Department of Neurology and Alzheimer Center, Erasmus University Medical Center, 3015 GD Rotterdam, The Netherlands.
Department of Radiology and Nuclear Medicine, Erasmus University Medical Center, 3015 GD Rotterdam, The Netherlands.
Brain. 2022 Jun 3;145(5):1805-1817. doi: 10.1093/brain/awab382.
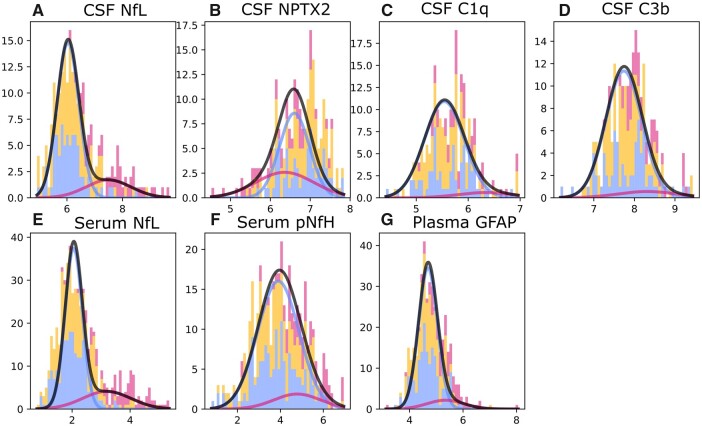
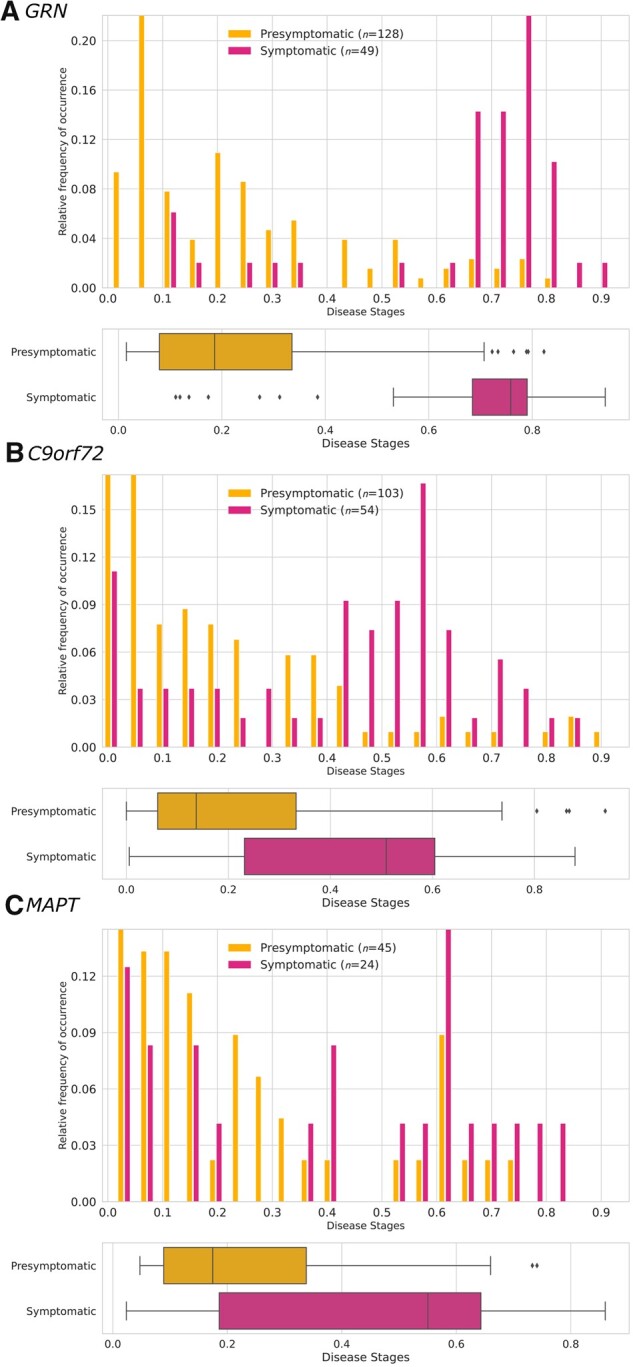
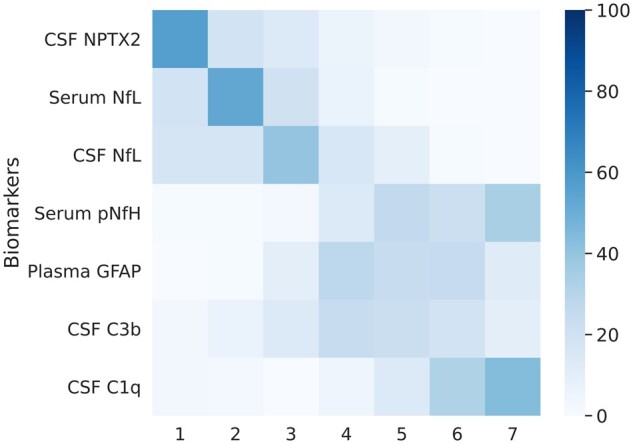
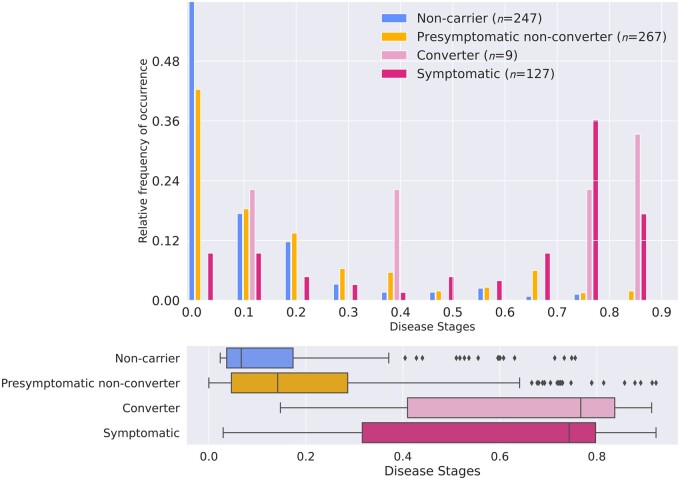
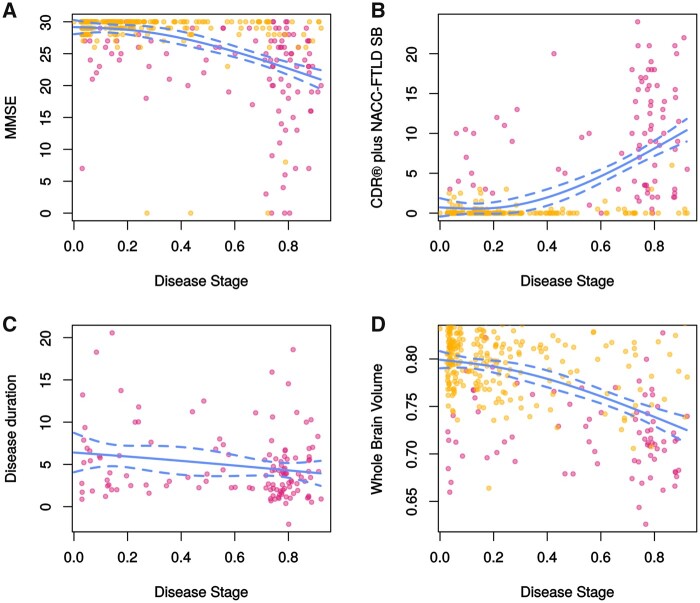
Several CSF and blood biomarkers for genetic frontotemporal dementia have been proposed, including those reflecting neuroaxonal loss (neurofilament light chain and phosphorylated neurofilament heavy chain), synapse dysfunction [neuronal pentraxin 2 (NPTX2)], astrogliosis (glial fibrillary acidic protein) and complement activation (C1q, C3b). Determining the sequence in which biomarkers become abnormal over the course of disease could facilitate disease staging and help identify mutation carriers with prodromal or early-stage frontotemporal dementia, which is especially important as pharmaceutical trials emerge. We aimed to model the sequence of biomarker abnormalities in presymptomatic and symptomatic genetic frontotemporal dementia using cross-sectional data from the Genetic Frontotemporal dementia Initiative (GENFI), a longitudinal cohort study. Two-hundred and seventy-five presymptomatic and 127 symptomatic carriers of mutations in GRN, C9orf72 or MAPT, as well as 247 non-carriers, were selected from the GENFI cohort based on availability of one or more of the aforementioned biomarkers. Nine presymptomatic carriers developed symptoms within 18 months of sample collection ('converters'). Sequences of biomarker abnormalities were modelled for the entire group using discriminative event-based modelling (DEBM) and for each genetic subgroup using co-initialized DEBM. These models estimate probabilistic biomarker abnormalities in a data-driven way and do not rely on previous diagnostic information or biomarker cut-off points. Using cross-validation, subjects were subsequently assigned a disease stage based on their position along the disease progression timeline. CSF NPTX2 was the first biomarker to become abnormal, followed by blood and CSF neurofilament light chain, blood phosphorylated neurofilament heavy chain, blood glial fibrillary acidic protein and finally CSF C3b and C1q. Biomarker orderings did not differ significantly between genetic subgroups, but more uncertainty was noted in the C9orf72 and MAPT groups than for GRN. Estimated disease stages could distinguish symptomatic from presymptomatic carriers and non-carriers with areas under the curve of 0.84 (95% confidence interval 0.80-0.89) and 0.90 (0.86-0.94) respectively. The areas under the curve to distinguish converters from non-converting presymptomatic carriers was 0.85 (0.75-0.95). Our data-driven model of genetic frontotemporal dementia revealed that NPTX2 and neurofilament light chain are the earliest to change among the selected biomarkers. Further research should investigate their utility as candidate selection tools for pharmaceutical trials. The model's ability to accurately estimate individual disease stages could improve patient stratification and track the efficacy of therapeutic interventions.
已经提出了几种用于遗传性额颞叶痴呆的 CSF 和血液生物标志物,包括反映神经轴索丢失的标志物(神经丝轻链和磷酸化神经丝重链)、突触功能障碍标志物[神经元五聚素 2(NPTX2)]、星形胶质细胞增生标志物(胶质纤维酸性蛋白)和补体激活标志物(C1q、C3b)。确定生物标志物在疾病过程中异常的顺序可以促进疾病分期,并有助于识别具有前驱期或早期额颞叶痴呆的突变携带者,这在出现药物试验时尤为重要。我们旨在使用遗传额颞叶痴呆倡议(GENFI)的横断面数据,通过对前瞻性和症状性遗传额颞叶痴呆的生物标志物进行建模,该研究是一项纵向队列研究。根据上述生物标志物之一或多个的可用性,从 GENFI 队列中选择了 275 名无症状和 127 名有症状的 GRN、C9orf72 或 MAPT 突变携带者,以及 247 名非携带者。使用判别事件驱动建模(DEBM)对整个组和每个遗传亚组使用共同初始化的 DEBM 对生物标志物异常的顺序进行建模。这些模型以数据驱动的方式估计生物标志物异常的概率,不依赖于先前的诊断信息或生物标志物截止值。通过交叉验证,根据其在疾病进展时间线上的位置,随后将受试者分配到疾病阶段。CSF NPTX2 是第一个异常的生物标志物,其次是血液和 CSF 神经丝轻链、血液磷酸化神经丝重链、血液胶质纤维酸性蛋白,最后是 CSF C3b 和 C1q。生物标志物的排序在遗传亚组之间没有显著差异,但在 C9orf72 和 MAPT 组中注意到更多的不确定性。估计的疾病阶段可以区分症状性和无症状携带者以及非携带者,曲线下面积分别为 0.84(95%置信区间 0.80-0.89)和 0.90(0.86-0.94)。区分从非转化无症状携带者转变为转化无症状携带者的曲线下面积为 0.85(0.75-0.95)。我们对遗传性额颞叶痴呆的基于数据的模型表明,在选定的生物标志物中,NPTX2 和神经丝轻链是最早发生变化的。进一步的研究应该调查它们作为药物试验候选选择工具的效用。该模型准确估计个体疾病阶段的能力可以改善患者分层并跟踪治疗干预的效果。