Department of Psychological and Brain Sciences, Dartmouth College, Hanover, NH, USA.
Center for Computational Neuroscience, Flatiron Institute, Simons Foundation, New York, NY, USA.
Nat Commun. 2021 Dec 10;12(1):7191. doi: 10.1038/s41467-021-27413-2.
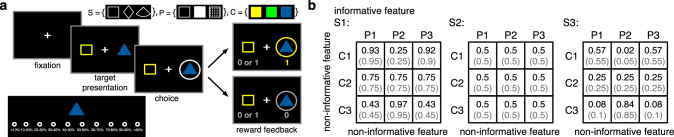
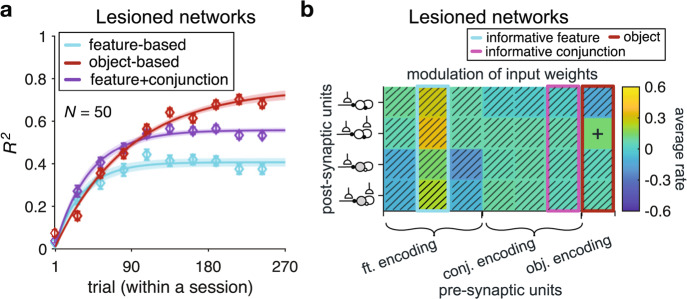
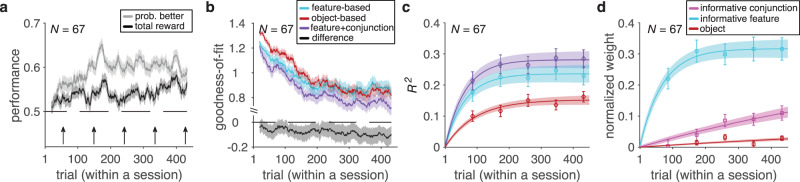
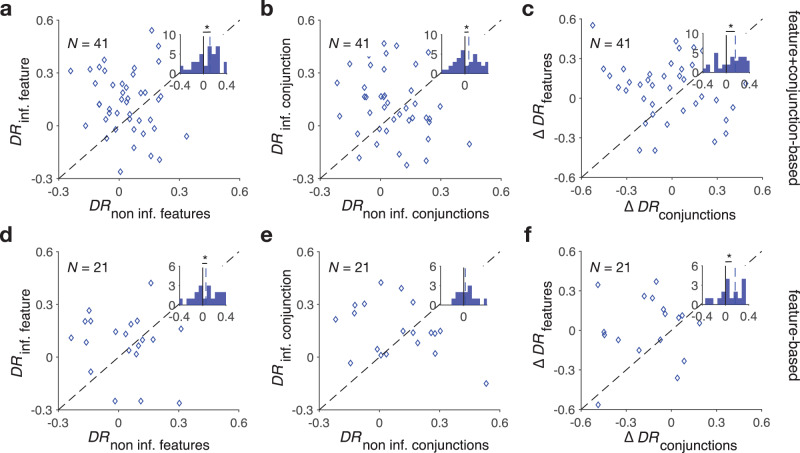
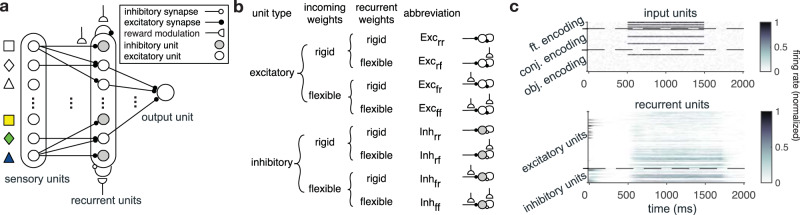
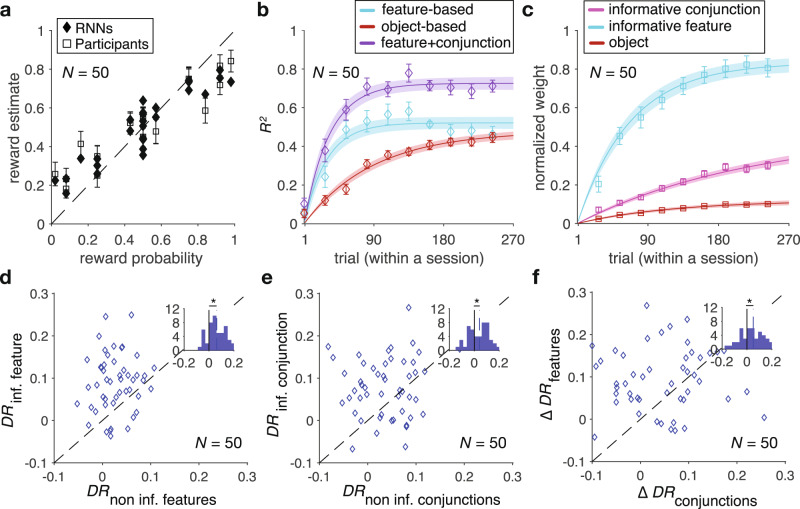
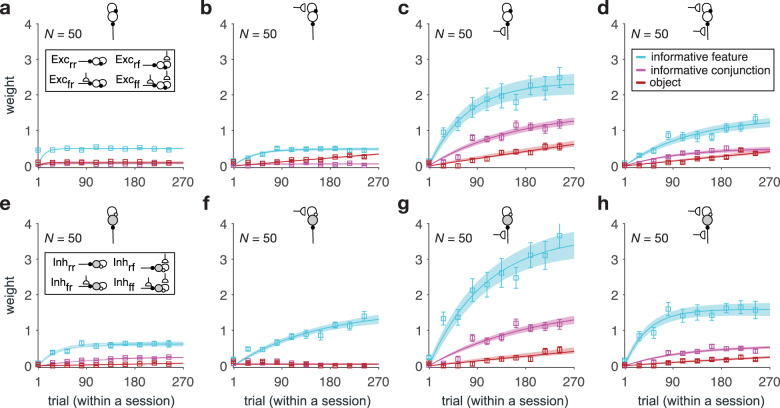
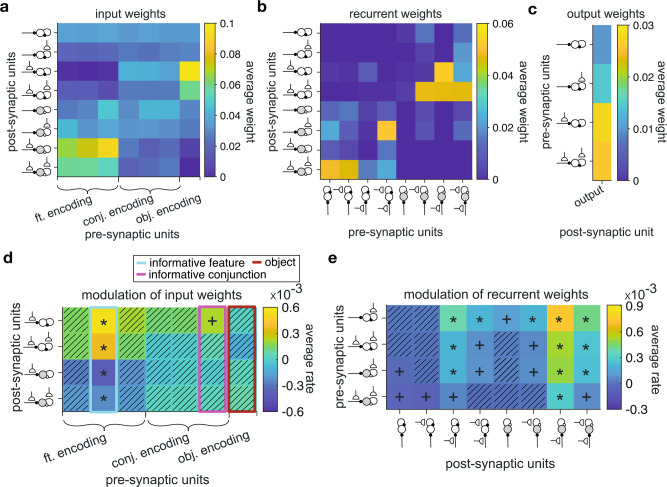
Learning appropriate representations of the reward environment is challenging in the real world where there are many options, each with multiple attributes or features. Despite existence of alternative solutions for this challenge, neural mechanisms underlying emergence and adoption of value representations and learning strategies remain unknown. To address this, we measure learning and choice during a multi-dimensional probabilistic learning task in humans and trained recurrent neural networks (RNNs) to capture our experimental observations. We find that human participants estimate stimulus-outcome associations by learning and combining estimates of reward probabilities associated with the informative feature followed by those of informative conjunctions. Through analyzing representations, connectivity, and lesioning of the RNNs, we demonstrate this mixed learning strategy relies on a distributed neural code and opponency between excitatory and inhibitory neurons through value-dependent disinhibition. Together, our results suggest computational and neural mechanisms underlying emergence of complex learning strategies in naturalistic settings.
在现实世界中,学习奖励环境的适当表示形式具有挑战性,因为存在许多选项,每个选项都具有多个属性或特征。尽管存在针对这一挑战的替代解决方案,但价值表示和学习策略出现和采用的神经机制仍不清楚。为了解决这个问题,我们在人类和经过训练的递归神经网络 (RNN) 中进行了多维概率学习任务,以捕获我们的实验观察结果。我们发现,人类参与者通过学习和组合与信息特征相关的奖励概率估计值,以及与信息组合相关的估计值,来估计刺激-结果关联。通过分析 RNN 的表示、连接和损伤,我们证明这种混合学习策略依赖于分布式神经代码以及兴奋性和抑制性神经元之间的对立,通过价值依赖性去抑制。总的来说,我们的结果表明,在自然环境中出现复杂学习策略的计算和神经机制。