Rajan Kohulan, Zielesny Achim, Steinbeck Christoph
Institute for Inorganic and Analytical Chemistry, Friedrich-Schiller-University Jena, Lessingstr. 8, 07743, Jena, Germany.
Institute for Bioinformatics and Chemoinformatics, Westphalian University of Applied Sciences, August-Schmidt-Ring 10, 45665, Recklinghausen, Germany.
J Cheminform. 2021 Aug 17;13(1):61. doi: 10.1186/s13321-021-00538-8.
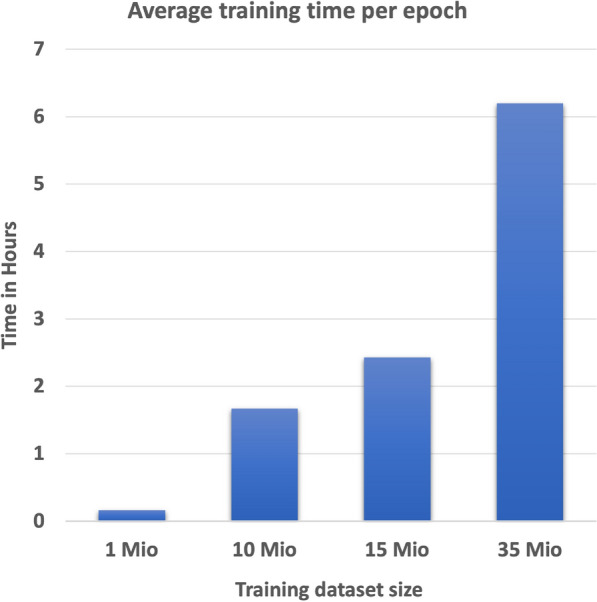
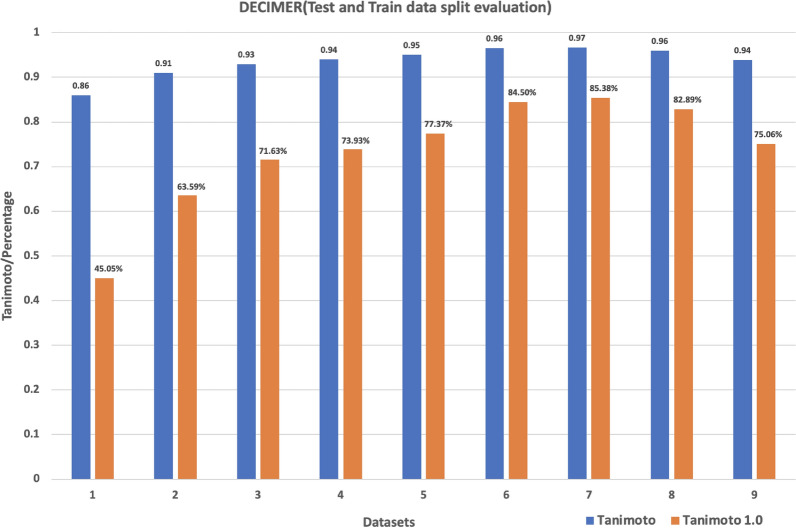
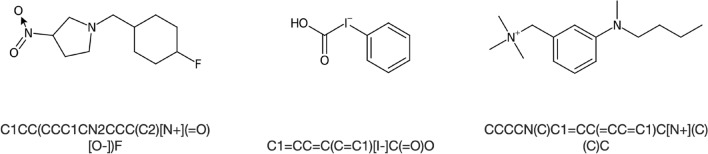
The amount of data available on chemical structures and their properties has increased steadily over the past decades. In particular, articles published before the mid-1990 are available only in printed or scanned form. The extraction and storage of data from those articles in a publicly accessible database are desirable, but doing this manually is a slow and error-prone process. In order to extract chemical structure depictions and convert them into a computer-readable format, Optical Chemical Structure Recognition (OCSR) tools were developed where the best performing OCSR tools are mostly rule-based. The DECIMER (Deep lEarning for Chemical ImagE Recognition) project was launched to address the OCSR problem with the latest computational intelligence methods to provide an automated open-source software solution. Various current deep learning approaches were explored to seek a best-fitting solution to the problem. In a preliminary communication, we outlined the prospect of being able to predict SMILES encodings of chemical structure depictions with about 90% accuracy using a dataset of 50-100 million molecules. In this article, the new DECIMER model is presented, a transformer-based network, which can predict SMILES with above 96% accuracy from depictions of chemical structures without stereochemical information and above 89% accuracy for depictions with stereochemical information.
在过去几十年里,关于化学结构及其性质的可用数据量一直在稳步增加。特别是,20世纪90年代中期之前发表的文章只有印刷版或扫描版。从这些文章中提取数据并存储到一个可公开访问的数据库中是很有必要的,但手动操作这个过程既缓慢又容易出错。为了提取化学结构描述并将其转换为计算机可读格式,人们开发了光学化学结构识别(OCSR)工具,其中性能最佳的OCSR工具大多基于规则。DECIMER(用于化学图像识别的深度学习)项目启动,旨在利用最新的计算智能方法解决OCSR问题,提供一个自动化的开源软件解决方案。人们探索了各种当前的深度学习方法,以寻求该问题的最佳解决方案。在一篇初步通讯中,我们概述了使用一个包含5000万到1亿个分子的数据集,能够以约90%的准确率预测化学结构描述的SMILES编码的前景。在本文中,我们展示了新的DECIMER模型,这是一个基于Transformer的网络,它可以从没有立体化学信息的化学结构描述中以高于96%的准确率预测SMILES,对于有立体化学信息的描述,准确率高于89%。