Zhuang Jujuan, Liu Danyang, Lin Meng, Qiu Wenjing, Liu Jinyang, Chen Size
College of Science, Dalian Maritime University, Dalian, China.
Electrical and Information Engineering, Anhui University of Technology, Anhui, China.
Front Genet. 2021 Nov 18;12:773882. doi: 10.3389/fgene.2021.773882. eCollection 2021.
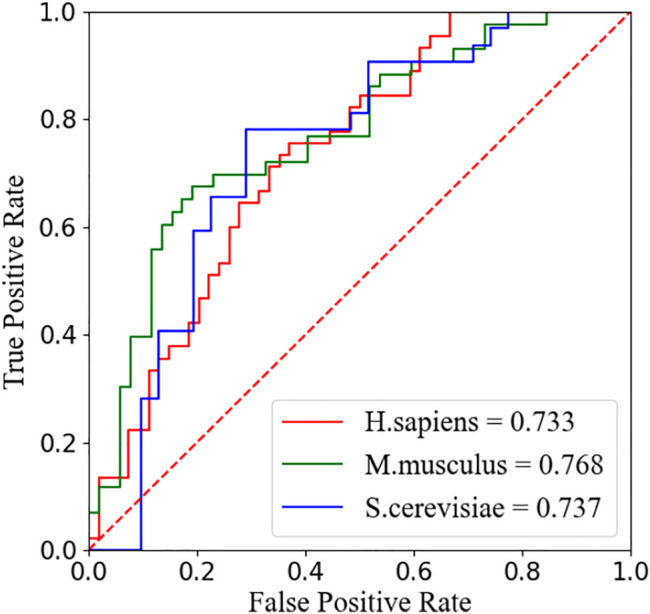
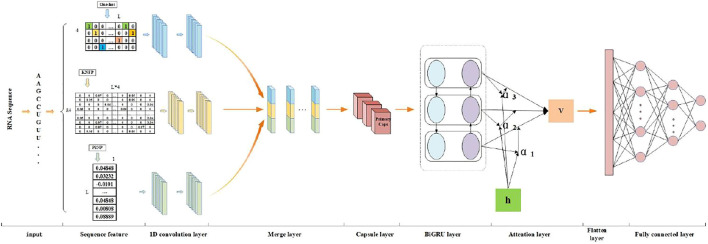
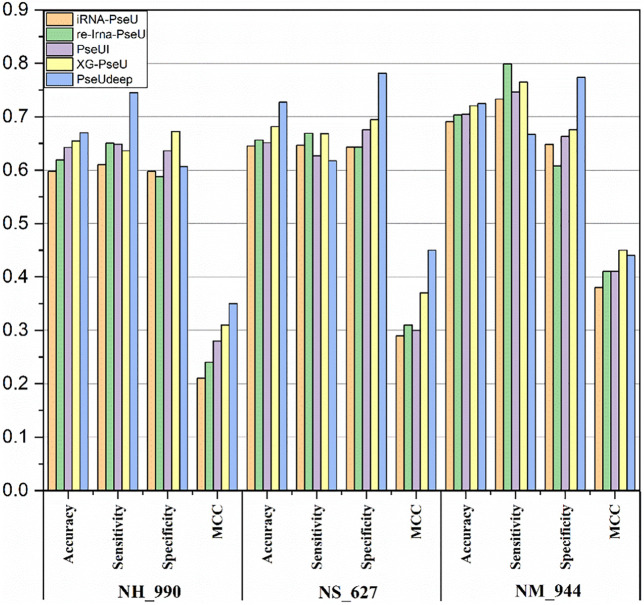
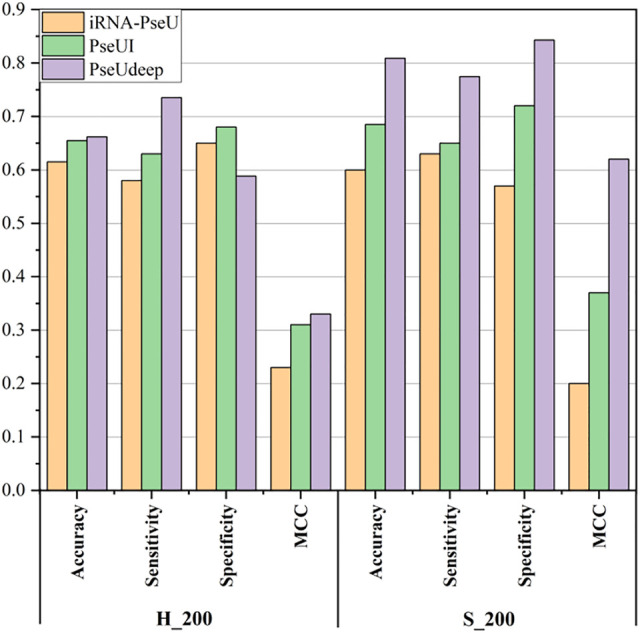
Pseudouridine (Ψ) is a common ribonucleotide modification that plays a significant role in many biological processes. The identification of Ψ modification sites is of great significance for disease mechanism and biological processes research in which machine learning algorithms are desirable as the lab exploratory techniques are expensive and time-consuming. In this work, we propose a deep learning framework, called PseUdeep, to identify Ψ sites of three species: , , and . In this method, three encoding methods are used to extract the features of RNA sequences, that is, one-hot encoding, K-tuple nucleotide frequency pattern, and position-specific nucleotide composition. The three feature matrices are convoluted twice and fed into the capsule neural network and bidirectional gated recurrent unit network with a self-attention mechanism for classification. Compared with other state-of-the-art methods, our model gets the highest accuracy of the prediction on the independent testing data set S-200; the accuracy improves 12.38%, and on the independent testing data set H-200, the accuracy improves 0.68%. Moreover, the dimensions of the features we derive from the RNA sequences are only 109,109, and 119 in , , and , which is much smaller than those used in the traditional algorithms. On evaluation via tenfold cross-validation and two independent testing data sets, PseUdeep outperforms the best traditional machine learning model available. PseUdeep source code and data sets are available at https://github.com/dan111262/PseUdeep.
假尿苷(Ψ)是一种常见的核糖核苷酸修饰,在许多生物过程中发挥着重要作用。Ψ修饰位点的识别对于疾病机制和生物过程研究具有重要意义,而机器学习算法是理想的选择,因为实验室探索技术既昂贵又耗时。在这项工作中,我们提出了一种名为PseUdeep的深度学习框架,用于识别三种物种的Ψ位点:[此处原文缺失物种名称]、[此处原文缺失物种名称]和[此处原文缺失物种名称]。在这种方法中,使用了三种编码方法来提取RNA序列的特征,即独热编码、K元核苷酸频率模式和位置特异性核苷酸组成。将这三个特征矩阵进行两次卷积,然后输入到具有自注意力机制的胶囊神经网络和双向门控循环单元网络中进行分类。与其他现有最先进的方法相比,我们的模型在独立测试数据集S - 200上的预测准确率最高;准确率提高了12.38%,在独立测试数据集H - 200上,准确率提高了0.68%。此外,我们从RNA序列中得出的特征维度在[此处原文缺失物种名称]、[此处原文缺失物种名称]和[此处原文缺失物种名称]中分别仅为109、109和119,远小于传统算法中使用的维度。通过十折交叉验证和两个独立测试数据集进行评估时发现PseUdeep优于现有的最佳传统机器学习模型。PseUdeep的源代码和数据集可在https://github.com/dan111262/PseUdeep获取。