Krishnamurthy Surya, Ks Kapeleshh, Dovgan Erik, Luštrek Mitja, Gradišek Piletič Barbara, Srinivasan Kathiravan, Li Yu-Chuan Jack, Gradišek Anton, Syed-Abdul Shabbir
School of Information Technology and Engineering, Vellore Institute of Technology (VIT), Vellore 632014, India.
Department of Biotechnology, Indian Institute of Technology Madras, Chennai 600036, India.
Healthcare (Basel). 2021 May 7;9(5):546. doi: 10.3390/healthcare9050546.
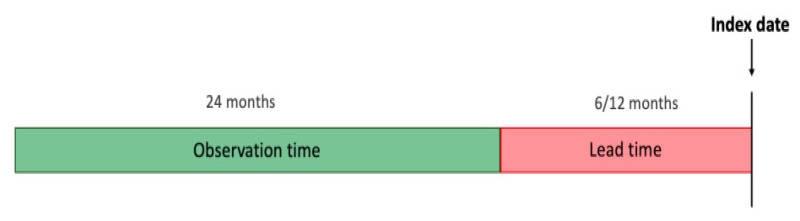
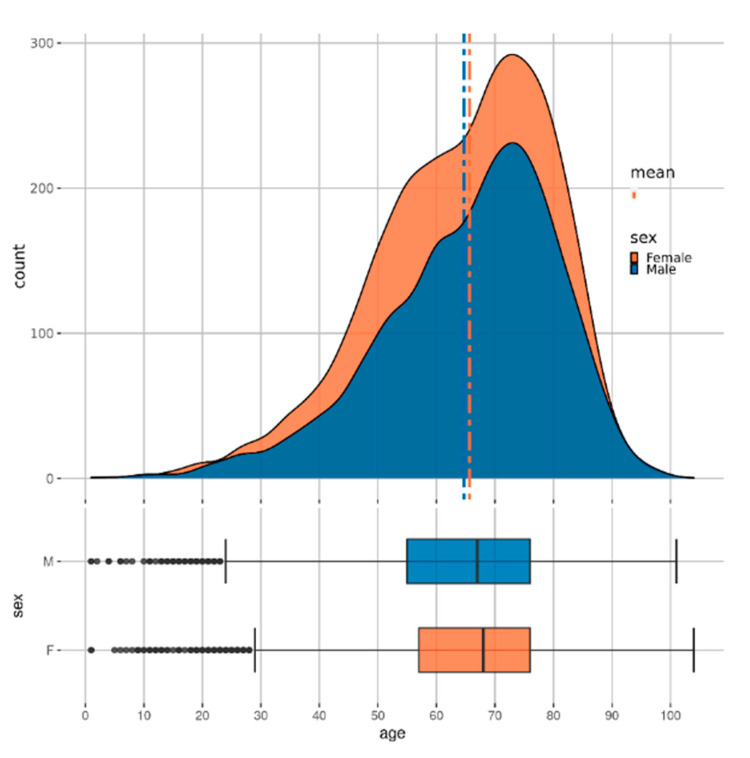
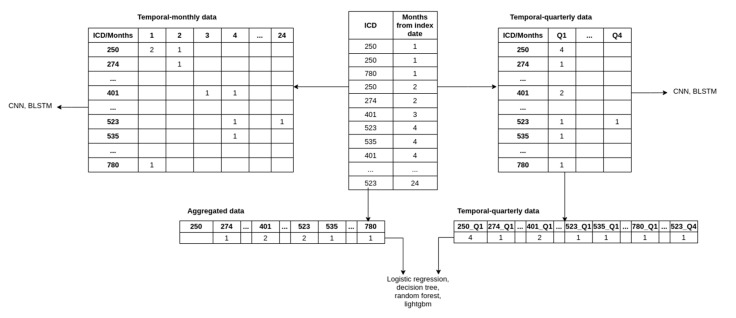
Chronic kidney disease (CKD) represents a heavy burden on the healthcare system because of the increasing number of patients, high risk of progression to end-stage renal disease, and poor prognosis of morbidity and mortality. The aim of this study is to develop a machine-learning model that uses the comorbidity and medication data obtained from Taiwan's National Health Insurance Research Database to forecast the occurrence of CKD within the next 6 or 12 months before its onset, and hence its prevalence in the population. A total of 18,000 people with CKD and 72,000 people without CKD diagnosis were selected using propensity score matching. Their demographic, medication and comorbidity data from their respective two-year observation period were used to build a predictive model. Among the approaches investigated, the Convolutional Neural Networks (CNN) model performed best with a test set AUROC of 0.957 and 0.954 for the 6-month and 12-month predictions, respectively. The most prominent predictors in the tree-based models were identified, including diabetes mellitus, age, gout, and medications such as sulfonamides and angiotensins. The model proposed in this study could be a useful tool for policymakers in predicting the trends of CKD in the population. The models can allow close monitoring of people at risk, early detection of CKD, better allocation of resources, and patient-centric management.
慢性肾脏病(CKD)给医疗系统带来了沉重负担,这是由于患者数量不断增加、进展为终末期肾病的风险高以及发病和死亡的预后较差。本研究的目的是开发一种机器学习模型,该模型利用从台湾国民健康保险研究数据库获得的合并症和用药数据,在CKD发病前的未来6个月或12个月内预测其发生情况,从而预测其在人群中的患病率。使用倾向得分匹配法共选取了18000名CKD患者和72000名未被诊断为CKD的人。利用他们在各自两年观察期内的人口统计学、用药和合并症数据来建立预测模型。在所研究的方法中,卷积神经网络(CNN)模型表现最佳,6个月和12个月预测的测试集受试者工作特征曲线下面积(AUROC)分别为0.957和0.954。确定了基于树的模型中最突出的预测因素,包括糖尿病、年龄、痛风以及磺胺类药物和血管紧张素等药物。本研究中提出的模型可能是政策制定者预测人群中CKD趋势的有用工具。这些模型可以对高危人群进行密切监测,早期发现CKD,更好地分配资源,并以患者为中心进行管理。