Lopes António M, Tenreiro Machado José A
INEGI, Faculty of Engineering, University of Porto, 4200-465 Porto, Portugal.
Institute of Engineering, Polytechnic of Porto, Dept. of Electrical Engineering, 4249-015 Porto, Portugal.
Entropy (Basel). 2021 Jun 23;23(7):793. doi: 10.3390/e23070793.
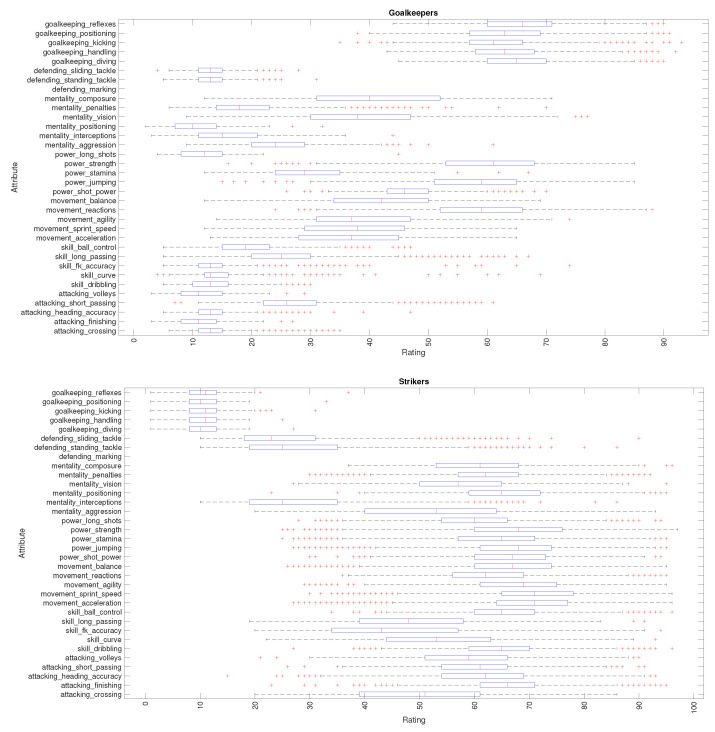
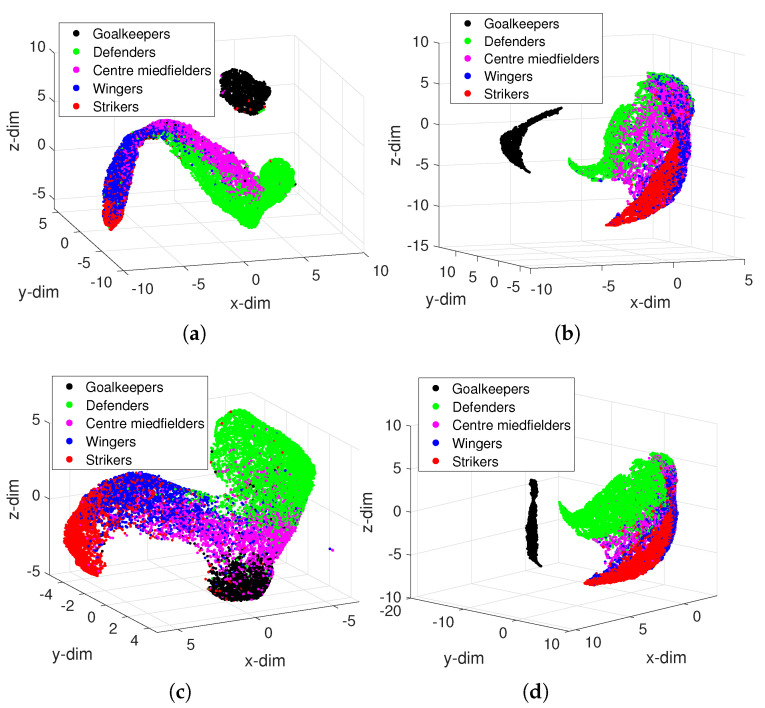
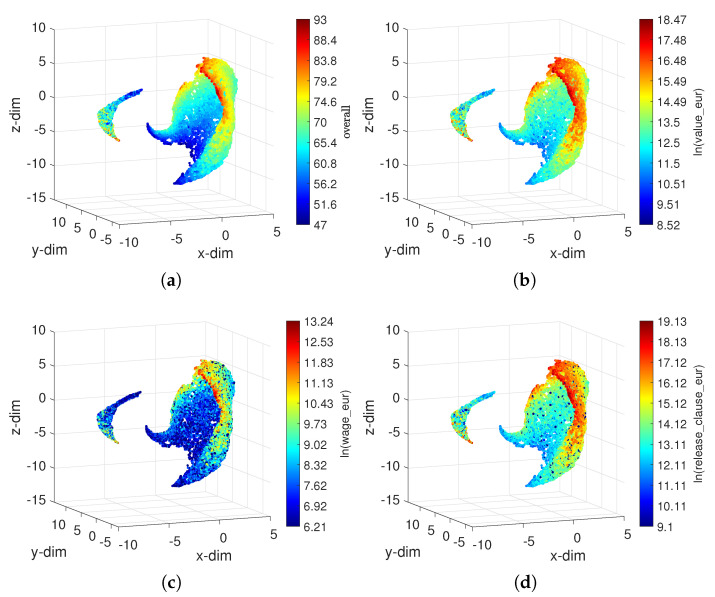
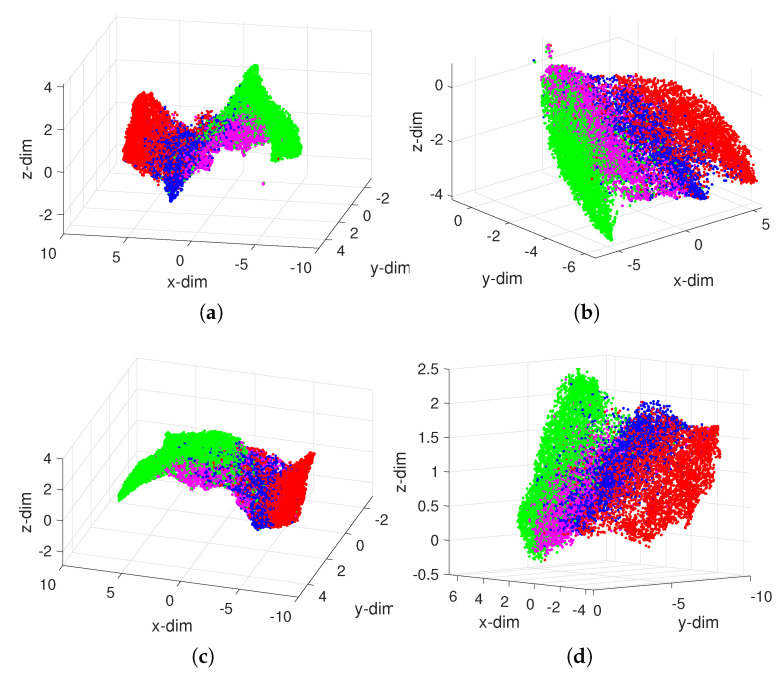
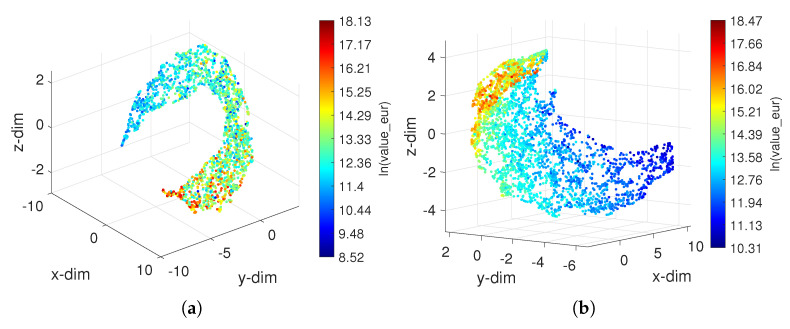
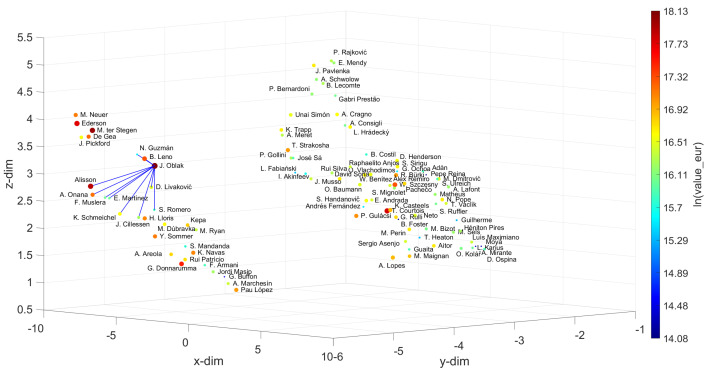
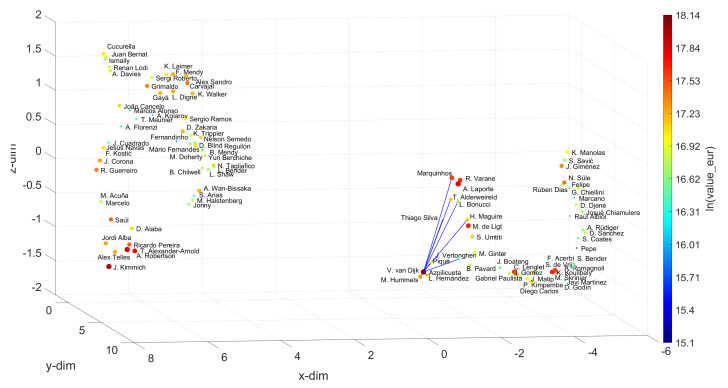
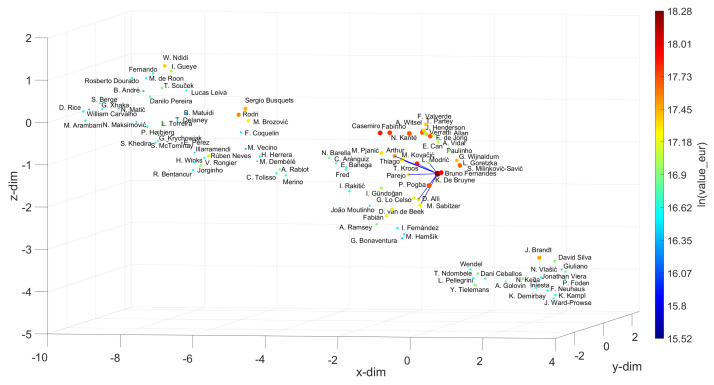
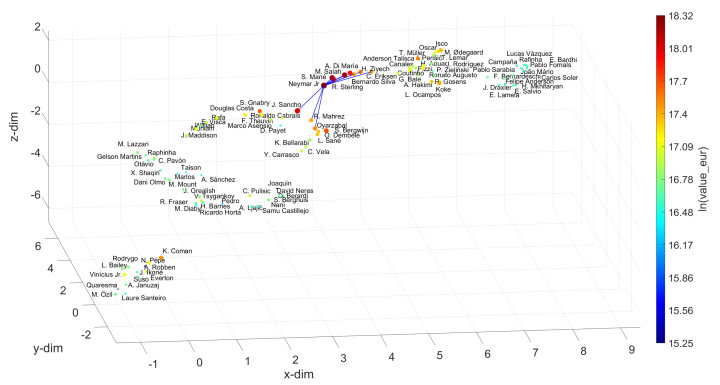
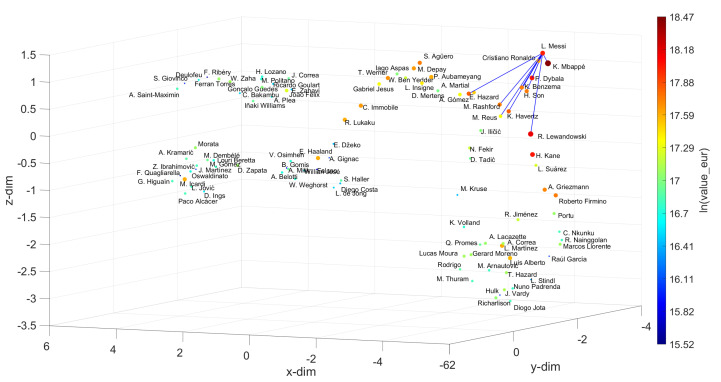
In professional soccer, the choices made in forming a team lineup are crucial for achieving good results. Players are characterized by different skills and their relevance depends on the position that they occupy on the pitch. Experts can recognize similarities between players and their styles, but the procedures adopted are often subjective and prone to misclassification. The automatic recognition of players' styles based on their diversity of skills can help coaches and technical directors to prepare a team for a competition, to substitute injured players during a season, or to hire players to fill gaps created by teammates that leave. The paper adopts dimensionality reduction, clustering and computer visualization tools to compare soccer players based on a set of attributes. The players are characterized by numerical vectors embedding their particular skills and these objects are then compared by means of suitable distances. The intermediate data is processed to generate meaningful representations of the original dataset according to the (dis)similarities between the objects. The results show that the adoption of dimensionality reduction, clustering and visualization tools for processing complex datasets is a key modeling option with current computational resources.
在职业足球中,组建球队阵容时做出的选择对于取得好成绩至关重要。球员具有不同的技能特点,其相关性取决于他们在球场上所占据的位置。专家能够识别球员及其风格之间的相似之处,但所采用的程序往往具有主观性且容易出现错误分类。基于球员技能多样性自动识别其风格,有助于教练和技术总监为比赛准备球队、在赛季中替换受伤球员,或招募球员填补离队队友造成的空缺。本文采用降维、聚类和计算机可视化工具,基于一组属性对足球运动员进行比较。球员由嵌入其特定技能的数值向量表征,然后通过合适的距离对这些对象进行比较。根据对象之间的(不)相似性对中间数据进行处理,以生成原始数据集的有意义表示。结果表明,采用降维、聚类和可视化工具处理复杂数据集,是利用当前计算资源的关键建模选项。