Department of Emotion Engineering, University of Sangmyung, Seoul 03016, Korea.
Department of Human Centered Artificial Intelligence, University of Sangmyung, Seoul 03016, Korea.
Sensors (Basel). 2021 Oct 26;21(21):7111. doi: 10.3390/s21217111.
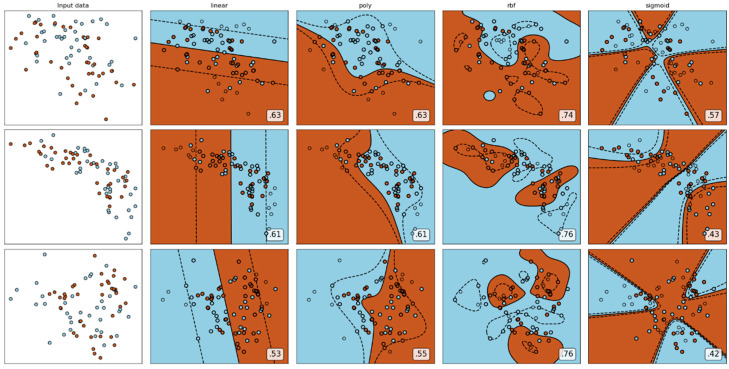
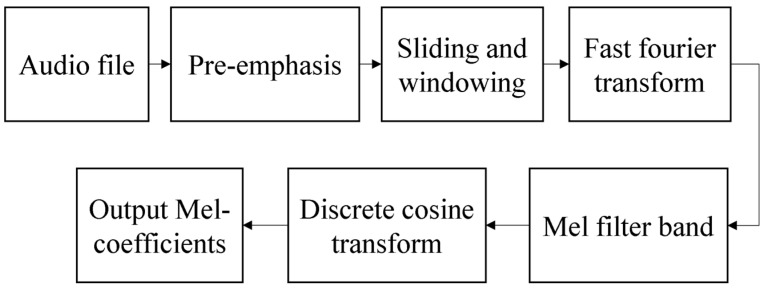
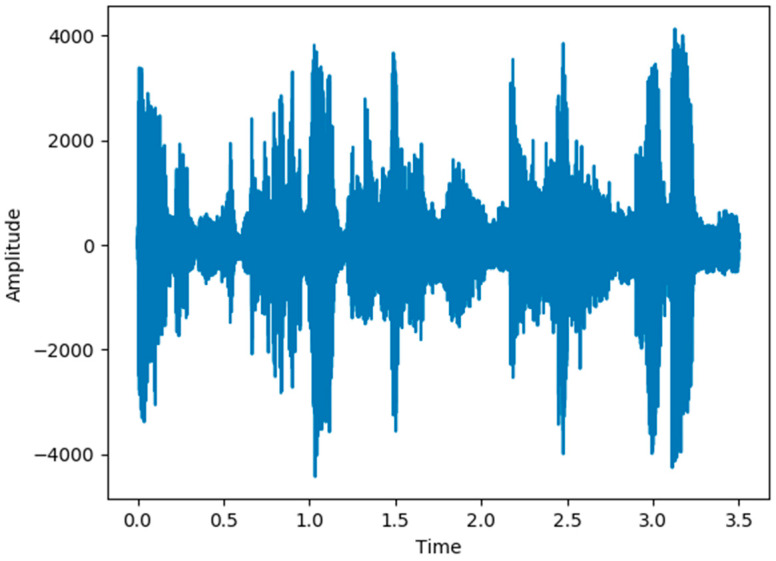
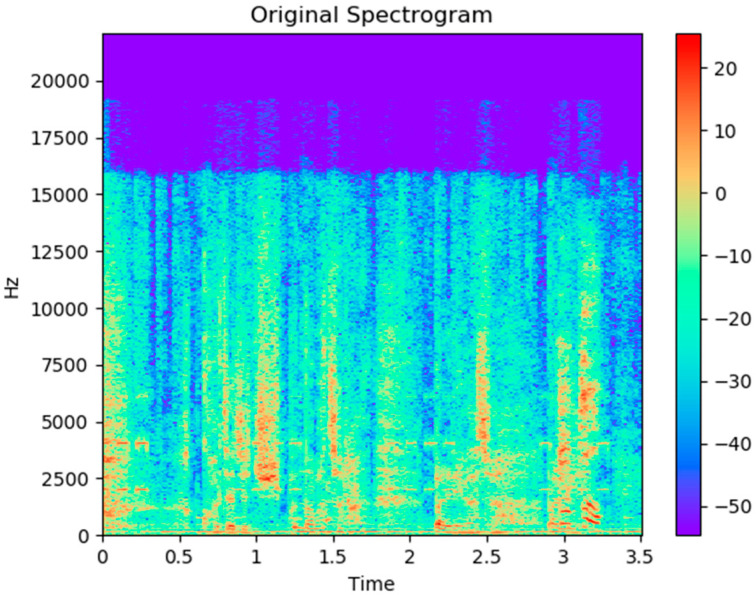
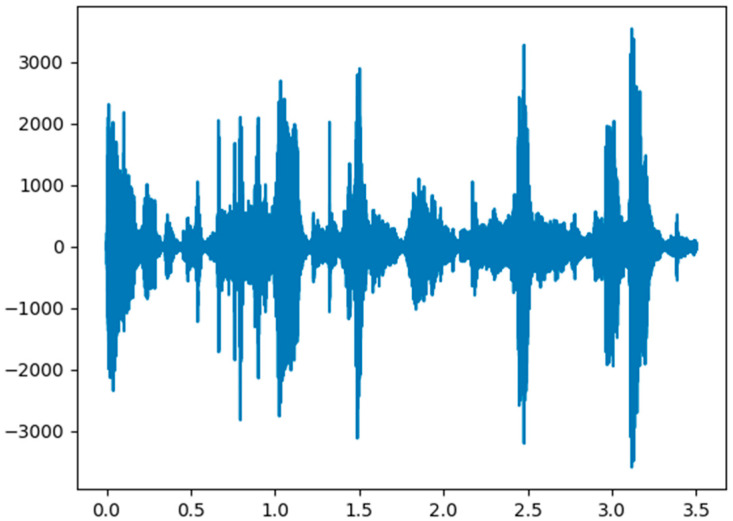
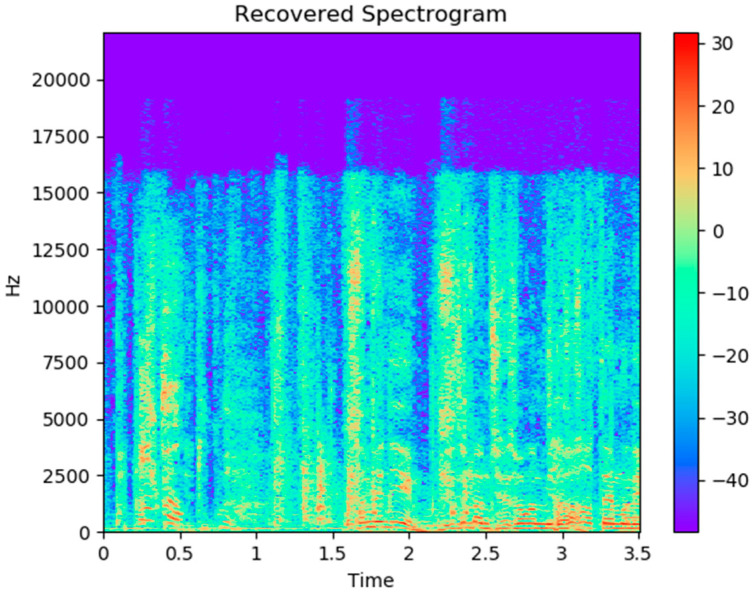
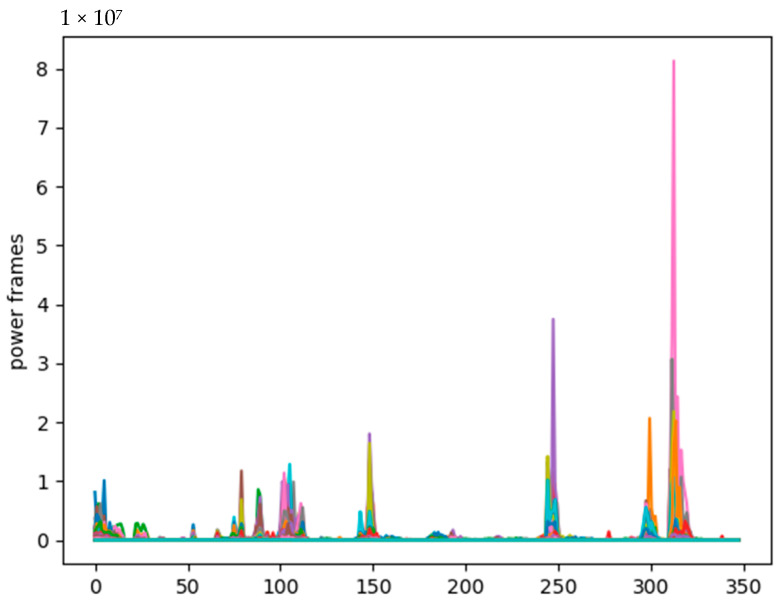
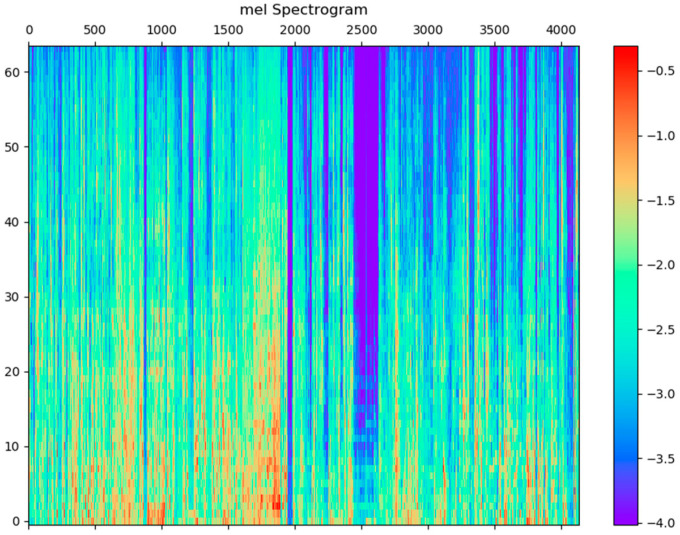
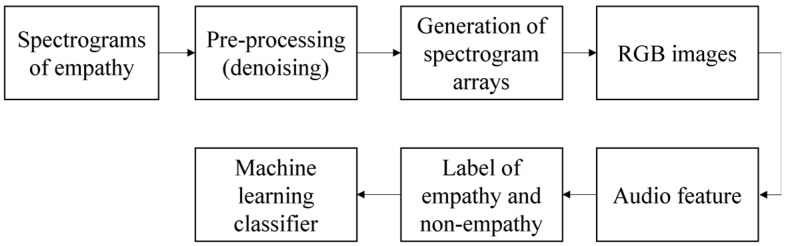
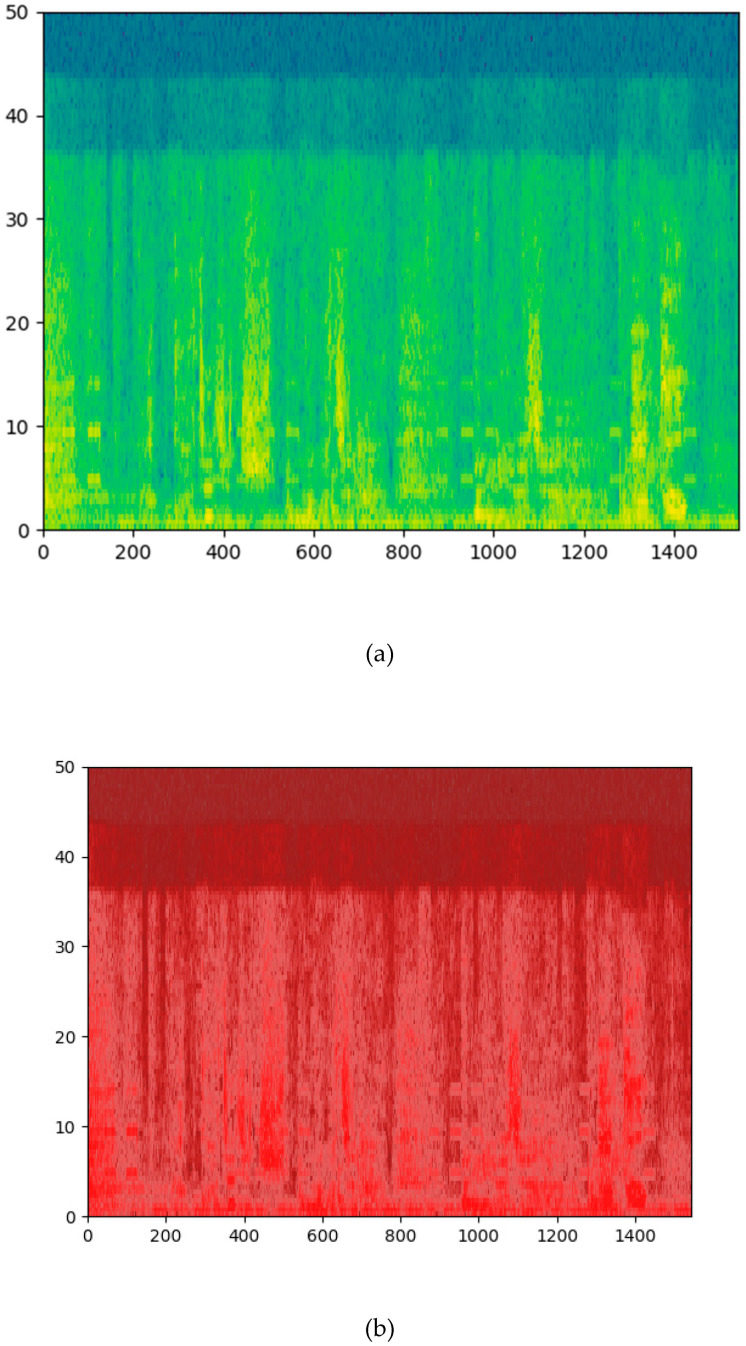
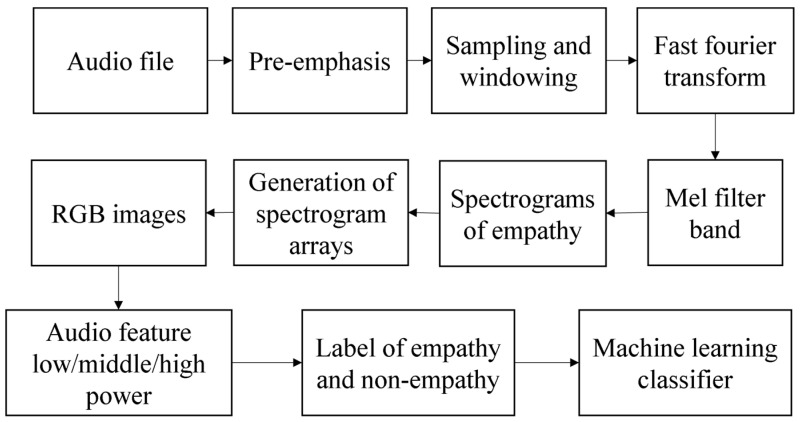
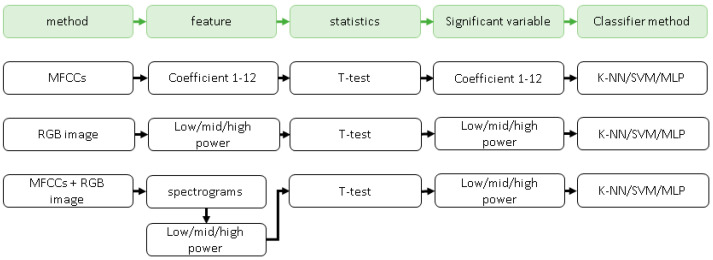
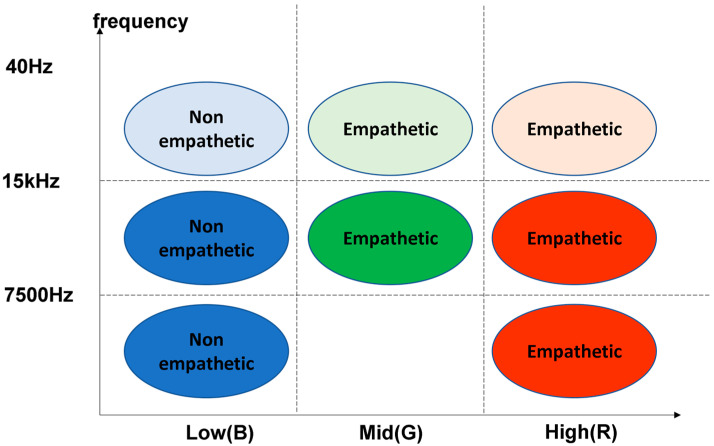
Watching videos online has become part of a relaxed lifestyle. The music in videos has a sensitive influence on human emotions, perception, and imaginations, which can make people feel relaxed or sad, and so on. Therefore, it is particularly important for people who make advertising videos to understand the relationship between the physical elements of music and empathy characteristics. The purpose of this paper is to analyze the music features in an advertising video and extract the music features that make people empathize. This paper combines both methods of the power spectrum of MFCC and image RGB analysis to find the audio feature vector. In spectral analysis, the eigenvectors obtained in the analysis process range from blue (low range) to green (medium range) to red (high range). The machine learning random forest classifier is used to classify the data obtained by machine learning, and the trained model is used to monitor the development of an advertisement empathy system in real time. The result is that the optimal model is obtained with the training accuracy result of 99.173% and a test accuracy of 86.171%, which can be deemed as correct by comparing the three models of audio feature value analysis. The contribution of this study can be summarized as follows: (1) the low-frequency and high-amplitude audio in the video is more likely to resonate than the high-frequency and high-amplitude audio; (2) it is found that frequency and audio amplitude are important attributes for describing waveforms by observing the characteristics of the machine learning classifier; (3) a new audio extraction method is proposed to induce human empathy. That is, the feature value extracted by the method of spectrogram image features of audio has the most ability to arouse human empathy.
在线观看视频已经成为一种轻松生活方式的一部分。视频中的音乐对人类的情感、感知和想象力有着敏感的影响,可以让人感到放松或悲伤等。因此,对于制作广告视频的人来说,了解音乐的物理元素与同理心特征之间的关系尤为重要。本文旨在分析广告视频中的音乐特征,并提取出能引起人们共鸣的音乐特征。本文结合 MFCC 功率谱和图像 RGB 分析两种方法来找到音频特征向量。在频谱分析中,分析过程中获得的特征向量从蓝色(低频)到绿色(中频)到红色(高频)逐渐变化。采用机器学习随机森林分类器对机器学习获得的数据进行分类,并使用训练好的模型实时监测广告共鸣系统的发展。结果表明,最优模型的训练准确率为 99.173%,测试准确率为 86.171%,通过比较三种音频特征值分析模型,可以认为结果是正确的。本研究的贡献可以总结如下:(1)视频中低频、高振幅的音频比高频、高振幅的音频更容易产生共鸣;(2)通过观察机器学习分类器的特征,可以发现频率和音频幅度是描述波形的重要属性;(3)提出了一种新的音频提取方法来引发人类共鸣。即通过音频的频谱图像特征提取的特征值最能引起人类共鸣。