Alanazi Eman M, Abdou Aalaa, Luo Jake
Department of Health Informatics, College of Health Sciences, Saudi Electronic University, Riyadh, Saudi Arabia.
Department of Biomedical and Health Informatics, College of Engineering, University of Wisconsin-Milwaukee, Milwaukee, WI, United States.
JMIR Form Res. 2021 Dec 2;5(12):e23440. doi: 10.2196/23440.
Stroke, a cerebrovascular disease, is one of the major causes of death. It causes significant health and financial burdens for both patients and health care systems. One of the important risk factors for stroke is health-related behavior, which is becoming an increasingly important focus of prevention. Many machine learning models have been built to predict the risk of stroke or to automatically diagnose stroke, using predictors such as lifestyle factors or radiological imaging. However, there have been no models built using data from lab tests.
The aim of this study was to apply computational methods using machine learning techniques to predict stroke from lab test data.
We used the National Health and Nutrition Examination Survey data sets with three different data selection methods (ie, without data resampling, with data imputation, and with data resampling) to develop predictive models. We used four machine learning classifiers and six performance measures to evaluate the performance of the models.
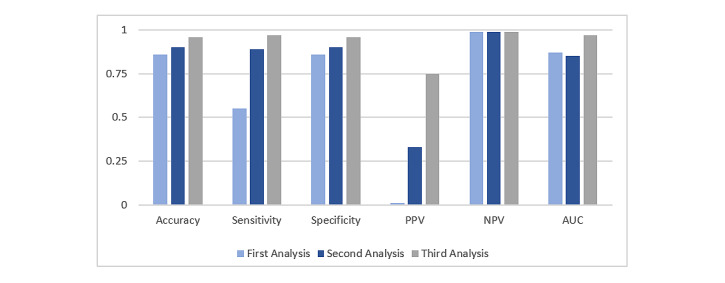
We found that accurate and sensitive machine learning models can be created to predict stroke from lab test data. Our results show that the data resampling approach performed the best compared to the other two data selection techniques. Prediction with the random forest algorithm, which was the best algorithm tested, achieved an accuracy, sensitivity, specificity, positive predictive value, negative predictive value, and area under the curve of 0.96, 0.97, 0.96, 0.75, 0.99, and 0.97, respectively, when all of the attributes were used.
The predictive model, built using data from lab tests, was easy to use and had high accuracy. In future studies, we aim to use data that reflect different types of stroke and to explore the data to build a prediction model for each type.
中风作为一种脑血管疾病,是主要死因之一。它给患者和医疗保健系统带来了巨大的健康和经济负担。与健康相关的行为是中风的重要风险因素之一,正日益成为预防的重要焦点。许多机器学习模型已被构建用于预测中风风险或自动诊断中风,使用生活方式因素或放射影像学等预测指标。然而,尚未有使用实验室检测数据构建的模型。
本研究的目的是应用机器学习技术的计算方法,从实验室检测数据预测中风。
我们使用国家健康与营养检查调查数据集,采用三种不同的数据选择方法(即不进行数据重采样、进行数据插补和进行数据重采样)来开发预测模型。我们使用四种机器学习分类器和六种性能指标来评估模型的性能。
我们发现可以创建准确且灵敏的机器学习模型,从实验室检测数据预测中风。我们的结果表明,与其他两种数据选择技术相比,数据重采样方法表现最佳。使用测试中最佳算法随机森林算法进行预测时,当使用所有属性时,准确率、灵敏度、特异性、阳性预测值、阴性预测值和曲线下面积分别达到0.96、0.97、0.96、0.75、0.99和0.97。
使用实验室检测数据构建的预测模型易于使用且具有高准确率。在未来研究中,我们旨在使用反映不同类型中风的数据,并探索这些数据以构建每种类型的预测模型。