Structural Biology and Bioinformatics, Department of Biochemistry, University of Melbourne, Parkville 3052, Victoria, Australia.
Systems and Computational Biology, Bio21 Institute, University of Melbourne, Parkville 3052, Victoria, Australia.
J Chem Inf Model. 2021 Jul 26;61(7):3314-3322. doi: 10.1021/acs.jcim.1c00168. Epub 2021 Jul 2.
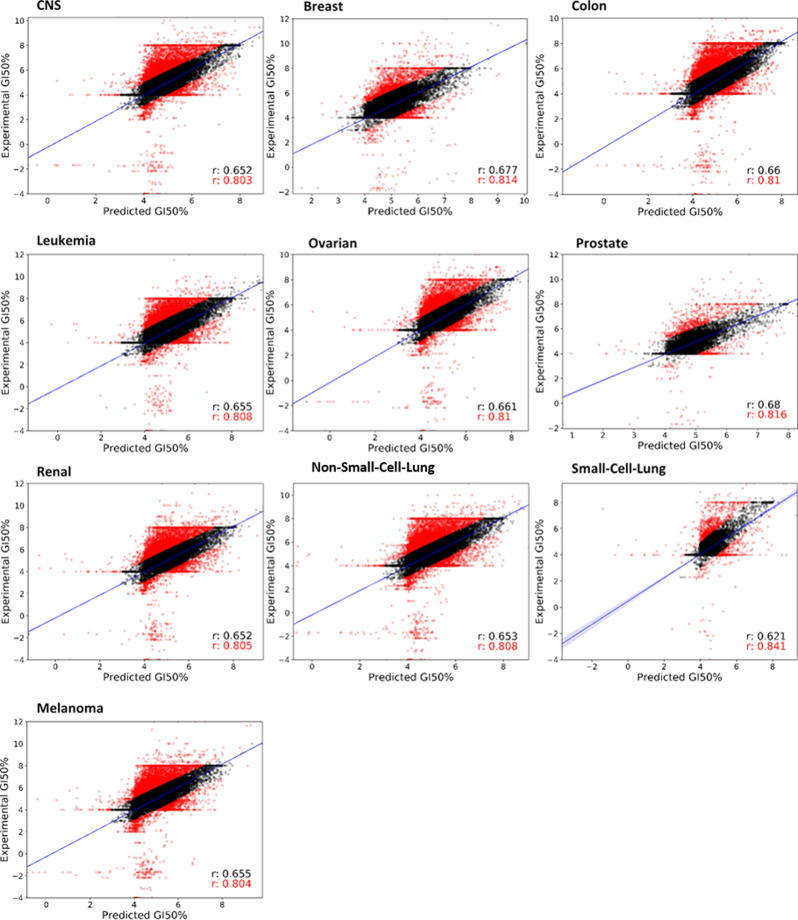
The development of new, effective, and safe drugs to treat cancer remains a challenging and time-consuming task due to limited hit rates, restraining subsequent development efforts. Despite the impressive progress of quantitative structure-activity relationship and machine learning-based models that have been developed to predict molecule pharmacodynamics and bioactivity, they have had mixed success at identifying compounds with anticancer properties against multiple cell lines. Here, we have developed a novel predictive tool, pdCSM-cancer, which uses a graph-based signature representation of the chemical structure of a small molecule in order to accurately predict molecules likely to be active against one or multiple cancer cell lines. pdCSM-cancer represents the most comprehensive anticancer bioactivity prediction platform developed till date, comprising trained and validated models on experimental data of the growth inhibition concentration (GI50%) effects, including over 18,000 compounds, on 9 tumor types and 74 distinct cancer cell lines. Across 10-fold cross-validation, it achieved Pearson's correlation coefficients of up to 0.74 and comparable performance of up to 0.67 across independent, non-redundant blind tests. Leveraging the insights from these cell line-specific models, we developed a generic predictive model to identify molecules active in at least 60 cell lines. Our final model achieved an area under the receiver operating characteristic curve (AUC) of up to 0.94 on 10-fold cross-validation and up to 0.94 on independent non-redundant blind tests, outperforming alternative approaches. We believe that our predictive tool will provide a valuable resource to optimizing and enriching screening libraries for the identification of effective and safe anticancer molecules. To provide a simple and integrated platform to rapidly screen for potential biologically active molecules with favorable anticancer properties, we made pdCSM-cancer freely available online at http://biosig.unimelb.edu.au/pdcsm_cancer.
开发新的、有效和安全的癌症治疗药物仍然是一项具有挑战性和耗时的任务,因为命中率有限,限制了后续的开发工作。尽管基于定量构效关系和机器学习的模型在预测分子药理学和生物活性方面取得了令人印象深刻的进展,但它们在识别具有多种细胞系抗癌特性的化合物方面的成功参差不齐。在这里,我们开发了一种新的预测工具 pdCSM-cancer,它使用小分子化学结构的基于图的签名表示来准确预测可能对一种或多种癌细胞系具有活性的分子。pdCSM-cancer 代表了迄今为止开发的最全面的抗癌生物活性预测平台,包括基于实验数据训练和验证的模型,这些数据涉及生长抑制浓度(GI50%)效应,包括超过 18000 种化合物,涉及 9 种肿瘤类型和 74 种不同的癌细胞系。在 10 倍交叉验证中,它达到了高达 0.74 的 Pearson 相关系数,在独立的、非冗余的盲测中表现相当,达到了 0.67。利用这些细胞系特异性模型的见解,我们开发了一种通用预测模型,用于识别至少 60 种细胞系中具有活性的分子。我们的最终模型在 10 倍交叉验证中达到了高达 0.94 的接收者操作特征曲线(AUC),在独立的非冗余盲测中达到了 0.94,优于替代方法。我们相信,我们的预测工具将为优化和丰富筛选库以识别有效和安全的抗癌分子提供有价值的资源。为了提供一个简单而集成的平台,快速筛选具有良好抗癌特性的潜在生物活性分子,我们在 http://biosig.unimelb.edu.au/pdcsm_cancer 上免费提供了 pdCSM-cancer。