methodol. 2021 May 24;21(1):109. doi: 10.1186/s12874-021-01282-1.
Cardinality matching (CM), a novel matching technique, finds the largest matched sample meeting prespecified balance criteria thereby overcoming limitations of propensity score matching (PSM) associated with limited covariate overlap, which are especially pronounced in studies with small sample sizes. The current study proposes a framework for large-scale CM (LS-CM); and compares large-scale PSM (LS-PSM) and LS-CM in terms of post-match sample size, covariate balance and residual confounding at progressively smaller sample sizes.
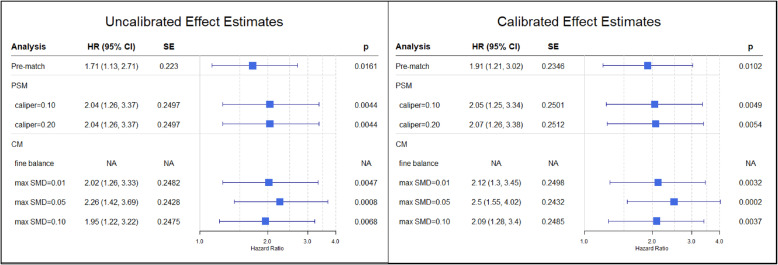
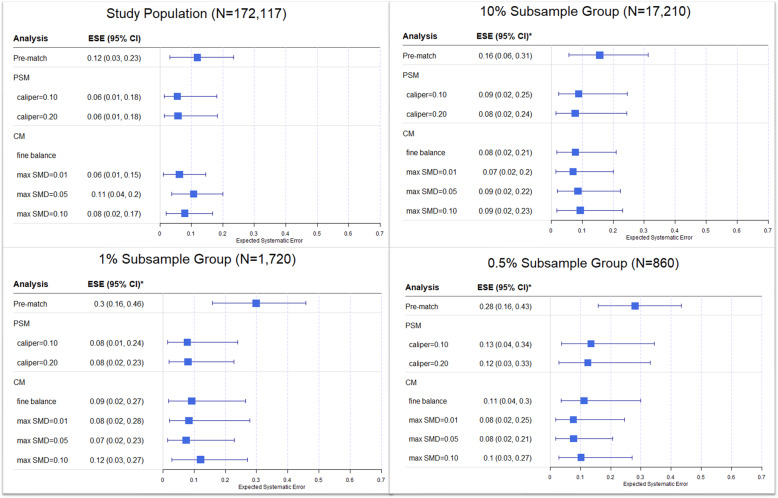
Evaluation of LS-PSM and LS-CM within a comparative cohort study of new users of angiotensin-converting enzyme inhibitor (ACEI) and thiazide or thiazide-like diuretic monotherapy identified from a U.S. insurance claims database. Candidate covariates included patient demographics, and all observed prior conditions, drug exposures and procedures. Propensity scores were calculated using LASSO regression, and candidate covariates with non-zero beta coefficients in the propensity model were defined as matching covariates for use in LS-CM. One-to-one matching was performed using progressively tighter parameter settings. Covariate balance was assessed using standardized mean differences. Hazard ratios for negative control outcomes perceived as unassociated with treatment (i.e., true hazard ratio of 1) were estimated using unconditional Cox models. Residual confounding was assessed using the expected systematic error of the empirical null distribution of negative control effect estimates compared to the ground truth. To simulate diverse research conditions, analyses were repeated within 10 %, 1 and 0.5 % subsample groups with increasingly limited covariate overlap.
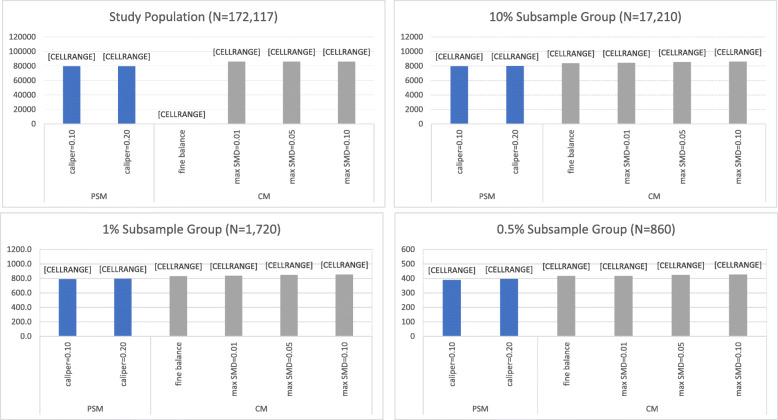
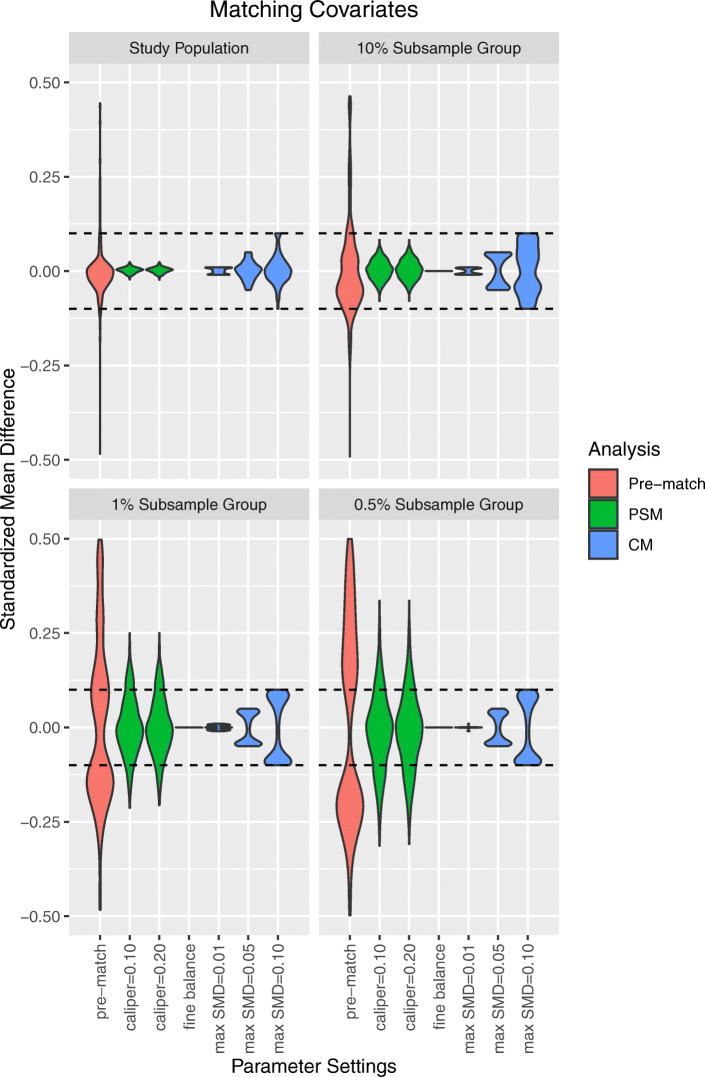
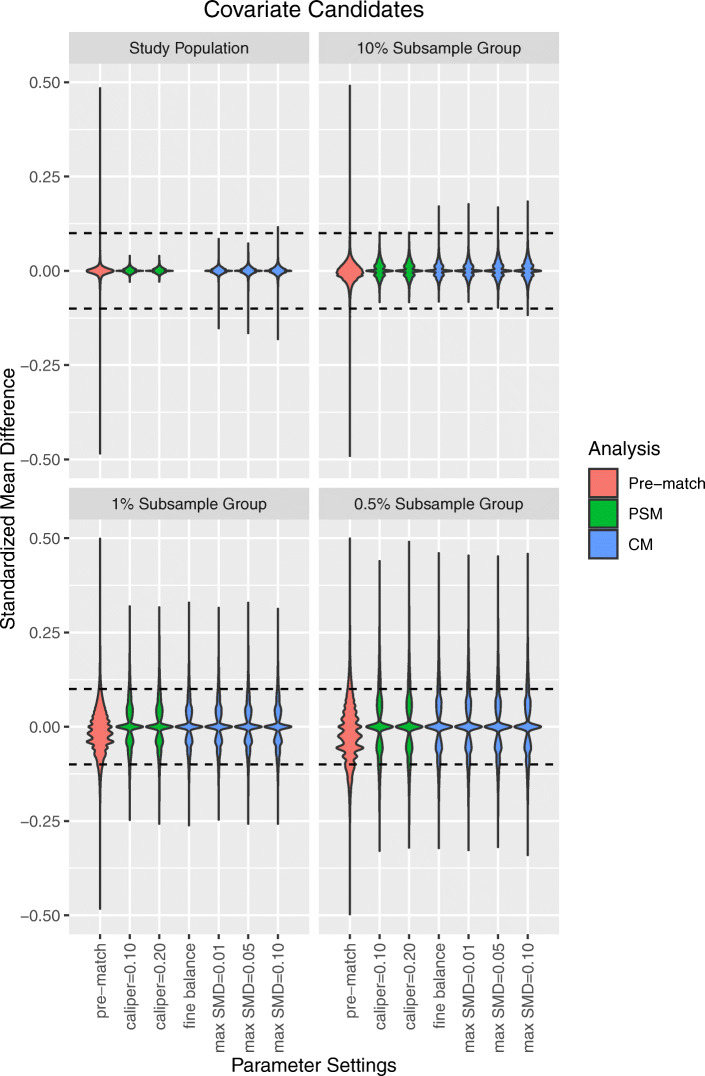
A total of 172,117 patients (ACEI: 129,078; thiazide: 43,039) met the study criteria. As compared to LS-PSM, LS-CM was associated with increased sample retention. Although LS-PSM achieved balance across all matching covariates within the full study population, substantial matching covariate imbalance was observed within the 1 and 0.5 % subsample groups. Meanwhile, LS-CM achieved matching covariate balance across all analyses. LS-PSM was associated with better candidate covariate balance within the full study population. Otherwise, both matching techniques achieved comparable candidate covariate balance and expected systematic error.
LS-CM found the largest matched sample meeting prespecified balance criteria while achieving comparable candidate covariate balance and residual confounding. We recommend LS-CM as an alternative to LS-PSM in studies with small sample sizes or limited covariate overlap.
基数匹配(CM)是一种新颖的匹配技术,它找到满足预定平衡标准的最大匹配样本,从而克服了倾向评分匹配(PSM)的局限性,后者与有限的协变量重叠有关,在样本量较小的研究中尤为明显。本研究提出了一种大规模基数匹配(LS-CM)框架;并在一项来自美国保险索赔数据库的新型血管紧张素转换酶抑制剂(ACEI)和噻嗪或噻嗪类利尿剂单药治疗新使用者的比较队列研究中,比较了 LS-PSM 和 LS-CM 在匹配后样本量、协变量平衡和残差混杂方面的差异,样本量逐渐减小。
使用 LASSO 回归计算倾向得分,并将倾向模型中具有非零β系数的候选协变量定义为用于 LS-CM 的匹配协变量。使用逐渐严格的参数设置进行一对一匹配。使用标准化均数差评估协变量平衡。使用无条件 Cox 模型估计被认为与治疗无关的负对照结果(即真实危险比为 1)的危险比。使用负对照效果估计值的经验零分布与实际值的预期系统误差评估残余混杂。为了模拟不同的研究条件,在 10%、1%和 0.5%的子样本组内重复进行分析,其中协变量重叠越来越有限。
共有 172117 名患者(ACEI:129078;噻嗪:43039)符合研究标准。与 LS-PSM 相比,LS-CM 与样本保留增加有关。虽然 LS-PSM 在整个研究人群中实现了所有匹配协变量的平衡,但在 1%和 0.5%子样本组中观察到了大量的匹配协变量不平衡。同时,LS-CM 实现了所有分析的匹配协变量平衡。LS-PSM 在整个研究人群中与更好的候选协变量平衡相关。否则,两种匹配技术都实现了相当的候选协变量平衡和预期的系统误差。
LS-CM 找到了满足预定平衡标准的最大匹配样本,同时实现了相当的候选协变量平衡和残余混杂。我们建议在样本量较小或协变量重叠有限的研究中,LS-CM 作为 LS-PSM 的替代方法。