Lamurias Andre, Jesus Sofia, Neveu Vanessa, Salek Reza M, Couto Francisco M
LASIGE, Departamento de Informática, Faculdade de Ciências, Universidade de Lisboa, Lisbon, Portugal.
International Agency for Research on Cancer, Lyon, France.
Front Res Metr Anal. 2021 Aug 19;6:689264. doi: 10.3389/frma.2021.689264. eCollection 2021.
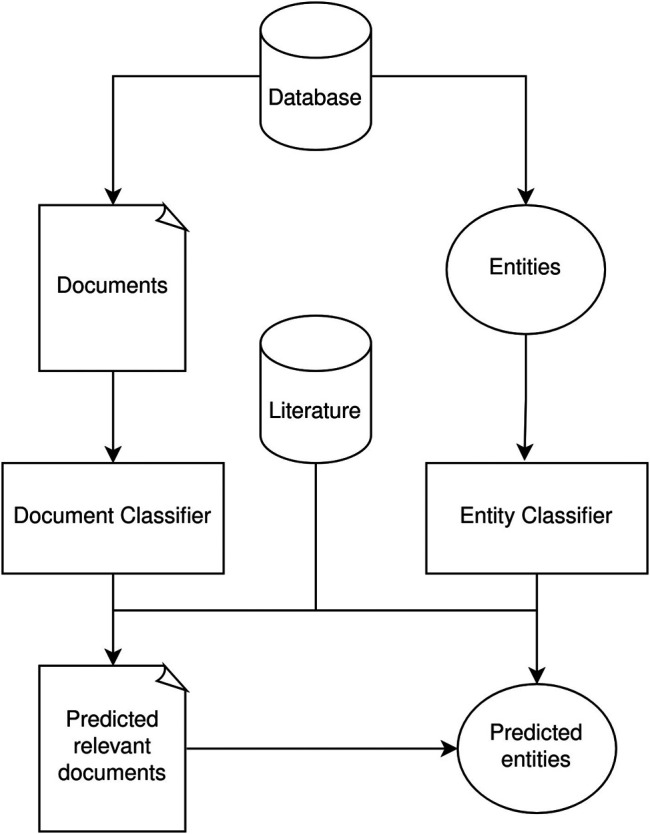
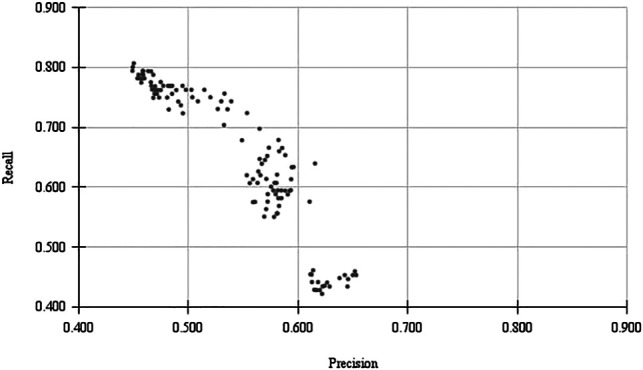
In 2016, the International Agency for Research on Cancer, part of the World Health Organization, released the Exposome-Explorer, the first database dedicated to biomarkers of exposure for environmental risk factors for diseases. The database contents resulted from a manual literature search that yielded over 8,500 citations, but only a small fraction of these publications were used in the final database. Manually curating a database is time-consuming and requires domain expertise to gather relevant data scattered throughout millions of articles. This work proposes a supervised machine learning pipeline to assist the manual literature retrieval process. The manually retrieved corpus of scientific publications used in the Exposome-Explorer was used as training and testing sets for the machine learning models (classifiers). Several parameters and algorithms were evaluated to predict an article's relevance based on different datasets made of titles, abstracts and metadata. The top performance classifier was built with the Logistic Regression algorithm using the title and abstract set, achieving an F2-score of 70.1%. Furthermore, we extracted 1,143 entities from these articles with a classifier trained for biomarker entity recognition. Of these, we manually validated 45 new candidate entries to the database. Our methodology reduced the number of articles to be manually screened by the database curators by nearly 90%, while only misclassifying 22.1% of the relevant articles. We expect that this methodology can also be applied to similar biomarkers datasets or be adapted to assist the manual curation process of similar chemical or disease databases.
2016年,作为世界卫生组织一部分的国际癌症研究机构发布了暴露组浏览器(Exposome-Explorer),这是首个致力于疾病环境风险因素暴露生物标志物的数据库。该数据库内容源自人工文献检索,检索出8500多条引用,但最终数据库仅使用了其中一小部分出版物。人工整理数据库耗时且需要领域专业知识来收集分散在数百万篇文章中的相关数据。这项工作提出了一种监督式机器学习流程来辅助人工文献检索过程。暴露组浏览器中使用的人工检索的科学出版物语料库被用作机器学习模型(分类器)的训练和测试集。基于由标题、摘要和元数据组成的不同数据集,对几个参数和算法进行了评估,以预测文章的相关性。性能最佳的分类器是使用逻辑回归算法基于标题和摘要集构建的,F2分数达到70.1%。此外,我们使用为生物标志物实体识别训练的分类器从这些文章中提取了1143个实体。其中,我们人工验证了45个数据库的新候选条目。我们的方法将数据库策展人需要人工筛选的文章数量减少了近90%,而仅将22.1%的相关文章误分类。我们预计这种方法也可应用于类似的生物标志物数据集,或进行调整以辅助类似化学或疾病数据库的人工整理过程。