Department of Computer Engineering, Hacettepe University, Ankara 06800, Turkey.
Institute of Informatics, Hacettepe University, Ankara 06800, Turkey.
Nucleic Acids Res. 2021 Sep 20;49(16):e96. doi: 10.1093/nar/gkab543.
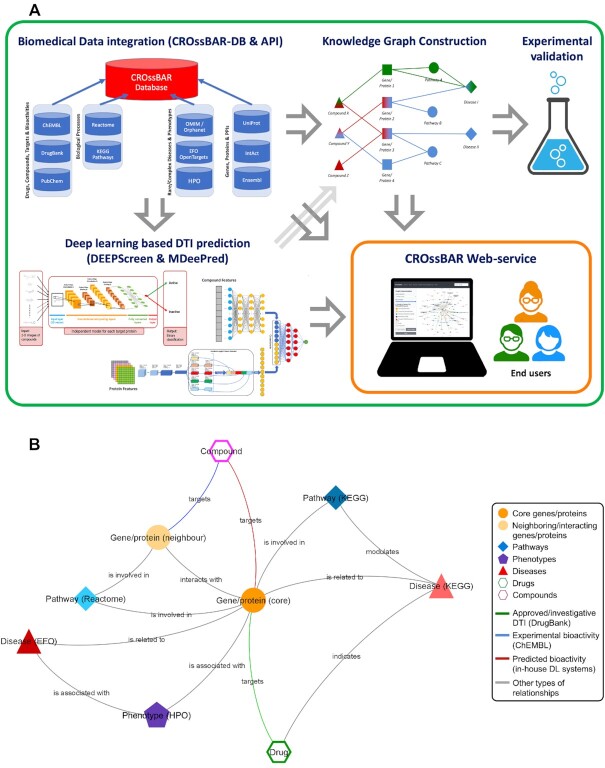
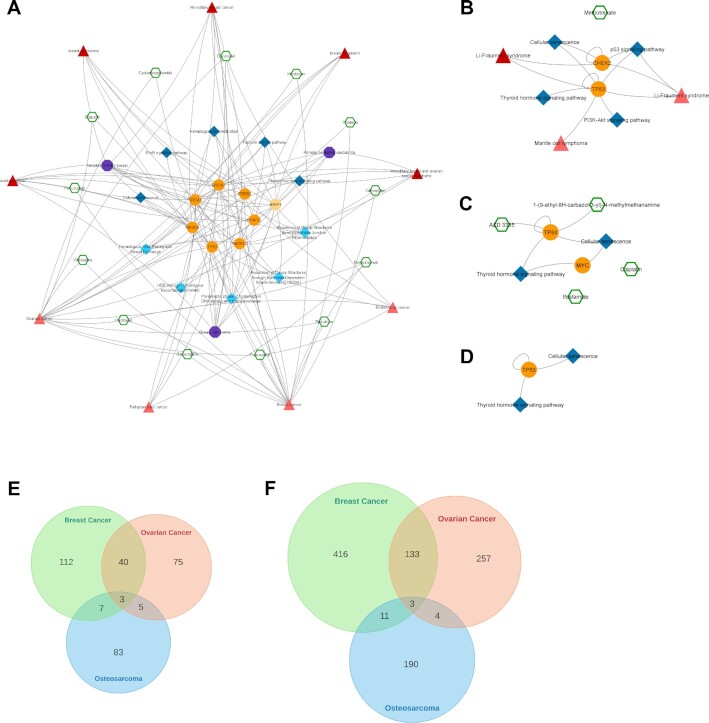
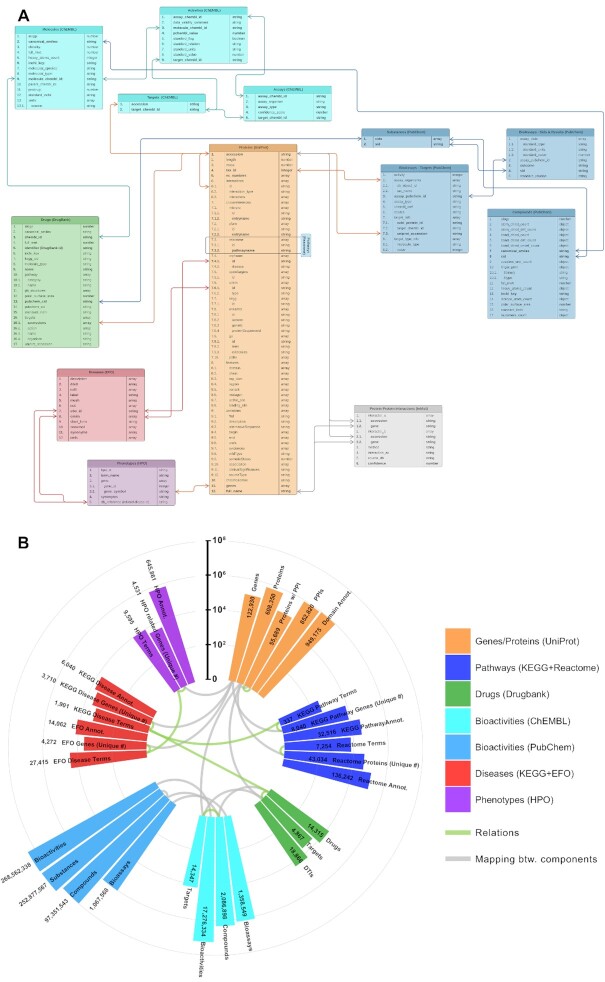
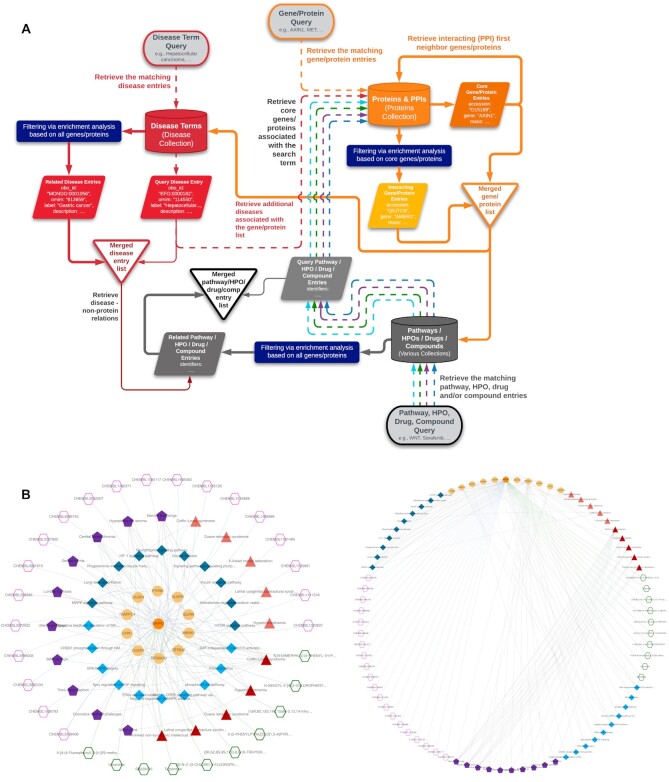
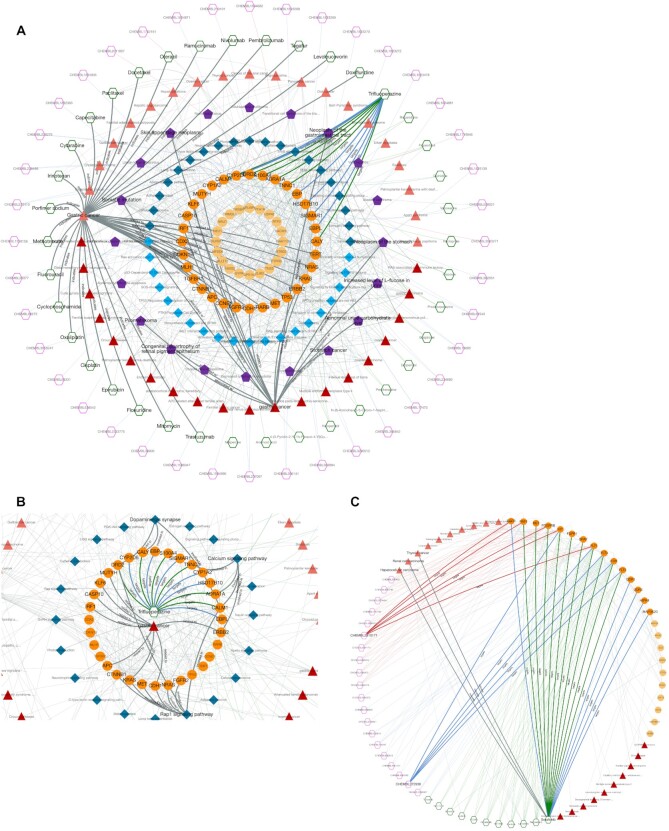
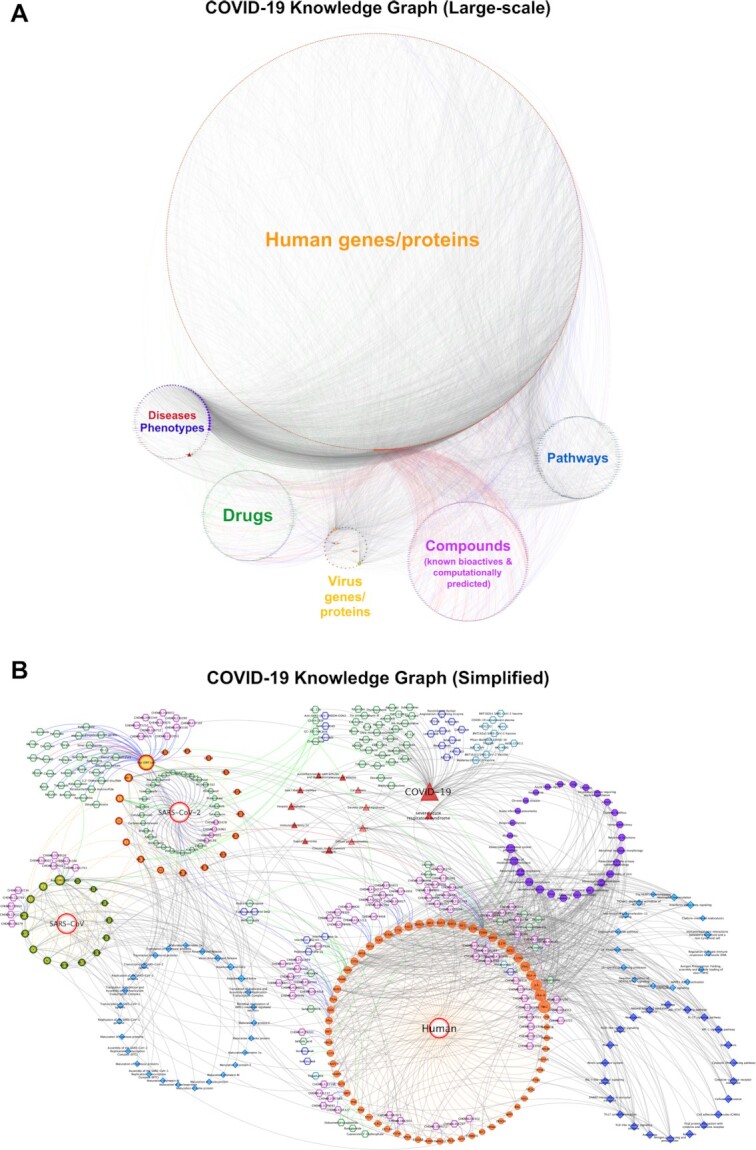
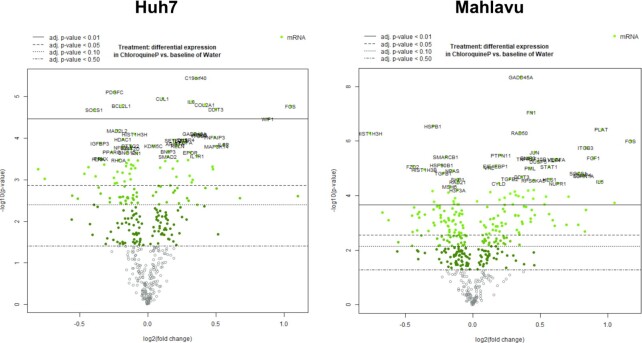
Systemic analysis of available large-scale biological/biomedical data is critical for studying biological mechanisms, and developing novel and effective treatment approaches against diseases. However, different layers of the available data are produced using different technologies and scattered across individual computational resources without any explicit connections to each other, which hinders extensive and integrative multi-omics-based analysis. We aimed to address this issue by developing a new data integration/representation methodology and its application by constructing a biological data resource. CROssBAR is a comprehensive system that integrates large-scale biological/biomedical data from various resources and stores them in a NoSQL database. CROssBAR is enriched with the deep-learning-based prediction of relationships between numerous data entries, which is followed by the rigorous analysis of the enriched data to obtain biologically meaningful modules. These complex sets of entities and relationships are displayed to users via easy-to-interpret, interactive knowledge graphs within an open-access service. CROssBAR knowledge graphs incorporate relevant genes-proteins, molecular interactions, pathways, phenotypes, diseases, as well as known/predicted drugs and bioactive compounds, and they are constructed on-the-fly based on simple non-programmatic user queries. These intensely processed heterogeneous networks are expected to aid systems-level research, especially to infer biological mechanisms in relation to genes, proteins, their ligands, and diseases.
系统地分析现有的大规模生物/生物医学数据对于研究生物机制和开发针对疾病的新型有效治疗方法至关重要。然而,可用数据的不同层次是使用不同的技术生成的,并分散在单独的计算资源中,彼此之间没有任何明确的联系,这阻碍了广泛的基于多组学的综合分析。我们旨在通过开发一种新的数据集成/表示方法及其在构建生物数据资源中的应用来解决这个问题。CROssBAR 是一个综合系统,它整合了来自各种资源的大规模生物/生物医学数据,并将其存储在一个 NoSQL 数据库中。CROssBAR 还通过基于深度学习的大量数据条目之间的关系预测进行了丰富,然后对丰富的数据进行严格分析,以获得具有生物学意义的模块。这些复杂的实体和关系集通过易于解释的交互式知识图谱呈现给用户,该服务提供开放访问。CROssBAR 知识图谱包含相关的基因-蛋白质、分子相互作用、途径、表型、疾病以及已知/预测的药物和生物活性化合物,并且它们是根据简单的非编程用户查询即时构建的。这些经过密集处理的异构网络有望帮助进行系统级研究,特别是推断与基因、蛋白质、它们的配体和疾病相关的生物学机制。