Center for Mathematics and Data Science, Gunma University, Maebashi, Gunma, Japan.
Faculty of Information Engineering, Fukuoka Institute of Technology, Fukuoka, Japan.
PLoS One. 2022 Jan 11;17(1):e0262463. doi: 10.1371/journal.pone.0262463. eCollection 2022.
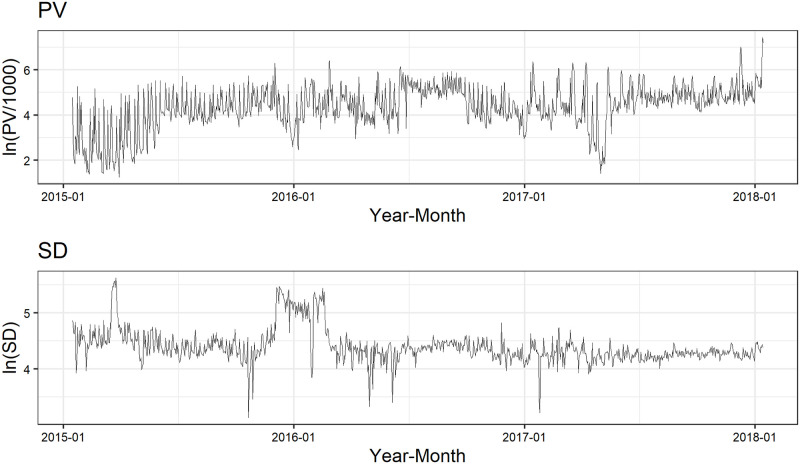
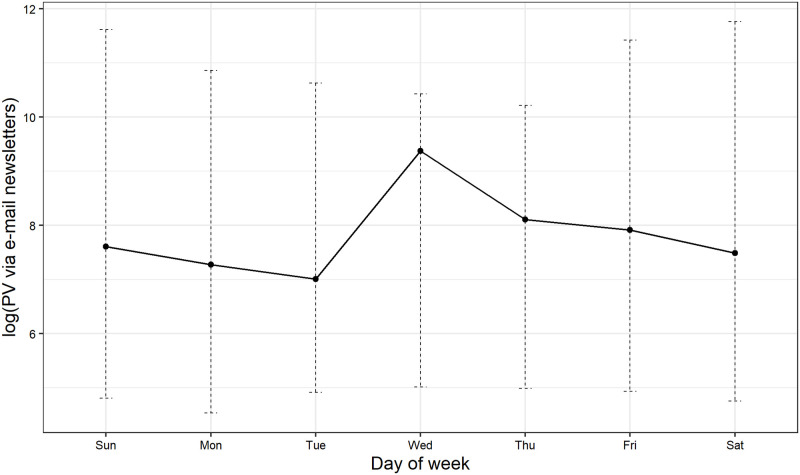
We propose a simple anomaly detection method that is applicable to unlabeled time series data and is sufficiently tractable, even for non-technical entities, by using the density ratio estimation based on the state space model. Our detection rule is based on the ratio of log-likelihoods estimated by the dynamic linear model, i.e. the ratio of log-likelihood in our model to that in an over-dispersed model that we will call the NULL model. Using the Yahoo S5 data set and the Numenta Anomaly Benchmark data set, publicly available and commonly used benchmark data sets, we find that our method achieves better or comparable performance compared to the existing methods. The result implies that it is essential in time series anomaly detection to incorporate the specific information on time series data into the model. In addition, we apply the proposed method to unlabeled Web time series data, specifically, daily page view and average session duration data on an electronic commerce site that deals in insurance goods to show the applicability of our method to unlabeled real-world data. We find that the increase in page view caused by e-mail newsletter deliveries is less likely to contribute to completing an insurance contract. The result also suggests the importance of the simultaneous monitoring of more than one time series.
我们提出了一种简单的异常检测方法,该方法适用于未标记的时间序列数据,并且通过使用基于状态空间模型的密度比估计,即使对于非技术实体也具有足够的可操作性。我们的检测规则基于动态线性模型估计的对数似然比,即我们模型中的对数似然比与我们称之为 NULL 模型的过分散模型中的对数似然比的比值。使用 Yahoo S5 数据集和 Numenta Anomaly Benchmark 数据集,这两个公开可用且常用的基准数据集,我们发现与现有方法相比,我们的方法具有更好或相当的性能。该结果表明,在时间序列异常检测中,将特定于时间序列数据的信息纳入模型是至关重要的。此外,我们将所提出的方法应用于未标记的 Web 时间序列数据,具体来说,是处理保险商品的电子商务网站的每日页面浏览量和平均会话持续时间数据,以展示我们的方法在未标记的真实世界数据中的适用性。我们发现,电子邮件新闻稿投递导致的页面浏览量增加不太可能促成保险合同的完成。该结果还表明了同时监控多个时间序列的重要性。