Bertrand Frédéric, Maumy-Bertrand Myriam
LIST3N, Université de Technologie de Troyes, Troyes, France.
IRMA, CNRS UMR 7501, Labex IRMIA, Université de Strasbourg, Strasbourg, France.
Front Big Data. 2021 Nov 1;4:684794. doi: 10.3389/fdata.2021.684794. eCollection 2021.
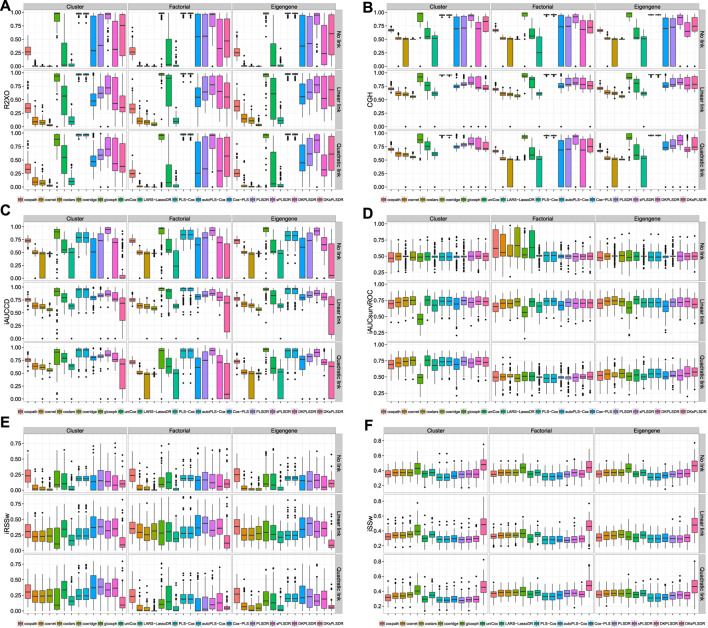
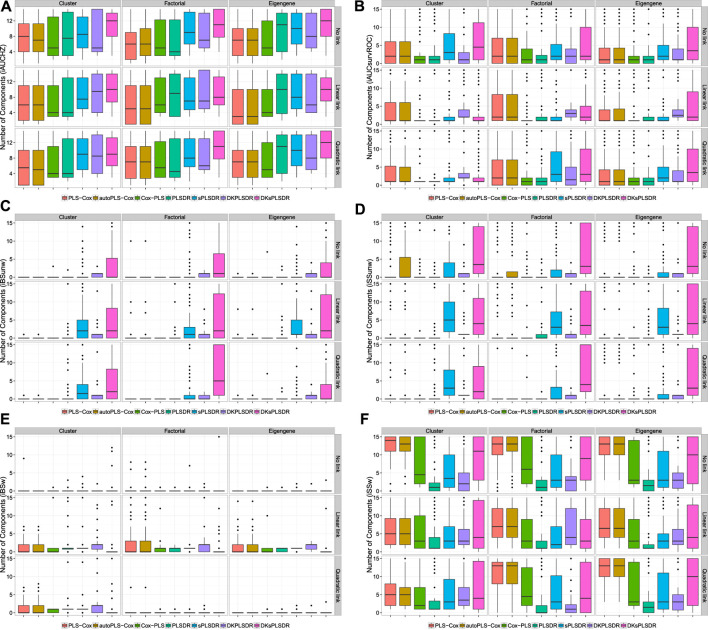
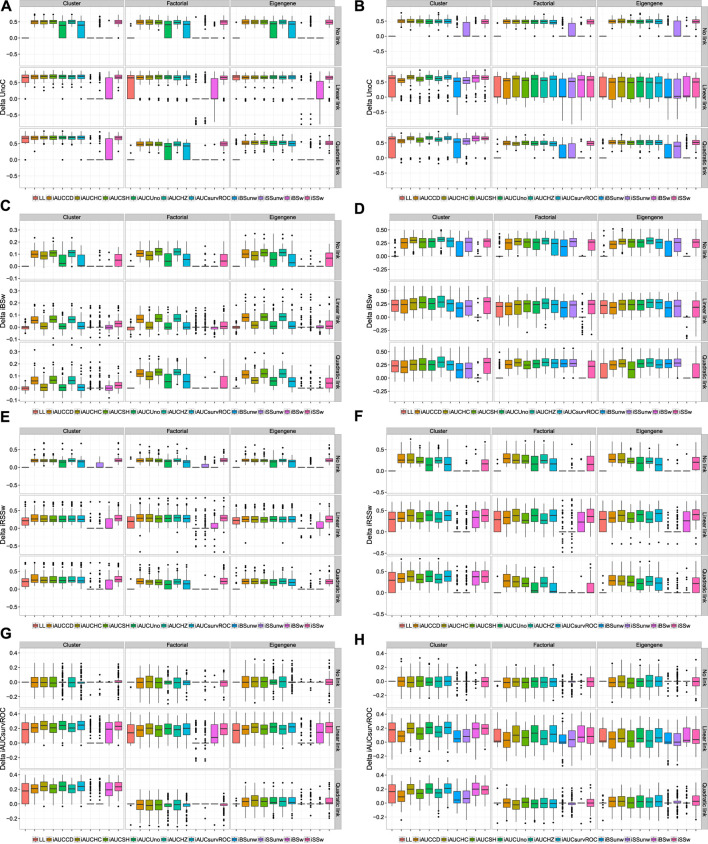
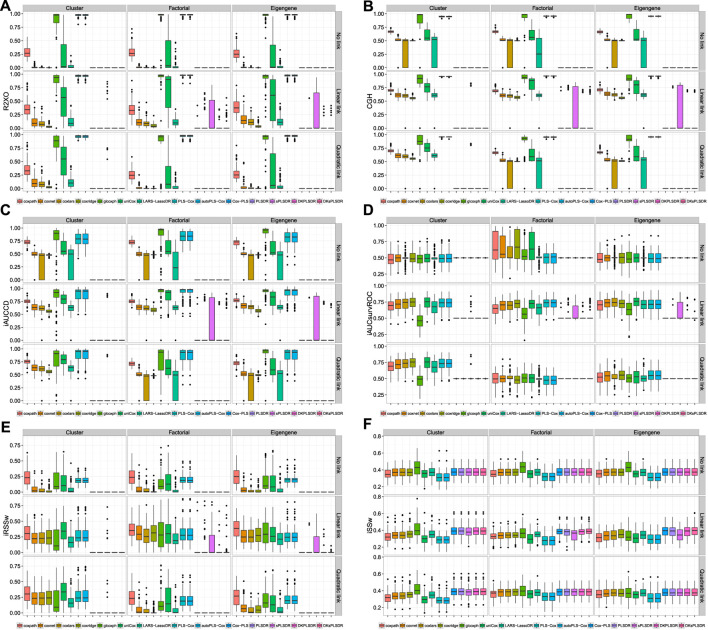
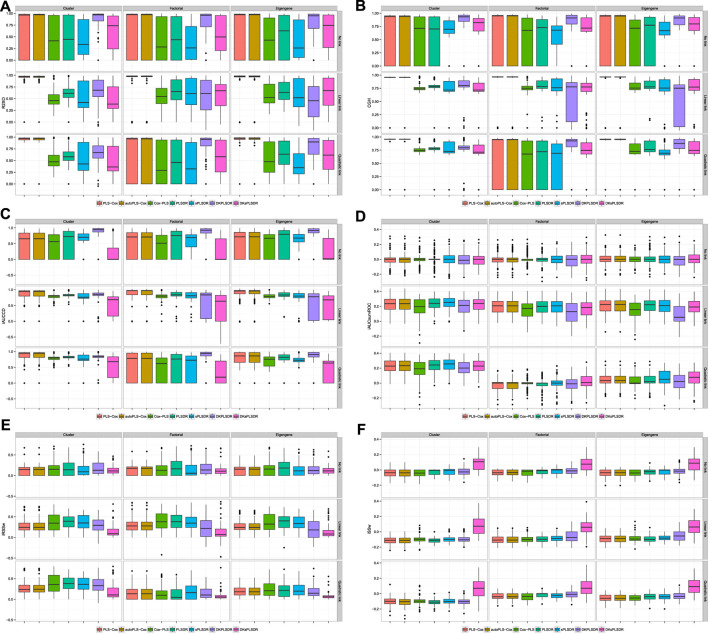
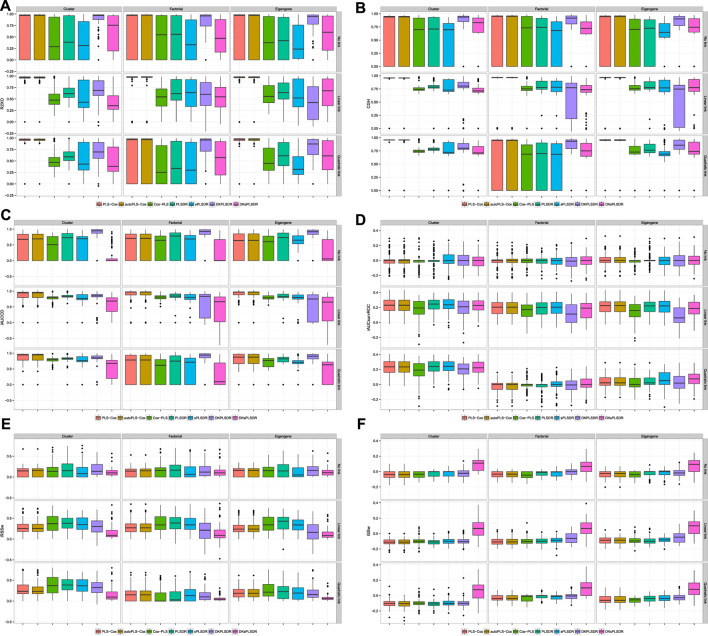
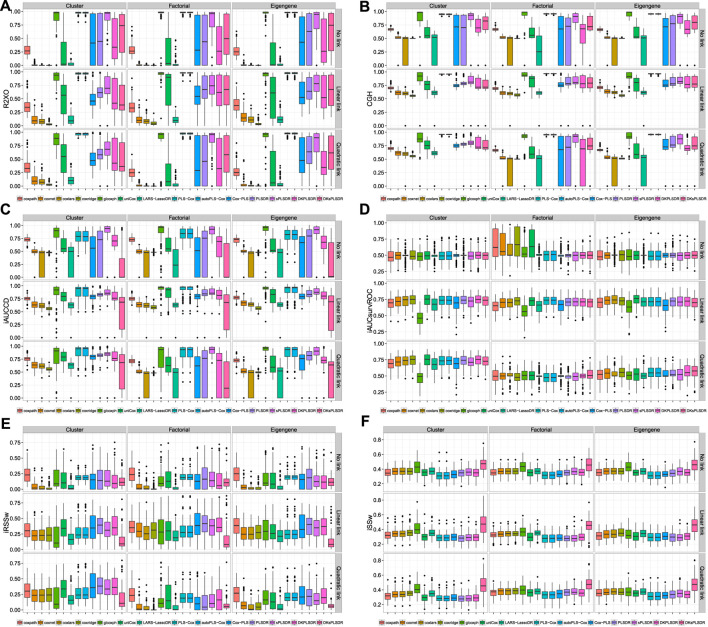
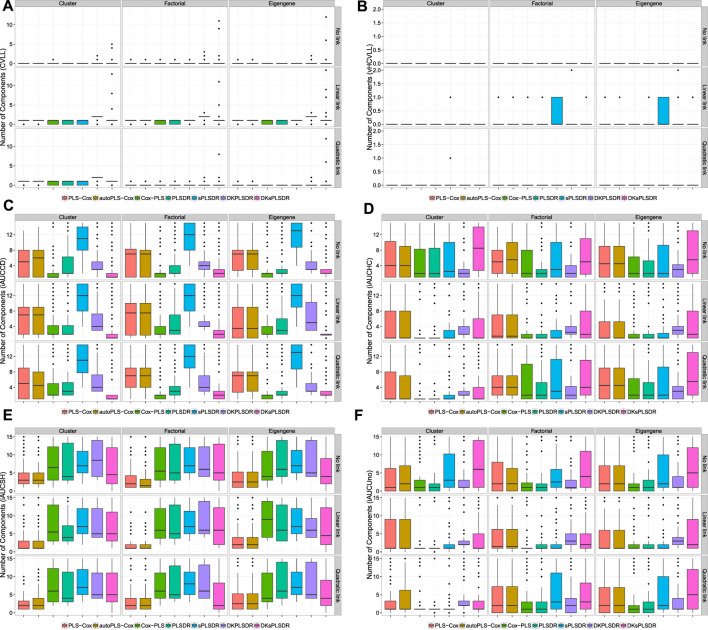
Fitting Cox models in a big data context -on a massive scale in terms of volume, intensity, and complexity exceeding the capacity of usual analytic tools-is often challenging. If some data are missing, it is even more difficult. We proposed algorithms that were able to fit Cox models in high dimensional settings using extensions of partial least squares regression to the Cox models. Some of them were able to cope with missing data. We were recently able to extend our most recent algorithms to big data, thus allowing to fit Cox model for big data with missing values. When cross-validating standard or extended Cox models, the commonly used criterion is the cross-validated partial loglikelihood using a naive or a van Houwelingen scheme -to make efficient use of the death times of the left out data in relation to the death times of all the data. Quite astonishingly, we will show, using a strong simulation study involving three different data simulation algorithms, that these two cross-validation methods fail with the extensions, either straightforward or more involved ones, of partial least squares regression to the Cox model. This is quite an interesting result for at least two reasons. Firstly, several nice features of PLS based models, including regularization, interpretability of the components, missing data support, data visualization thanks to biplots of individuals and variables -and even parsimony or group parsimony for Sparse partial least squares or sparse group SPLS based models, account for a common use of these extensions by statisticians who usually select their hyperparameters using cross-validation. Secondly, they are almost always featured in benchmarking studies to assess the performance of a new estimation technique used in a high dimensional or big data context and often show poor statistical properties. We carried out a vast simulation study to evaluate more than a dozen of potential cross-validation criteria, either AUC or prediction error based. Several of them lead to the selection of a reasonable number of components. Using these newly found cross-validation criteria to fit extensions of partial least squares regression to the Cox model, we performed a benchmark reanalysis that showed enhanced performances of these techniques. In addition, we proposed sparse group extensions of our algorithms and defined a new robust measure based on the Schmid score and the R coefficient of determination for least absolute deviation: the integrated R Schmid Score weighted. The R-package used in this article is available on the CRAN, http://cran.r-project.org/web/packages/plsRcox/index.html. The R package bigPLS will soon be available on the CRAN and, until then, is available on Github https://github.com/fbertran/bigPLS.
在大数据环境中拟合Cox模型——在规模、强度和复杂性方面达到大规模,超出了常规分析工具的处理能力——通常具有挑战性。如果存在一些缺失数据,那就更加困难了。我们提出了一些算法,能够通过将偏最小二乘回归扩展到Cox模型,在高维设置下拟合Cox模型。其中一些算法能够处理缺失数据。最近,我们能够将最新算法扩展到大数据领域,从而能够为存在缺失值的大数据拟合Cox模型。在对标准或扩展的Cox模型进行交叉验证时,常用的标准是使用朴素或范霍韦林根方案的交叉验证偏对数似然——以便有效利用留出数据的死亡时间与所有数据的死亡时间的关系。相当令人惊讶的是,我们将通过一项涉及三种不同数据模拟算法的强大模拟研究表明,这两种交叉验证方法在将偏最小二乘回归扩展到Cox模型的直接或更复杂的扩展中均会失败。这是一个相当有趣的结果,至少有两个原因。首先,基于偏最小二乘的模型具有几个不错的特性,包括正则化、成分的可解释性、对缺失数据的支持、由于个体和变量的双标图实现的数据可视化——甚至对于基于稀疏偏最小二乘或稀疏组偏最小二乘的模型具有简约性或组简约性,这使得统计学家经常使用这些扩展,他们通常通过交叉验证来选择超参数。其次,它们几乎总是出现在基准研究中,以评估在高维或大数据环境中使用的新估计技术的性能,并且往往显示出较差的统计特性。我们进行了一项广泛的模拟研究,以评估十几种潜在的交叉验证标准,这些标准要么基于AUC,要么基于预测误差。其中一些标准能够导致选择合理数量的成分。使用这些新发现的交叉验证标准来拟合偏最小二乘回归到Cox模型的扩展,我们进行了一次基准重新分析,结果显示这些技术的性能有所提高。此外,我们提出了算法的稀疏组扩展,并基于施密德分数和最小绝对偏差的决定系数R定义了一种新的稳健度量:加权积分R施密德分数。本文中使用的R包可在CRAN上获取,网址为http://cran.r-project.org/web/packages/plsRcox/index.html。R包bigPLS很快将在CRAN上提供,在此之前,可在Github上获取,网址为https://github.com/fbertran/bigPLS。