Population, Policy and Practice Research and Teaching Programme, University College London Great Ormond Street Institute of Child Health, London, UK.
World Obesity Federation, London, UK.
Pediatr Obes. 2022 Jul;17(7):e12905. doi: 10.1111/ijpo.12905. Epub 2022 Feb 22.
The International Obesity Task Force (IOTF) and World Health Organization (WHO) body mass index (BMI) cut-offs are widely used to assess child overweight, obesity and thinness prevalence, but the two references applied to the same children lead to different prevalence rates.
To develop an algorithm to harmonize prevalence rates based on the IOTF and WHO cut-offs, to make them comparable.
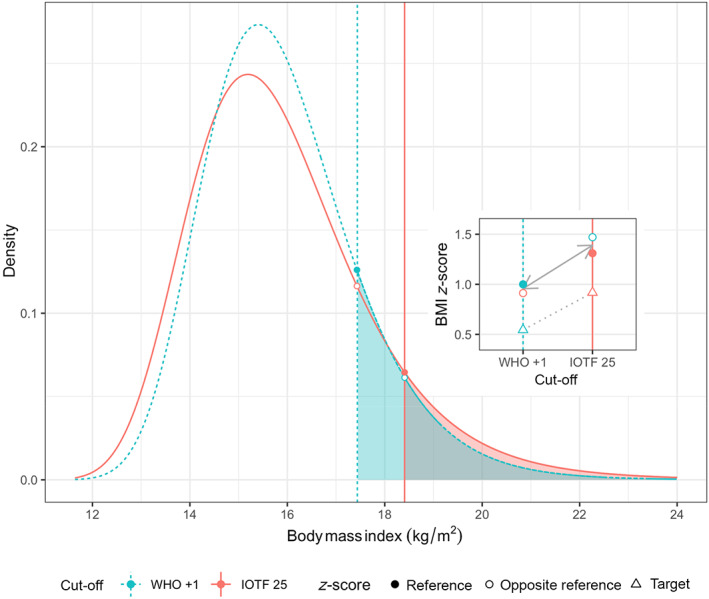
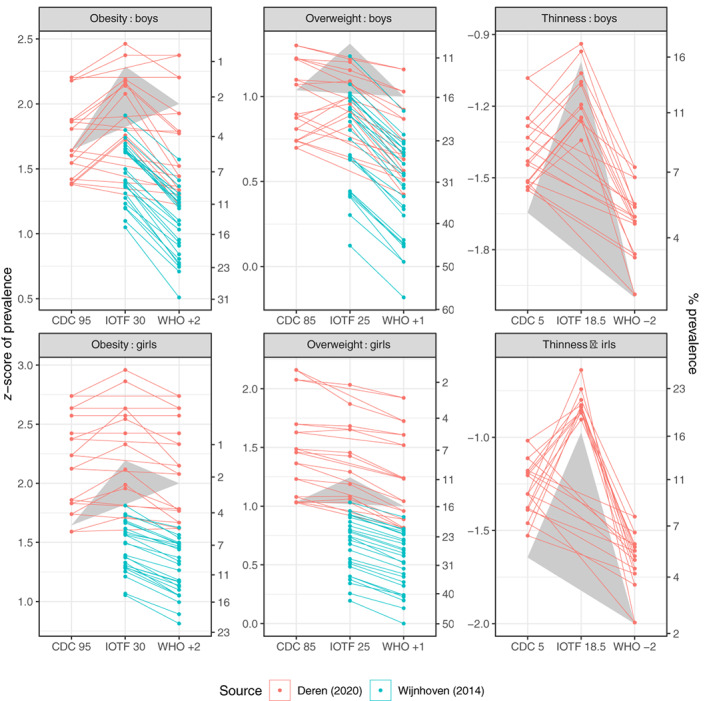
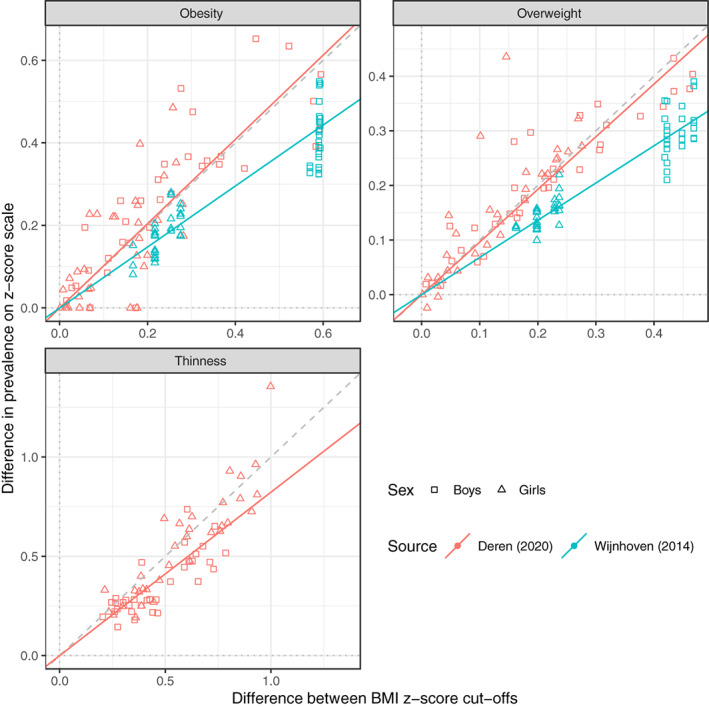
The cut-offs are defined as age-sex-specific BMI z-scores, for example, WHO +1 SD for overweight. To convert an age-sex-specific prevalence rate based on reference cut-off A to the corresponding prevalence based on reference cut-off B, first back-transform the z-score cut-offs and to age-sex-specific BMI cut-offs, then transform the BMIs to z-scores and using the opposite reference. These z-scores together define the distance between the two cut-offs as the z-score difference . Prevalence in the target group based on cut-off A is then transformed to a z-score, adjusted up or down according to and back-transformed, and this predicts prevalence based on cut-off B. The algorithm's performance was tested on 74 groups of children from 14 European countries.
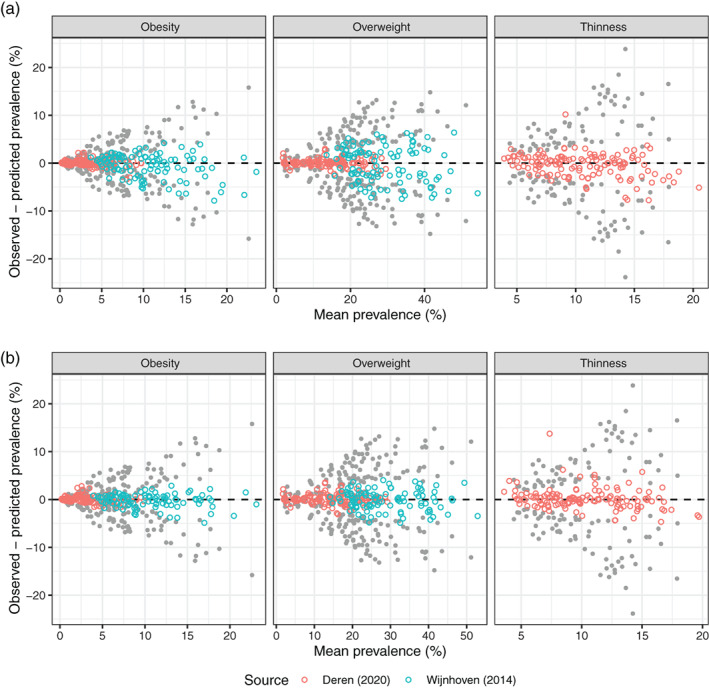
The algorithm performed well. The standard deviation (SD) of the difference between pairs of prevalence rates was 6.6% (n = 604), while the residual SD, the difference between observed and predicted prevalence, was 2.3%, meaning that the algorithm explained 88% of the baseline variance.
The algorithm goes some way to addressing the problem of harmonizing overweight and obesity prevalence rates for children aged 2-18.
国际肥胖特别工作组(IOTF)和世界卫生组织(WHO)的体重指数(BMI)切点被广泛用于评估儿童超重、肥胖和消瘦的流行率,但这两个参考标准应用于同一组儿童会导致不同的流行率。
制定一种算法来协调基于 IOTF 和 WHO 切点的流行率,使它们具有可比性。
切点定义为年龄性别特异性 BMI z 分数,例如 WHO 的+1 SD 为超重。要将基于参考切点 A 的年龄性别特异性流行率转换为基于参考切点 B 的相应流行率,首先将 z 分数切点 和 反向转换为年龄性别特异性 BMI 切点,然后使用相反的参考值将 BMI 转换为 z 分数 和 。这些 z 分数共同定义了两个切点之间的距离,即 z 分数差异 。然后,根据切点 A 预测目标组的流行率,并根据 和 向上或向下调整,再反向转换,从而预测基于切点 B 的流行率。该算法在来自 14 个欧洲国家的 74 组儿童数据上进行了测试。
该算法表现良好。配对流行率之间差异的标准差(SD)为 6.6%(n=604),而残差 SD,即观察到的和预测的流行率之间的差异为 2.3%,这意味着该算法解释了 88%的基线方差。
该算法在一定程度上解决了协调 2-18 岁儿童超重和肥胖流行率的问题。