University Breast Unit, Department of Obstetrics and Gynecology, Heidelberg University Hospital, Im Neuenheimer Feld 440, 69120, Heidelberg, Germany.
MD Anderson Center for INSPiRED Cancer Care (Integrated Systems for Patient-Reported Data), The University of Texas MD Anderson Cancer Center, Houston, TX, USA.
Eur Radiol. 2022 Jun;32(6):4101-4115. doi: 10.1007/s00330-021-08519-z. Epub 2022 Feb 17.
AI-based algorithms for medical image analysis showed comparable performance to human image readers. However, in practice, diagnoses are made using multiple imaging modalities alongside other data sources. We determined the importance of this multi-modal information and compared the diagnostic performance of routine breast cancer diagnosis to breast ultrasound interpretations by humans or AI-based algorithms.
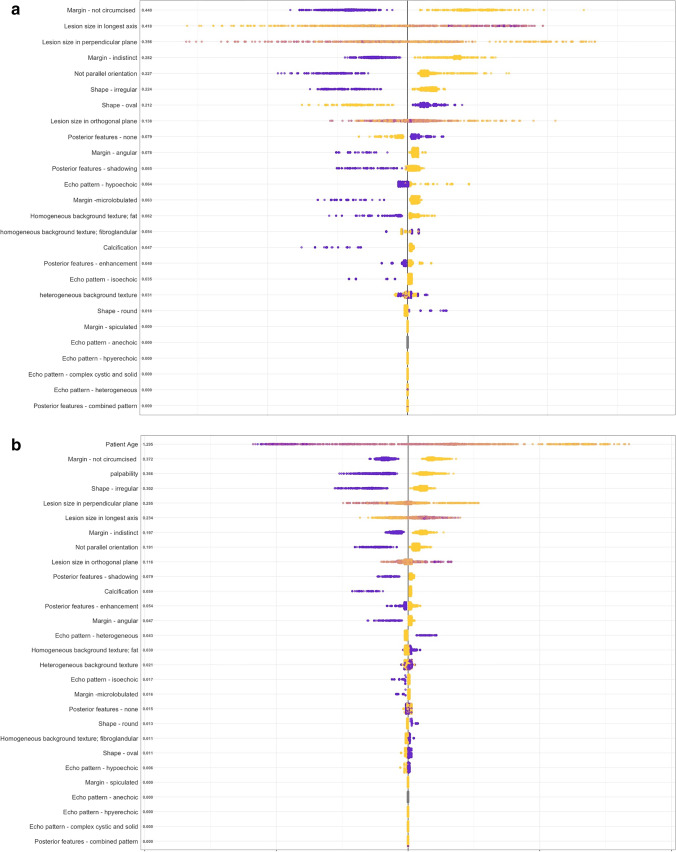
Patients were recruited as part of a multicenter trial (NCT02638935). The trial enrolled 1288 women undergoing routine breast cancer diagnosis (multi-modal imaging, demographic, and clinical information). Three physicians specialized in ultrasound diagnosis performed a second read of all ultrasound images. We used data from 11 of 12 study sites to develop two machine learning (ML) algorithms using unimodal information (ultrasound features generated by the ultrasound experts) to classify breast masses which were validated on the remaining study site. The same ML algorithms were subsequently developed and validated on multi-modal information (clinical and demographic information plus ultrasound features). We assessed performance using area under the curve (AUC).
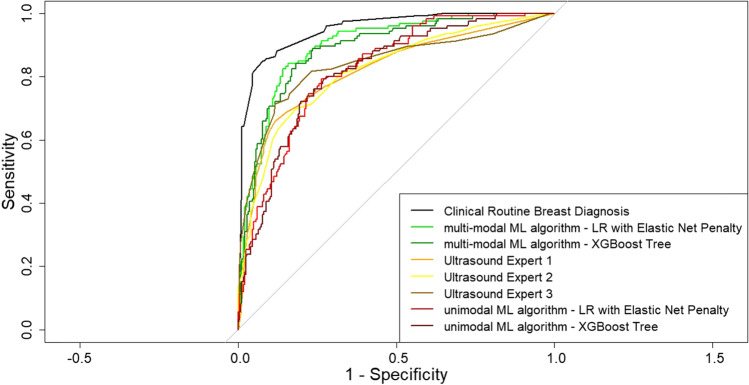
Of 1288 breast masses, 368 (28.6%) were histopathologically malignant. In the external validation set (n = 373), the performance of the two unimodal ultrasound ML algorithms (AUC 0.83 and 0.82) was commensurate with performance of the human ultrasound experts (AUC 0.82 to 0.84; p for all comparisons > 0.05). The multi-modal ultrasound ML algorithms performed significantly better (AUC 0.90 and 0.89) but were statistically inferior to routine breast cancer diagnosis (AUC 0.95, p for all comparisons ≤ 0.05).
The performance of humans and AI-based algorithms improves with multi-modal information.
• The performance of humans and AI-based algorithms improves with multi-modal information. • Multimodal AI-based algorithms do not necessarily outperform expert humans. • Unimodal AI-based algorithms do not represent optimal performance to classify breast masses.
基于人工智能的医学图像分析算法在性能上可与人类图像读者相媲美。然而,在实践中,诊断是使用多种成像方式以及其他数据源进行的。我们确定了这种多模态信息的重要性,并比较了常规乳腺癌诊断与人类或基于人工智能的算法进行的乳腺超声解读的诊断性能。
患者作为多中心试验(NCT02638935)的一部分被招募。该试验纳入了 1288 名接受常规乳腺癌诊断(多模态成像、人口统计学和临床信息)的女性。三位专门从事超声诊断的医生对所有超声图像进行了第二次读取。我们使用来自 12 个研究地点中的 11 个的数据,使用单模态信息(由超声专家生成的超声特征)开发了两种机器学习(ML)算法,对乳腺肿块进行分类,并在其余的研究地点进行验证。随后,我们使用多模态信息(临床和人口统计学信息加超声特征)开发和验证了相同的 ML 算法。我们使用曲线下面积(AUC)评估性能。
在 1288 个乳腺肿块中,有 368 个(28.6%)组织病理学上为恶性。在外部验证集(n=373)中,两种单模态超声 ML 算法(AUC 0.83 和 0.82)的性能与人类超声专家的性能相当(AUC 0.82 至 0.84;所有比较的 p 值均>0.05)。多模态超声 ML 算法的性能显著提高(AUC 0.90 和 0.89),但统计学上不如常规乳腺癌诊断(AUC 0.95,所有比较的 p 值均≤0.05)。
随着多模态信息的增加,人类和基于人工智能的算法的性能会提高。
人类和基于人工智能的算法的性能随着多模态信息的增加而提高。
多模态基于人工智能的算法不一定优于专家人类。
单模态基于人工智能的算法不一定能代表最佳性能来分类乳腺肿块。